




























神经网络能否被严谨地解释为符号逻辑?
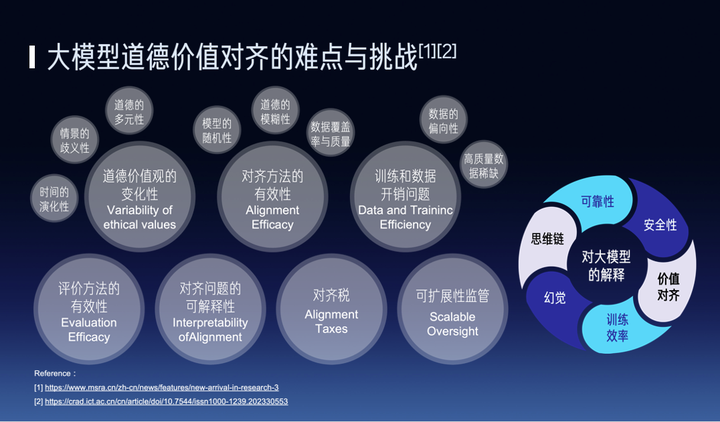
相信大家对“神经网络能否被严谨地解释为符号逻辑”都有自己独特的想法,但是如果究根问底,还是需要一个更加严谨的公理、定理体系来证明或证伪这个命题。准确地说,这里面起码包含两个问题,1.如何定义并数学证明“符号化解释的严谨性”,2.求得“在哪些条件下”神经网络可以被严谨地解释为符号逻辑。下面,是我最近在知乎平台上的一个报告。细节的定理证明需要大家读后面的论文和我的其他知乎文章。各位知乎的朋友们大家好,我是张拳石,我来自上海交通大学。由于身体原因,很遗憾无法前往现场与大家面对面交流。我仍然用心准备了今天的分享,希望能够就可解释性及大模型的未来发展路线,与大家进行深入而有意义的探讨。我是2007、2008年大三的时候第一次接触人工智能研究,当时还没有深度学习,人工智能领域还是以及基于手工设计的特征的图模型为主导的。2012年的深度学习算是一次变革,到了2023年的大模型,我认为很可能是另一个变革。但是,跟大部分人的思考并不相同,我认为新的变革并不会沿袭旧的深度学习发展路径,而且旧路线也逐渐会走向终点。我们看一下2012年之前的基于图模型的人工智能,我将它总结为一个词“穷工极态”。就是说你需要人为地去建模人工智能任务中的方方面面。比如你需要用图中每个节点表示物体的一个组成部分,用图的边来表示不同部分的空间关系,或物体的形变。此外,物体的尺度变化,纹理的变化,角度的变化,光照的变化,林林总总不一而足,你都需要一一去建模。尽管如此,我们发现之前基于图模型的算法的性能还是一直无法提升上来。但是自从2012年,深度学习出现以后,人工智能的发展从一个极端里面走向了另一个极端。特征是神经网络自动学习出来的,这里会出现一个问题,深度学习性能的提升以度让人工智能发展的根本维度作为代价的。你可以说2012年以来人工智能算法出现了大的爆发,每年涌现出多少种不同的神经网络结构,有多少篇论文,但是,我这里是说的是人工智能发展的“根本性的维度”, 就是人们逐渐失去了对神经网络模型的控制。神经网络的表征是端到端自动学习出来的,那么神经网络潜在的问题在哪儿,它的盲点在哪儿,我们是不清楚的。我们逐渐失去了对人工智能模型内在逻辑的解释权和控制权。那么研究的主流就退回到了两个维度,一个是调整神经网络结构,一个是调整神经网络的损失函数,而将“如何学”“学什么”等中间逻辑的学习度让给了神经网络自己。当然,这本不是什么大问题。但是,2023以后,到了大模型时代,情况却截然不同了。对于大模型来说,每一次神经网络的结构调整或者损失函数的调整,都意味着大量的计算资源的开销,大量的时间成本,大量的电力资源。所以,人们逐渐发现,传统的路子走不动了,不在有能力无限制地调结构和调损失函数。假使我们继续沿着传统的模式继续发展,也就是端到端训练的模型一路走下去,现在我们几乎要用全网的数据来训练大模型,然后面对无穷无尽的评测,无穷无尽的价值对齐、监管、安全性、可靠性。从某种意义上讲,我们在工程上已达到了一个极值——但是,这远远不是人工智能发展的终点。那么人工智能发展的希望在哪儿呢?是像人类一样学习。那么人类的学习是什么?1. 从训练来看,是小样本的,是举一反三的。就像教小孩儿,这个一个杯子,我们不需要给小孩儿看一千张瓶子的照片,小孩儿可以从单个样本中学到本质的特点,从而举一反三。2. 测试也不是反复的大样本的考试,而是让人进行“自我陈述”——人脑就是一个神经网络,而人与人工神经网络的重要的区别在于,人是可以自主解释自己的认知,我们是通过将自身的逻辑,转化为符号化的语言表达出来,然后让另一个人了解到,哦,你是真的懂一个事物背后根本的机理,而不是像一个机械式的记忆。人可以做自我陈述,既论迹,更论心——这是一个比端到端测试更加高效的机制,可以用很低的成本赢得彼此的信任,并进行知识的传递。这是一个根本的问题。现在大模型的发展遇到一个安全性的问题、价值对齐的问题、幻觉的问题——目前的这些问题是端到端测试的问题,而不是一个让大模型自我陈述的问题。从根本上,我们缺少一个可靠的理论体系去定义神经网络所建模的概念,严谨地将神经网络内在逻辑表征出来。我们去定义大模型输入单元之间的交互。什么是交互呢?比如,在大语言模型中,输入一个句子,这个句子中不同单词或者token之间的非线性关系叫做一个交互。比如说,英语单词,green hand,green是绿色,hand是手。从单个单词来看,可以翻译为绿色的手,而神经网络建模了两个单词简单的非线性交互,翻译为新手的意思,而不是绿色的手。这一点上,我们需要一些基础理论的突破,即证明,神经网络究竟是否可以被严谨地解释为一些符号化的概念,而且这些符号化的逻辑可以彻底地、干净清楚地将神经网络中绝大部分复杂的决策逻辑,都完全解释出来。在这个方面,我们需要从头构建出一套新的公理、定理体系。我们首先要证明概念的稀疏性。我们在数学上证明了,神经网络的输出在满足在对遮挡操作平滑时,神经网络一定会建模很少量的交互关系。经验上,小模型一般建模100个以内的交互,大模型一般建模300个以内的交互。对于大语言模型来说,这些交互可以是单词间或token间的交互,对于其他数据(比如三维点云)可以是不同点云区域之间的非线性交互。然后,我们要证明第二个性质是无限拟合性。当输入样本中有n个单词或token,我对输入句子中的单词进行随机的遮挡操作,那么我们会得到2^n个不同的遮挡样本。我们可以证明我们可以用这两三百个交互来充分近似估计出神经网络在这2^n指数级不同遮挡样本上的输出值的各种复杂变化。换句话说,我们可以用一个仅有少量个节点的交互图模型去拟合某个特定输入样本下,无限地去拟合神经网络在指数级遮挡样本上各种不同的输出值。我们还发现第三点:交互的泛化性。即,同一个交互在不同的样本之间有很强的泛化性,在面向相同任务所训练的不同神经网络上也有很强的迁移性。那么,从某种意义上,我们是不是就可以认为这些交互相对可靠地表达了神经网络所建模的概念。我们发现两个对话大模型,哪怕有不同的结构,不用数量的参数,甚至不完全一样的训练样本,它们在相同输入句子上所建模的交互,居然是殊途同归的。这是非常反直觉的,不同神经网络有全然不同的结构,不同数量的参数,但是其等效所建模的交互概念却是殊途同归的。那么归根结底,我们的关键是,通过证明交互概念的稀疏性、无限拟合性、通过发现概念的泛化性,来将神经网络预测逻辑解释为交互概念,从而可以直接“数出来”一个神经网络所建模的概念数量,进而在概念表征层面重新定义大模型的泛化性、鲁棒性等等。大模型的幻觉、可靠性、安全性、价值对齐等任务,也可以在大模型“概念层面的自我陈述”的角度,得到全新的评估。感谢大家。很多人说我们的理论特别复杂,建议像其他论文一样给出一目了然的简洁结论,这样容易传播,比如我自己的论文,我自己的引用多而且四处被人提及的文章,往往是工程性的技术,理论上四处漏风,很尴尬——从哪个角度可以证明这个算法一定是唯一的、最优的呢。好多好多人建议我把早年间matlab代码改成python的,这样会有更多引用——拜托,我不愿意跟学界继续玩儿这个拼开源争引用的游戏,明知道一个工程性算法不是终极的结论,为什么在上面浪费时间呢?我们最近的很多研究比较复杂,唉,但这是没有办法的事儿。“神经网络能否被符号化概念严谨的解释”这个问题需要充分严谨地建模和证明,那些一句话的简洁解释一定是漏洞百出的。然而十几年来AI方向已经有些魔怔了,虽然我也相信“大道至简”,但是“最简的未必是大道”,或许大家已经习惯了工程性的实验,潜意识里已经忽略了对“终极”的讨论,放弃了对真理和严谨性的追问了,或许你们默认炼丹的一滩烂泥里已经不可能走出真正的科学定理。 博弈交互解释性理论体系,以及对神经网络符号化解释的数学证明,需要看我前期的知乎文章以及论文。当然,在直觉层面,大家对这个议题都有各式各样的直觉性理解,但是如果究根问底还是需要严格地证明或证伪。Qs.Zhang张拳石:这两年,我究竟做了些什么(2021-2023)Qs.Zhang张拳石:数学证明神经网络中符号化概念涌现的现象Qs.Zhang张拳石:AI从技术到科学:神经网络中的概念符号涌现的发现与证明Qs.Zhang张拳石:可解释性理论系列:反思深度学习,去伪存真、合众归一198 赞同 · 16 评论文章211 赞同 · 17 评论文章220 赞同 · 17 评论文章Qs.Zhang张拳石:敢问深度学习路在何方,从统一12种提升对抗迁移性的算法说起上交大张拳石:深度学习可解释性,从百家争鸣到合众归一mp.weixin.qq.com/s/KXdSwv_ypx1l2AIHrVb-3Amp.weixin.qq.com/s/KXdSwv_ypx1l2AIHrVb-3Amp.weixin.qq.com/s/KXdSwv_ypx1l2AIHrVb-3Amp.weixin.qq.com/s/KXdSwv_ypx1l2AIHrVb-3AQs.Zhang张拳石:ICLR 2022 Oral论文中得分排名前五的高分论文“发现并证明神经网络表征瓶颈”(得分10,8,8,8)923 赞同 · 25 评论文章995 赞同 · 25 评论文章1030 赞同 · 25 评论文章1067 赞同 · 26 评论文章Qs.Zhang张拳石:神经网络的博弈交互解释性(一):前言,漂在零丁洋里的体系268 赞同 · 20 评论文章275 赞同 · 20 评论文章前言,漂在零丁洋里的体系博弈交互概念、定义、定理、推论、与计算动机:建模知识,连接性能背景基础Shapley value双变元博弈交互多变元博弈交互,及其近似计算多阶博弈交互相关定理与推论自然语言交互树博弈交互与知识表达的关探索中低阶博弈交互所建模的视觉概念及泛化能力探索高阶博弈交互所建模的视觉概念神经网络对纹理概念的建模相比形状概念更具有弹性博弈交互与对抗攻击的关系,推导证明与实验证明博弈交互与对抗迁移性的负相关关系证明多个前人迁移性增强算法可近似归纳解释为对博弈交互的抑制交互损失函数与迁移性的增强博弈交互与泛化能力的关系,推导证明与实验探索交互强度与泛化能力的关系证明Dropout对交互强度的抑制交互强度损失函数与泛化能力的提升从博弈交互层面解释对抗鲁棒性对抗攻击在多阶博弈交互上的效用从知识构成的层面探索对抗训练提升鲁棒性的原因去芜存菁:解释并萃取多个前人防御算法中公共的有效机理神经网络对抗迁移性:从神农尝百草到精炼与萃取完善Shapley value理论体系,建模并学习基准值在博弈交互体系内,对“美”提出一个假设性建模可解释性核心——神经网络的知识表达瓶颈博弈交互与神经网络知识表征发现并理论解释神经网络的表达瓶颈突破表达瓶颈及探究不同交互复杂度下的表达能力敢问深度学习路在何方,从统一12种提升对抗迁移性的算法说起神经网络可解释性:正本清源,论统一14种输入重要性归因算法对智能模型中概念涌现的证明数学证明神经网络中符号化概念涌现的现象可解释的哈萨尼网络通过博弈交互 某某某某某某通过博弈交互 某某某某某某 来源:知乎 www.zhihu.com 作者:Qs.Zhang张拳石 【知乎日报】千万用户的选择,做朋友圈里的新鲜事分享大牛。 点击下载 此问题还有 7 个回答,查看全部。 延伸阅读: 符号逻辑对什么有用呢? 为什么符号逻辑学中有两套不同的逻辑符号?

相信大家对“神经网络能否被严谨地解释为符号逻辑”都有自己独特的想法,但是如果究根问底,还是需要一个更加严谨的公理、定理体系来证明或证伪这个命题。准确地说,这里面起码包含两个问题,1.如何定义并数学证明“符号化解释的严谨性”,2.求得“在哪些条件下”神经网络可以被严谨地解释为符号逻辑。
下面,是我最近在知乎平台上的一个报告。细节的定理证明需要大家读后面的论文和我的其他知乎文章。
各位知乎的朋友们大家好,我是张拳石,我来自上海交通大学。由于身体原因,很遗憾无法前往现场与大家面对面交流。我仍然用心准备了今天的分享,希望能够就可解释性及大模型的未来发展路线,与大家进行深入而有意义的探讨。
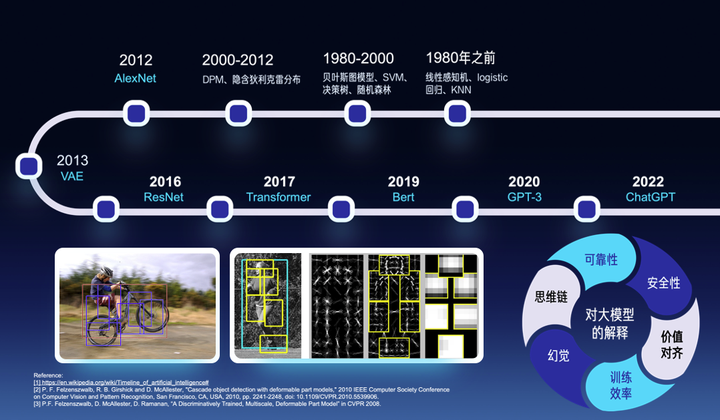
我是2007、2008年大三的时候第一次接触人工智能研究,当时还没有深度学习,人工智能领域还是以及基于手工设计的特征的图模型为主导的。2012年的深度学习算是一次变革,到了2023年的大模型,我认为很可能是另一个变革。但是,跟大部分人的思考并不相同,我认为新的变革并不会沿袭旧的深度学习发展路径,而且旧路线也逐渐会走向终点。我们看一下2012年之前的基于图模型的人工智能,我将它总结为一个词“穷工极态”。就是说你需要人为地去建模人工智能任务中的方方面面。比如你需要用图中每个节点表示物体的一个组成部分,用图的边来表示不同部分的空间关系,或物体的形变。此外,物体的尺度变化,纹理的变化,角度的变化,光照的变化,林林总总不一而足,你都需要一一去建模。尽管如此,我们发现之前基于图模型的算法的性能还是一直无法提升上来。

但是自从2012年,深度学习出现以后,人工智能的发展从一个极端里面走向了另一个极端。特征是神经网络自动学习出来的,这里会出现一个问题,深度学习性能的提升以度让人工智能发展的根本维度作为代价的。你可以说2012年以来人工智能算法出现了大的爆发,每年涌现出多少种不同的神经网络结构,有多少篇论文,但是,我这里是说的是人工智能发展的“根本性的维度”, 就是人们逐渐失去了对神经网络模型的控制。神经网络的表征是端到端自动学习出来的,那么神经网络潜在的问题在哪儿,它的盲点在哪儿,我们是不清楚的。我们逐渐失去了对人工智能模型内在逻辑的解释权和控制权。
那么研究的主流就退回到了两个维度,一个是调整神经网络结构,一个是调整神经网络的损失函数,而将“如何学”“学什么”等中间逻辑的学习度让给了神经网络自己。当然,这本不是什么大问题。但是,2023以后,到了大模型时代,情况却截然不同了。对于大模型来说,每一次神经网络的结构调整或者损失函数的调整,都意味着大量的计算资源的开销,大量的时间成本,大量的电力资源。所以,人们逐渐发现,传统的路子走不动了,不在有能力无限制地调结构和调损失函数。
假使我们继续沿着传统的模式继续发展,也就是端到端训练的模型一路走下去,现在我们几乎要用全网的数据来训练大模型,然后面对无穷无尽的评测,无穷无尽的价值对齐、监管、安全性、可靠性。从某种意义上讲,我们在工程上已达到了一个极值——但是,这远远不是人工智能发展的终点。

那么人工智能发展的希望在哪儿呢?是像人类一样学习。那么人类的学习是什么?1. 从训练来看,是小样本的,是举一反三的。就像教小孩儿,这个一个杯子,我们不需要给小孩儿看一千张瓶子的照片,小孩儿可以从单个样本中学到本质的特点,从而举一反三。2. 测试也不是反复的大样本的考试,而是让人进行“自我陈述”——人脑就是一个神经网络,而人与人工神经网络的重要的区别在于,人是可以自主解释自己的认知,我们是通过将自身的逻辑,转化为符号化的语言表达出来,然后让另一个人了解到,哦,你是真的懂一个事物背后根本的机理,而不是像一个机械式的记忆。人可以做自我陈述,既论迹,更论心——这是一个比端到端测试更加高效的机制,可以用很低的成本赢得彼此的信任,并进行知识的传递。

这是一个根本的问题。现在大模型的发展遇到一个安全性的问题、价值对齐的问题、幻觉的问题——目前的这些问题是端到端测试的问题,而不是一个让大模型自我陈述的问题。从根本上,我们缺少一个可靠的理论体系去定义神经网络所建模的概念,严谨地将神经网络内在逻辑表征出来。我们去定义大模型输入单元之间的交互。什么是交互呢?比如,在大语言模型中,输入一个句子,这个句子中不同单词或者token之间的非线性关系叫做一个交互。比如说,英语单词,green hand,green是绿色,hand是手。从单个单词来看,可以翻译为绿色的手,而神经网络建模了两个单词简单的非线性交互,翻译为新手的意思,而不是绿色的手。
这一点上,我们需要一些基础理论的突破,即证明,神经网络究竟是否可以被严谨地解释为一些符号化的概念,而且这些符号化的逻辑可以彻底地、干净清楚地将神经网络中绝大部分复杂的决策逻辑,都完全解释出来。在这个方面,我们需要从头构建出一套新的公理、定理体系。
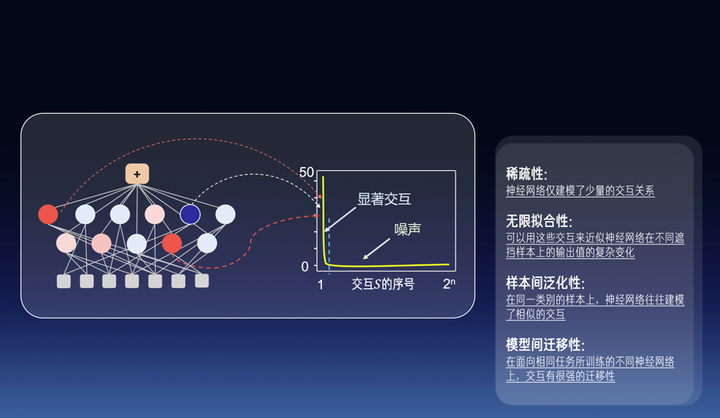
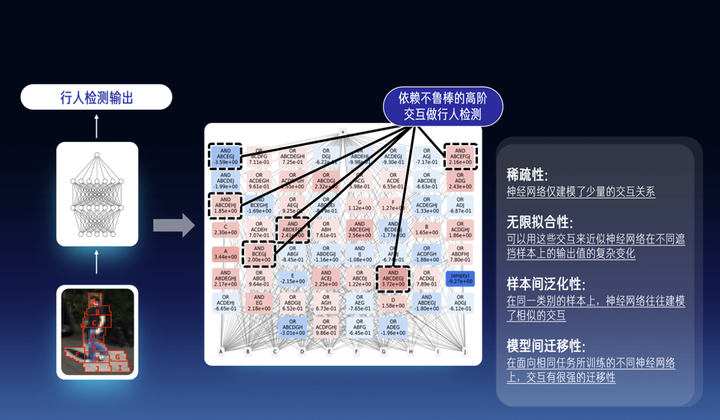
我们首先要证明概念的稀疏性。我们在数学上证明了,神经网络的输出在满足在对遮挡操作平滑时,神经网络一定会建模很少量的交互关系。经验上,小模型一般建模100个以内的交互,大模型一般建模300个以内的交互。对于大语言模型来说,这些交互可以是单词间或token间的交互,对于其他数据(比如三维点云)可以是不同点云区域之间的非线性交互。
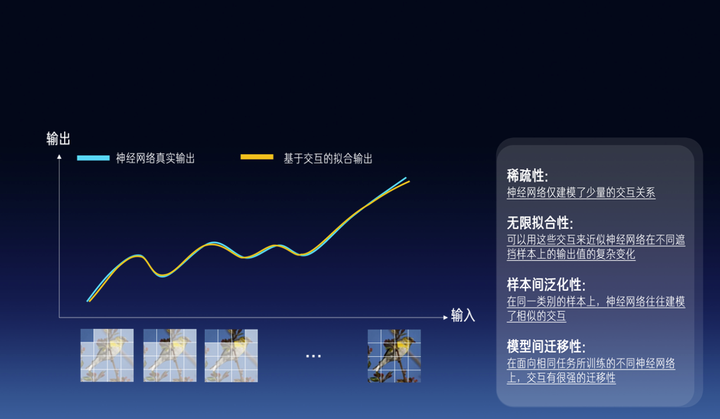
然后,我们要证明第二个性质是无限拟合性。当输入样本中有n个单词或token,我对输入句子中的单词进行随机的遮挡操作,那么我们会得到2^n个不同的遮挡样本。我们可以证明我们可以用这两三百个交互来充分近似估计出神经网络在这2^n指数级不同遮挡样本上的输出值的各种复杂变化。换句话说,我们可以用一个仅有少量个节点的交互图模型去拟合某个特定输入样本下,无限地去拟合神经网络在指数级遮挡样本上各种不同的输出值。
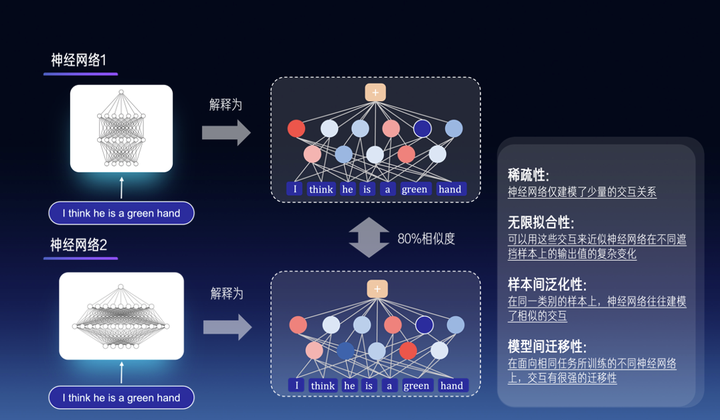
我们还发现第三点:交互的泛化性。即,同一个交互在不同的样本之间有很强的泛化性,在面向相同任务所训练的不同神经网络上也有很强的迁移性。那么,从某种意义上,我们是不是就可以认为这些交互相对可靠地表达了神经网络所建模的概念。我们发现两个对话大模型,哪怕有不同的结构,不用数量的参数,甚至不完全一样的训练样本,它们在相同输入句子上所建模的交互,居然是殊途同归的。这是非常反直觉的,不同神经网络有全然不同的结构,不同数量的参数,但是其等效所建模的交互概念却是殊途同归的。
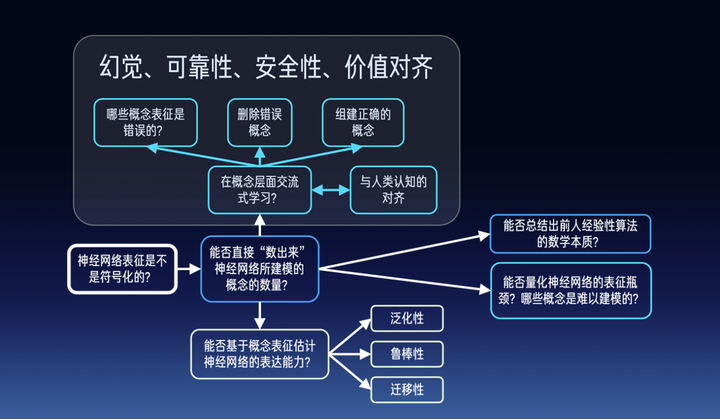
那么归根结底,我们的关键是,通过证明交互概念的稀疏性、无限拟合性、通过发现概念的泛化性,来将神经网络预测逻辑解释为交互概念,从而可以直接“数出来”一个神经网络所建模的概念数量,进而在概念表征层面重新定义大模型的泛化性、鲁棒性等等。大模型的幻觉、可靠性、安全性、价值对齐等任务,也可以在大模型“概念层面的自我陈述”的角度,得到全新的评估。
感谢大家。
很多人说我们的理论特别复杂,建议像其他论文一样给出一目了然的简洁结论,这样容易传播,比如我自己的论文,我自己的引用多而且四处被人提及的文章,往往是工程性的技术,理论上四处漏风,很尴尬——从哪个角度可以证明这个算法一定是唯一的、最优的呢。好多好多人建议我把早年间matlab代码改成python的,这样会有更多引用——拜托,我不愿意跟学界继续玩儿这个拼开源争引用的游戏,明知道一个工程性算法不是终极的结论,为什么在上面浪费时间呢?
我们最近的很多研究比较复杂,唉,但这是没有办法的事儿。“神经网络能否被符号化概念严谨的解释”这个问题需要充分严谨地建模和证明,那些一句话的简洁解释一定是漏洞百出的。然而十几年来AI方向已经有些魔怔了,虽然我也相信“大道至简”,但是“最简的未必是大道”,或许大家已经习惯了工程性的实验,潜意识里已经忽略了对“终极”的讨论,放弃了对真理和严谨性的追问了,或许你们默认炼丹的一滩烂泥里已经不可能走出真正的科学定理。
博弈交互解释性理论体系,以及对神经网络符号化解释的数学证明,需要看我前期的知乎文章以及论文。当然,在直觉层面,大家对这个议题都有各式各样的直觉性理解,但是如果究根问底还是需要严格地证明或证伪。Qs.Zhang张拳石:这两年,我究竟做了些什么(2021-2023)Qs.Zhang张拳石:数学证明神经网络中符号化概念涌现的现象Qs.Zhang张拳石:AI从技术到科学:神经网络中的概念符号涌现的发现与证明Qs.Zhang张拳石:可解释性理论系列:反思深度学习,去伪存真、合众归一198 赞同 · 16 评论文章211 赞同 · 17 评论文章220 赞同 · 17 评论文章Qs.Zhang张拳石:敢问深度学习路在何方,从统一12种提升对抗迁移性的算法说起上交大张拳石:深度学习可解释性,从百家争鸣到合众归一mp.weixin.qq.com/s/KXdSwv_ypx1l2AIHrVb-3Amp.weixin.qq.com/s/KXdSwv_ypx1l2AIHrVb-3Amp.weixin.qq.com/s/KXdSwv_ypx1l2AIHrVb-3Amp.weixin.qq.com/s/KXdSwv_ypx1l2AIHrVb-3AQs.Zhang张拳石:ICLR 2022 Oral论文中得分排名前五的高分论文“发现并证明神经网络表征瓶颈”(得分10,8,8,8)923 赞同 · 25 评论文章995 赞同 · 25 评论文章1030 赞同 · 25 评论文章1067 赞同 · 26 评论文章Qs.Zhang张拳石:神经网络的博弈交互解释性(一):前言,漂在零丁洋里的体系268 赞同 · 20 评论文章275 赞同 · 20 评论文章
- 前言,漂在零丁洋里的体系
- 博弈交互概念、定义、定理、推论、与计算
- 动机:建模知识,连接性能
- 背景基础Shapley value
- 双变元博弈交互
- 多变元博弈交互,及其近似计算
- 多阶博弈交互
- 相关定理与推论
- 自然语言交互树
- 博弈交互与知识表达的关
- 探索中低阶博弈交互所建模的视觉概念及泛化能力
- 探索高阶博弈交互所建模的视觉概念
- 神经网络对纹理概念的建模相比形状概念更具有弹性
- 博弈交互与对抗攻击的关系,推导证明与实验
- 证明博弈交互与对抗迁移性的负相关关系
- 证明多个前人迁移性增强算法可近似归纳解释为对博弈交互的抑制
- 交互损失函数与迁移性的增强
- 博弈交互与泛化能力的关系,推导证明与实验
- 探索交互强度与泛化能力的关系
- 证明Dropout对交互强度的抑制
- 交互强度损失函数与泛化能力的提升
- 从博弈交互层面解释对抗鲁棒性
- 对抗攻击在多阶博弈交互上的效用
- 从知识构成的层面探索对抗训练提升鲁棒性的原因
- 去芜存菁:解释并萃取多个前人防御算法中公共的有效机理
- 神经网络对抗迁移性:从神农尝百草到精炼与萃取
- 完善Shapley value理论体系,建模并学习基准值
- 在博弈交互体系内,对“美”提出一个假设性建模
- 可解释性核心——神经网络的知识表达瓶颈
- 博弈交互与神经网络知识表征
- 发现并理论解释神经网络的表达瓶颈
- 突破表达瓶颈及探究不同交互复杂度下的表达能力
- 敢问深度学习路在何方,从统一12种提升对抗迁移性的算法说起
- 神经网络可解释性:正本清源,论统一14种输入重要性归因算法
- 对智能模型中概念涌现的证明
- 数学证明神经网络中符号化概念涌现的现象
- 可解释的哈萨尼网络
- 通过博弈交互 某某某某某某
- 通过博弈交互 某某某某某某
来源:知乎 www.zhihu.com
作者:Qs.Zhang张拳石
【知乎日报】千万用户的选择,做朋友圈里的新鲜事分享大牛。 点击下载
此问题还有 7 个回答,查看全部。
延伸阅读:
符号逻辑对什么有用呢?
为什么符号逻辑学中有两套不同的逻辑符号?