




























从零开始制作一个属于你自己的GPU | 基于FPGA的图形加速器实现原理
在很多年以前,当我还是一个小毛孩时,电子游戏就已经深深吸引着我,当然在那个时代,这并不算什么特别光荣的事情,因为当时的电子游戏又被称作电子海洛因,有无数的学生因为沉迷于此,因此当他们的考试成绩下降时,游戏无疑成了最好的背锅侠,久而久之就成为了长辈们最痛恨的东西。 不幸的是我就属于家长和老师们口中的坏学生,“电子游戏”实在太令我着迷了,我几乎想尽了一切办法,挤出一点时间偷偷溜出去,好在游戏厅里大快朵颐。 随着时代发展,从电子游戏厅到PC流行起来后的电脑主机游戏,可以说非常幸运,我的游戏生涯的起点,就是游戏作品的辉煌时期,很多的经典游戏像是《合金弹头》《星际争霸》《英雄无敌》《仙剑奇侠传》《大富翁》《流星蝴蝶剑》等等等等,制作精良,玩法新颖,构思巧妙,很多的剧情及背景设定,不亚于一部史诗级小说巨作,每一部作品都足矣令人沉醉其中,即使放在今天,仍然是游戏中的巅峰之作。当我玩过了大多数这些无比优秀的作品后,有的不仅是游戏体验带给我的乐趣,更有对游戏制作者带有无比敬仰的崇拜,从那时开始,自己制作游戏就成为了我人生的梦想之一。 于是在接下来的二十载,我学习涉猎了游戏引擎,图形学,声学,数字信号处理等等多个跨领域学科,在今天,我终于有能力干了一个很久以前我就想干的一件事-----自己动手实现一个RTL级的图形加速器,当然它有一个大家都非常熟悉的名字,就是显卡(也许叫显片更合适),或者叫GPU(Graphics Processing Unit)。 这也是我写下这篇文章的最终目的,比较有意思的是,你可以在互联网上找到非常多的“30天教你自制CPU”的书籍或教程视频,但你很难找到教你制作GPU的文章,商业GPU是一个无比庞大的工程,它需要多个领域的顶尖科研人员多年的努力,但是我们并不需要做的那么复杂,它甚至比实现一个CPU还要简单的多,因此正是基于这样一个简单的目的,我将使用verilog基于FPGA设计一款能够加速我们图形渲染速度的IP核,那么它就是一个名副其实的GPU,尽管这个实现仍然相当的原始,它只有固定的渲染管线,简简单单的几个功能模块,甚至它的工作频率也只有100Mhz左右,但它仍然很好的解决了我们的需求,因此,如果你是图形学及FPGA的入门初学者,文中的内容对你来说应该不会有特别大的阻碍。 因此本文面向的读者,也是希望学习这两个跨领域学科的初学人员,但稍微遗憾的是,尽管实现的内容原理比较简单,却并不意味着能够将它做出来同样的简单,为此你需要拥有C语言及verilog的编程语言基础,拥有计算机组成原理、图形学、数字电路处理、通信原理、FPGA设计的基础理论功底,最好已经使用上层语言自己写过软渲染器,事实上在这个年代,我们很容易找到编程语言、图形学、FPGA设计领域的专家,但跨领域的人确实并不好找,因此在多数的企业中,PS(processing system或者理解为CPU端)和PL(Progarmmable Logic或者理解为我们编程的GPU端)常常是不同人员分开设计的,而这也是我认为一个科研人员所应该具备的,当你将目光拓展到不同的领域,你将在自己的领域中拥有到全新不同的理解方式,在《七龙珠》中有一个叫合体的概念,合体后的战斗力不是相加而是相乘,大概就是这样一种感觉........ 而在本文中,我将叙述GPU模块中各个内容的实现原理(但也许并不会对每一行代码做出详细的解析),通过本文,你将了解到:上层C语言层面的软渲染器实现。上层渲染器的运算瓶颈问题,为什么使用FPGA可以为CPU实现图形加速。Zynq7020 Soc的基础架构,我们的GPU架构模式实现AXI总线,完成CPU-GPU之间的数据交互FIFO,GPU Info,Memcpy两个模块的工作原理调用VDMA IP核,实现双缓存Framebuffer,编写驱动实现HDMI输出到屏幕实现Render模块的第一部分,完成颜色纹理的AlphaBlend实现Render模块的第二部分,完成三角图元的光栅化渲染编写GPU驱动,软硬结合渲染图元、模型、实现一个粒子系统。 当然,文中的内容依然基于PainterEngine,你可以在github或者PainterEngine的官网上下载到这个库,这个GPU也将在Zynq7020上的standalone的裸环境上运行,鉴于Zynq的开发板本身不便宜,鉴于PainterEngine良好的跨平台及结果一致性原则,你也可以在PC上使用非GPU加速的渲染结果,如果你只是想尝鲜及“大致了解下”怎么回事,这也挺不错。当然你也可以将本项目作为你的毕业设计,弄个优秀应该绰绰有余。开发环境搭建 我将开发环境分为以下几个部分,其中有一些部分是必选的,有一部分是可选的,当然也包括对应的硬件平台。 其中软件平台主要包含C语言开发及编译环境Visual Studio 2022(可选)Visual Studio Code + MingW(可选)Vitis(必选)Vivado(必选)硬件平台是xc7z020clg484-1的开发板,理论上zynq7000系列的soc开发板都可以,一般情况下这个系列的开发板板载几乎都有256MB以上的DDR内存,并且带有一个HDMI输出口。为了方便我建议选购板载烧录器的开发板,这样你只需要插上type-c接口,就可以使用了。如何安装上述的软件和如何购买相关的开发板,在这里我就不再多花笔墨了,相信大家都能搞定,下面我将以简短的篇幅来做PainterEngine的编译教程(以比较省事的Visual Studio Code+MingW为例)假设你已经安装好了Visual Studio Code和MingW,在命令行中输入gcc -v,应该能够显示以下的内容:然后你需要前往PainterEngine的官网,下载到整个PainterEngine的源码包 在解压出对应文件夹以后,请在系统变量中,以PainterEnginePath作为变量名,设置PainterEngine所在的路径 打开visual studio code,打开PainterEngine/platform/fpga_gpu/simulator然后你可以点击运行,最后点击PainterEngine Debug在短暂的编译后,你将能在PC上看到我们软件运行的最终结果(当然,这里我们并没有加入GPU的支持,所有的渲染都是软件实现的)软渲染实现在上一章节中(如果你成功运行的话),你将会看到程序在3个场景中运行,第一个场景绘制了一个旋转的三角形它是我们GPU中最为基础的图元渲染,也就是一个三角形的光栅化,这是现代渲染器3D场景中非常基础的一部分,3D场景渲染,由图元到片元,片元到模型,模型到场景,如果你查看该函数的视线,你将会看到下面的代码px_void PX_GeoRasterizeTriangle(px_surface* psurface, px_int x1, px_int y1, px_int x2, px_int y2, px_int x3, px_int y3, px_color color)其中- psurface:指向目标绘制表面的指针。- x1, y1, x2, y2, x3, y3:三角形三个顶点的坐标。- color:用于填充三角形的颜色。1. 计算三角形的边界框: px_int minX = (x1 < x2) ? ((x1 < x3) ? x1 : x3) : ((x2 < x3) ? x2 : x3); px_int maxX = (x1 > x2) ? ((x1 > x3) ? x1 : x3) : ((x2 > x3) ? x2 : x3); px_int minY = (y1 < y2) ? ((y1 < y3) ? y1 : y3) : ((y2 < y3) ? y2 : y3); px_int maxY = (y1 > y2) ? ((y1 > y3) ? y1 : y3) : ((y2 > y3) ? y2 : y3); 通过比较三个顶点的坐标,找到三角形的最小和最大 `x`,`y` 值,这样就得到了一个包围三角形的矩形框。2. 将顶点坐标转换到包围框的坐标系中: gpu_x1 = x1 - minX; gpu_y1 = y1 - minY; gpu_x2 = x2 - minX; gpu_y2 = y2 - minY; gpu_x3 = x3 - minX; gpu_y3 = y3 - minY; 这样做是为了方便在后续的操作中使用局部坐标进行计算。3. 检查并修正边界: if (minX < 0) minX = 0; if (minX >= psurface->width) return; if (maxX < 0) return; if (maxX >= psurface->width) maxX = psurface->width - 1; if (minY < 0) minY = 0; if (minY >= psurface->height) return; if (maxY < 0) return; if (maxY >= psurface->height) maxY = psurface->height - 1; 这些检查确保了包围框在目标表面的有效区域内。如果包围框完全不在表面区域内,函数直接返回。4. 判断并执行光栅化: - `PX_GPU_ENABLE` 宏:如果定义了这个宏,将调用 GPU 的三角形光栅化功能。 #ifdef PX_GPU_ENABLE ... #endif - 软件光栅化:遍历包围框内的所有像素点,使用重心法判断该像素是否在三角形内。如果在三角形内,就将该像素设置为指定颜色。 for (y = minY; y = 0 && area3 >= 0) || (area1 width, PX_COLOR_FORMAT, blend); } else { for (j = 0; j < cliph; j++) { for (i = 0; i < clipw; i++) { clr = pdata[(clipy + j) * tex->width + (clipx + i)]; bA = (px_int)(clr._argb.a * Ab) >> 7; bR = (px_int)(clr._argb.r * Rb) >> 7; bG = (px_int)(clr._argb.g * Gb) >> 7; bB = (px_int)(clr._argb.b * Bb) >> 7; clr._argb.a = (px_uchar)bA; clr._argb.r = (px_uchar)bR; clr._argb.g = (px_uchar)bG; clr._argb.b = (px_uchar)bB; PX_SurfaceDrawPixelWithoutLimit(psurface, x + i, y + j, clr); } } } #else for (j = 0; j < cliph; j++) { for (i = 0; i < clipw; i++) { clr = pdata[(clipy + j) * tex->width + (clipx + i)]; bA = (px_int)(clr._argb.a * Ab) >> 7; bR = (px_int)(clr._argb.r * Rb) >> 7; bG = (px_int)(clr._argb.g * Gb) >> 7; bB = (px_int)(clr._argb.b * Bb) >> 7; clr._argb.a = (px_uchar)bA; clr._argb.r = (px_uchar)bR; clr._argb
在很多年以前,当我还是一个小毛孩时,电子游戏就已经深深吸引着我,当然在那个时代,这并不算什么特别光荣的事情,因为当时的电子游戏又被称作电子海洛因,有无数的学生因为沉迷于此,因此当他们的考试成绩下降时,游戏无疑成了最好的背锅侠,久而久之就成为了长辈们最痛恨的东西。
不幸的是我就属于家长和老师们口中的坏学生,“电子游戏”实在太令我着迷了,我几乎想尽了一切办法,挤出一点时间偷偷溜出去,好在游戏厅里大快朵颐。
随着时代发展,从电子游戏厅到PC流行起来后的电脑主机游戏,可以说非常幸运,我的游戏生涯的起点,就是游戏作品的辉煌时期,很多的经典游戏像是《合金弹头》《星际争霸》《英雄无敌》《仙剑奇侠传》《大富翁》《流星蝴蝶剑》等等等等,制作精良,玩法新颖,构思巧妙,很多的剧情及背景设定,不亚于一部史诗级小说巨作,每一部作品都足矣令人沉醉其中,即使放在今天,仍然是游戏中的巅峰之作。当我玩过了大多数这些无比优秀的作品后,有的不仅是游戏体验带给我的乐趣,更有对游戏制作者带有无比敬仰的崇拜,从那时开始,自己制作游戏就成为了我人生的梦想之一。
于是在接下来的二十载,我学习涉猎了游戏引擎,图形学,声学,数字信号处理等等多个跨领域学科,在今天,我终于有能力干了一个很久以前我就想干的一件事-----自己动手实现一个RTL级的图形加速器,当然它有一个大家都非常熟悉的名字,就是显卡(也许叫显片更合适),或者叫GPU(Graphics Processing Unit)。
这也是我写下这篇文章的最终目的,比较有意思的是,你可以在互联网上找到非常多的“30天教你自制CPU”的书籍或教程视频,但你很难找到教你制作GPU的文章,商业GPU是一个无比庞大的工程,它需要多个领域的顶尖科研人员多年的努力,但是我们并不需要做的那么复杂,它甚至比实现一个CPU还要简单的多,因此正是基于这样一个简单的目的,我将使用verilog基于FPGA设计一款能够加速我们图形渲染速度的IP核,那么它就是一个名副其实的GPU,尽管这个实现仍然相当的原始,它只有固定的渲染管线,简简单单的几个功能模块,甚至它的工作频率也只有100Mhz左右,但它仍然很好的解决了我们的需求,因此,如果你是图形学及FPGA的入门初学者,文中的内容对你来说应该不会有特别大的阻碍。
因此本文面向的读者,也是希望学习这两个跨领域学科的初学人员,但稍微遗憾的是,尽管实现的内容原理比较简单,却并不意味着能够将它做出来同样的简单,为此你需要拥有C语言及verilog的编程语言基础,拥有计算机组成原理、图形学、数字电路处理、通信原理、FPGA设计的基础理论功底,最好已经使用上层语言自己写过软渲染器,事实上在这个年代,我们很容易找到编程语言、图形学、FPGA设计领域的专家,但跨领域的人确实并不好找,因此在多数的企业中,PS(processing system或者理解为CPU端)和PL(Progarmmable Logic或者理解为我们编程的GPU端)常常是不同人员分开设计的,而这也是我认为一个科研人员所应该具备的,当你将目光拓展到不同的领域,你将在自己的领域中拥有到全新不同的理解方式,在《七龙珠》中有一个叫合体的概念,合体后的战斗力不是相加而是相乘,大概就是这样一种感觉........
而在本文中,我将叙述GPU模块中各个内容的实现原理(但也许并不会对每一行代码做出详细的解析),通过本文,你将了解到:
- 上层C语言层面的软渲染器实现。
- 上层渲染器的运算瓶颈问题,为什么使用FPGA可以为CPU实现图形加速。
- Zynq7020 Soc的基础架构,我们的GPU架构模式
- 实现AXI总线,完成CPU-GPU之间的数据交互
- FIFO,GPU Info,Memcpy两个模块的工作原理
- 调用VDMA IP核,实现双缓存Framebuffer,编写驱动实现HDMI输出到屏幕
- 实现Render模块的第一部分,完成颜色纹理的AlphaBlend
- 实现Render模块的第二部分,完成三角图元的光栅化渲染
- 编写GPU驱动,软硬结合渲染图元、模型、实现一个粒子系统。
当然,文中的内容依然基于PainterEngine,你可以在github或者PainterEngine的官网上下载到这个库,这个GPU也将在Zynq7020上的standalone的裸环境上运行,鉴于Zynq的开发板本身不便宜,鉴于PainterEngine良好的跨平台及结果一致性原则,你也可以在PC上使用非GPU加速的渲染结果,如果你只是想尝鲜及“大致了解下”怎么回事,这也挺不错。当然你也可以将本项目作为你的毕业设计,弄个优秀应该绰绰有余。
开发环境搭建
我将开发环境分为以下几个部分,其中有一些部分是必选的,有一部分是可选的,当然也包括对应的硬件平台。
其中软件平台主要包含C语言开发及编译环境
- Visual Studio 2022(可选)
- Visual Studio Code + MingW(可选)
- Vitis(必选)
- Vivado(必选)
硬件平台是xc7z020clg484-1的开发板,理论上zynq7000系列的soc开发板都可以,一般情况下这个系列的开发板板载几乎都有256MB以上的DDR内存,并且带有一个HDMI输出口。为了方便我建议选购板载烧录器的开发板,这样你只需要插上type-c接口,就可以使用了。
如何安装上述的软件和如何购买相关的开发板,在这里我就不再多花笔墨了,相信大家都能搞定,下面我将以简短的篇幅来做PainterEngine的编译教程(以比较省事的Visual Studio Code+MingW为例)
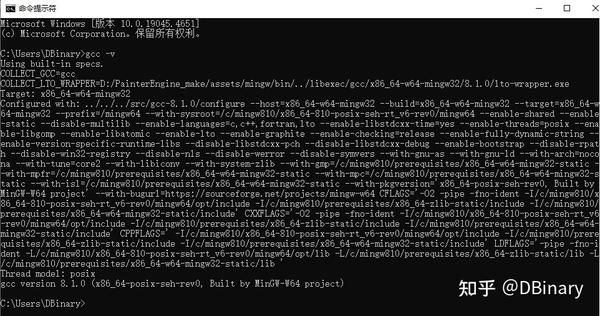
假设你已经安装好了Visual Studio Code和MingW,在命令行中输入gcc -v,应该能够显示以下的内容:
然后你需要前往PainterEngine的官网,下载到整个PainterEngine的源码包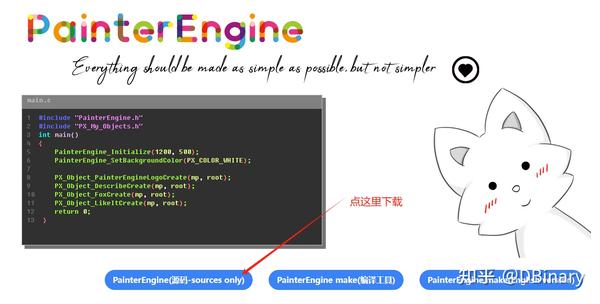
在解压出对应文件夹以后,请在系统变量中,以PainterEnginePath作为变量名,设置PainterEngine所在的路径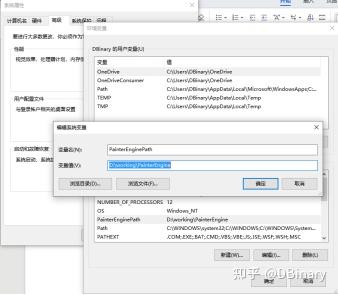
打开visual studio code,打开PainterEngine/platform/fpga_gpu/simulator
然后你可以点击运行,最后点击PainterEngine Debug
在短暂的编译后,你将能在PC上看到我们软件运行的最终结果(当然,这里我们并没有加入GPU的支持,所有的渲染都是软件实现的)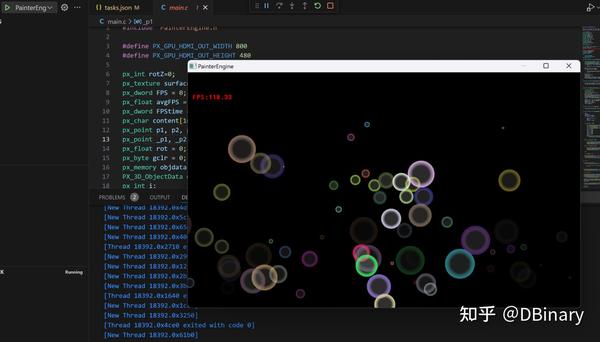
软渲染实现
在上一章节中(如果你成功运行的话),你将会看到程序在3个场景中运行,第一个场景绘制了一个旋转的三角形
它是我们GPU中最为基础的图元渲染,也就是一个三角形的光栅化,这是现代渲染器3D场景中非常基础的一部分,3D场景渲染,由图元到片元,片元到模型,模型到场景,如果你查看该函数的视线,你将会看到下面的代码
px_void PX_GeoRasterizeTriangle(px_surface* psurface, px_int x1, px_int y1, px_int x2, px_int y2, px_int x3, px_int y3, px_color color)其中
- psurface:指向目标绘制表面的指针。
- x1, y1, x2, y2, x3, y3:三角形三个顶点的坐标。
- color:用于填充三角形的颜色。
1. 计算三角形的边界框:
px_int minX = (x1 < x2) ? ((x1 < x3) ? x1 : x3) : ((x2 < x3) ? x2 : x3);
px_int maxX = (x1 > x2) ? ((x1 > x3) ? x1 : x3) : ((x2 > x3) ? x2 : x3);
px_int minY = (y1 < y2) ? ((y1 < y3) ? y1 : y3) : ((y2 < y3) ? y2 : y3);
px_int maxY = (y1 > y2) ? ((y1 > y3) ? y1 : y3) : ((y2 > y3) ? y2 : y3);通过比较三个顶点的坐标,找到三角形的最小和最大 `x`,`y` 值,这样就得到了一个包围三角形的矩形框。
2. 将顶点坐标转换到包围框的坐标系中:
gpu_x1 = x1 - minX;
gpu_y1 = y1 - minY;
gpu_x2 = x2 - minX;
gpu_y2 = y2 - minY;
gpu_x3 = x3 - minX;
gpu_y3 = y3 - minY;这样做是为了方便在后续的操作中使用局部坐标进行计算。
3. 检查并修正边界:
if (minX < 0) minX = 0;
if (minX >= psurface->width) return;
if (maxX < 0) return;
if (maxX >= psurface->width) maxX = psurface->width - 1;
if (minY < 0) minY = 0;
if (minY >= psurface->height) return;
if (maxY < 0) return;
if (maxY >= psurface->height) maxY = psurface->height - 1;这些检查确保了包围框在目标表面的有效区域内。如果包围框完全不在表面区域内,函数直接返回。
4. 判断并执行光栅化:
- `PX_GPU_ENABLE` 宏:如果定义了这个宏,将调用 GPU 的三角形光栅化功能。
#ifdef PX_GPU_ENABLE
...
#endif- 软件光栅化:遍历包围框内的所有像素点,使用重心法判断该像素是否在三角形内。如果在三角形内,就将该像素设置为指定颜色。
for (y = minY; y <= maxY; y++)
for (x = minX; x <= maxX; x++)
{
px_int area1 = (x2 - x1) * (y - y1) - (y2 - y1) * (x - x1);
px_int area2 = (x3 - x2) * (y - y2) - (y3 - y2) * (x - x2);
px_int area3 = (x1 - x3) * (y - y3) - (y1 - y3) * (x - x3);
if ((area1 >= 0 && area2 >= 0 && area3 >= 0) || (area1 <= 0 && area2 <= 0 && area3 <= 0))
{
PX_SurfaceDrawPixel(psurface,x, y, color);
}
}这段代码首先确定了三角形的包围框,然后在包围框内的每个像素点上使用重心法判断是否位于三角形内,并对其进行着色。如果使用了 GPU 加速,则可以直接调用 GPU 进行光栅化处理,从而提高绘制效率,当然到目前为止,我们暂时没有使用GPU进行加速绘制,但如果我们开启GPU绘制,其渲染结果也是完全一致的.
在第二个场景中你将会看到粒子系统的运行结果
如果你跟踪其实现,你将会最终来到下面的代码中
#ifdef PX_GPU_ENABLE
if (PX_GPU_isEnable()&& clipw>=32)
{
px_dword blend;
Ab &= 0xff;
Rb &= 0xff;
Gb &= 0xff;
Bb &= 0xff;
blend = (Ab << 24) + (Rb << 16) + (Gb << 8) + Bb;
PX_GPU_Render(pdata + clipy * tex->width + clipx, tex->width, clipw, cliph, psurface->surfaceBuffer + y * psurface->width + x, psurface->width, PX_COLOR_FORMAT, blend);
}
else
{
for (j = 0; j < cliph; j++)
{
for (i = 0; i < clipw; i++)
{
clr = pdata[(clipy + j) * tex->width + (clipx + i)];
bA = (px_int)(clr._argb.a * Ab) >> 7;
bR = (px_int)(clr._argb.r * Rb) >> 7;
bG = (px_int)(clr._argb.g * Gb) >> 7;
bB = (px_int)(clr._argb.b * Bb) >> 7;
clr._argb.a = (px_uchar)bA;
clr._argb.r = (px_uchar)bR;
clr._argb.g = (px_uchar)bG;
clr._argb.b = (px_uchar)bB;
PX_SurfaceDrawPixelWithoutLimit(psurface, x + i, y + j, clr);
}
}
}
#else
for (j = 0; j < cliph; j++)
{
for (i = 0; i < clipw; i++)
{
clr = pdata[(clipy + j) * tex->width + (clipx + i)];
bA = (px_int)(clr._argb.a * Ab) >> 7;
bR = (px_int)(clr._argb.r * Rb) >> 7;
bG = (px_int)(clr._argb.g * Gb) >> 7;
bB = (px_int)(clr._argb.b * Bb) >> 7;
clr._argb.a = (px_uchar)bA;
clr._argb.r = (px_uchar)bR;
clr._argb.g = (px_uchar)bG;
clr._argb.b = (px_uchar)bB;
PX_SurfaceDrawPixelWithoutLimit(psurface, x + i, y + j, clr);
}
}
#endif可以看到,在如果PX_GPU_ENABLE的宏是定义状态,这个函数将会把纹理信息传递给GPU,并让GPU进行渲染,如果没有(我们当前的情况),我们将使用软渲染完成Texture的AlphaBlender,如你所见这是两个大循环。
在最后,你将会看到PainterEngine渲染一个3D模型(斯坦福兔子)
你可以明显的看到这个3D模型是由一个一个的图元组成而来,同样的,当你跟踪代码,你最终会找到下面的内容
if (!(pface->state&PX_3D_FACESTATE_BACKFACE||pface->state&PX_3D_FACESTATE_CLIPPED))
{
//render by GPU Mode
if (list->PX_3D_PRESENTMODE&PX_3D_PRESENTMODE_PURE)
{
px_int x0, y0, x1, y1, x2, y2;
px_float alpha;
px_float cosv = PX_Point4DDot(PX_Point4DUnit(pface->transform_vertex[0].normal), PX_POINT4D(0, 0, 1));
x0 = (px_int)pface->transform_vertex[0].position.x;
y0 = (px_int)pface->transform_vertex[0].position.y;
x1 = (px_int)pface->transform_vertex[1].position.x;
y1 = (px_int)pface->transform_vertex[1].position.y;
x2 = (px_int)pface->transform_vertex[2].position.x;
y2 = (px_int)pface->transform_vertex[2].position.y;
cosv = -cosv;
if (cosv > 0)
{
alpha = (1 - cosv) * 128;
PX_GeoRasterizeTriangle(psurface, x0, y0, x1, y1, x2, y2, PX_COLOR(255, (px_uchar)(128 + alpha), (px_uchar)(128 + alpha), (px_uchar)(128 + alpha)));
}
}
/*
if (list->PX_3D_PRESENTMODE&PX_3D_PRESENTMODE_PURE)
{
PX_3D_RenderListRasterization(psurface,list,pface->transform_vertex[0],pface->transform_vertex[1],pface->transform_vertex[2],list->ptexture,clr,(px_int)camera->viewport_width,(px_int)camera->viewport_height,camera->zbuffer,(px_int)camera->viewport_width);
}
else
{
PX_3D_RenderListRasterization(psurface,list,pface->transform_vertex[0],pface->transform_vertex[1],pface->transform_vertex[2],ptex,PX_COLOR(0,0,0,0),(px_int)camera->viewport_width,(px_int)camera->viewport_height,camera->zbuffer,(px_int)camera->viewport_width);
}
*/
}在上面的函数中,我们最终调用了一开始就提到的PX_GeoRasterizeTriangle函数,但3D的顶点运算投影变换等内容,是在CPU端完成的,我们的GPU仅是简单完成了片元渲染,实际上如果我们将顶点变换的矩阵运算也放在GPU中完成也并不是什么困难的事情,但是这里我投了一个懒,因为顶点数量并不算多,因此将这部分由CPU来算,并不会在运算速度上较GPU有什么劣势,毕竟我们的CPU拥有完成的浮点运算单元,并且工作频率是GPU的8倍。
因此,如果仅仅从功能结果上来看,我们的GPU和CPU的最终结果都是一摸一样的,我们使用GPU单元,最主要的目的仍然是加速这个运算的过程。
但在这个章节结束之前,我想先抛出一个问题。
图元(三角形)的光栅化渲染
三角形光栅化算法有多种不同的方法,常见的有以下几种:
1. 扫描线算法 (Scanline Rasterization)原理:扫描线算法通过逐行扫描的方式处理图像,从顶部到底部依次计算出每条扫描线与三角形的交点,进而填充扫描线上的像素。
2. 重心坐标法 (Barycentric Coordinates)原理:对于三角形内的任意一点,可以用三个顶点的重心坐标表示。通过判断某个像素的重心坐标是否都在 [0,1] 范围内,可以确定该像素是否在三角形内。
3. 边缘函数法 (Edge Function)原理:利用边缘函数(通过顶点坐标构造的线性函数)来判断某个像素点相对于三角形边的相对位置。对于每个像素,如果它在三条边的“内侧”,则该像素在三角形内。
4. 分治法 (Divide-and-Conquer)原理:将三角形递归地分割成更小的三角形,直到每个三角形可以直接光栅化。这种方法通常与其他算法结合使用,例如与扫描线算法结合。
其中扫描线和重心坐标法是硬件实现的常用算法,我在这里抛出一个问题留给读着思考,本文中使用的是重心坐标法,那么为什么呢,相对于扫描线法(你可以查阅PainterEngine PX_GeoDrawTriangle函数,它使用扫描线算法完成一个抗锯齿的三角形光栅化),在硬件实现中,又有什么优劣势呢?
为什么使用FPGA可以为CPU实现图形加速
我不知道那么多学CS的同学有没有想过一个很反直觉的问题,尽管我们所学的绝大部分数据结构,编程语言,都围绕在CPU的架构设计中,然而就现实物理世界而言,CPU处理数据,其实并不高效,甚至可以说CPU只是被设计成了一种很方便编程的一种模式,但在很多的的计算层面,很多时候它即耗电,也低效。
为了说明这一点,我们举一个这样的例子,你正在做一个实验,你想测试一篮子鸡蛋从五楼摔在地上会摔成什么样子,显然的你可以直接把整篮子的鸡蛋从五楼直接倒下去,再去看鸡蛋们摔成什么样,而不是一个一个往下丢,等上个鸡蛋摔烂了再扔下一个。
前者很像GPU的工作模式,而后者则很像CPU的工作模式
我们现实世界本身就是一个并行的世界,当你从五楼倒鸡蛋的那一刻,鸡蛋甲不管摔成什么样都改变不了鸡蛋乙的结局,你只管倒鸡蛋,剩下的都是物理规则要考虑的问题,并不需要你来指导万有引力怎么做功。
同样的事情发生在数学表达式上,比如你需要计算
a2+b2+c2+d2+......
这是一个非常常见的计算表达式,我们可以说 a2 你不管算成什么样,都不会影响 b2 的结果,所以在电路层级,它的模型可以被设计成类似这个样子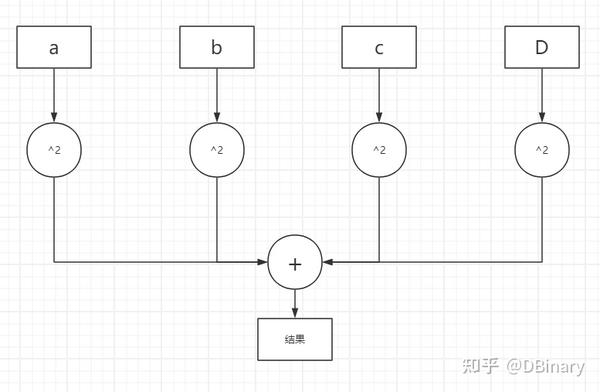
我们可以说a,b,c,d是可以同时计算的,但如果我们先不讨论乱序发射和并行优化,经典的CPU模型,需要先计算 a2 再计算 b2 ...然后再将它们一步一步加起来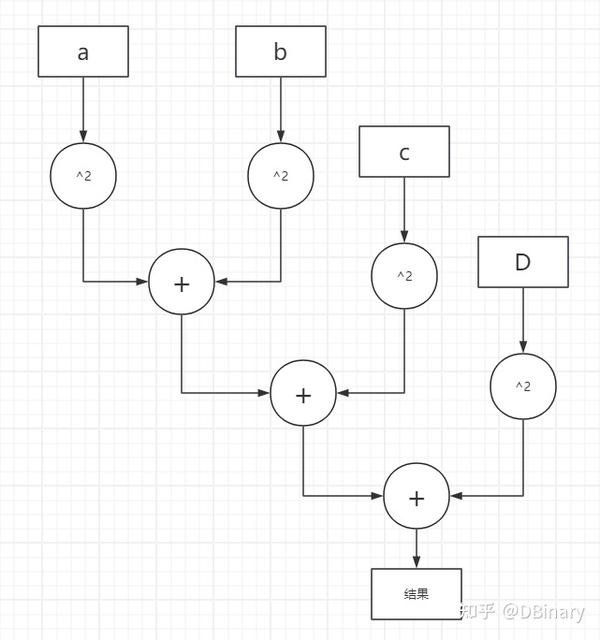
你可能会问了,为什么CPU要这样设计,实际上还是资源的锅,例如在上面的例子中,如果你希望a,b,c,d能够同时计算,你就需要多个乘法器和加法器,而这些都需要占用芯片的面积资源,但下面你完全可以复用这些乘法器和加法器,然后节省下更多的资源来支持更多的功能.因此,CPU为了实现更好的通用运算,显然不可能为某个单一需求耗费大量的物理资源上去.
时至今日,GPU在架构上已经几乎属于GPGPU(General Purpose Computing on GPU)其身份已经在相当程度偏向于通用计算而不是图形处理。并行是GPU的一大优势。
但现在我们思考一个问题,不论是CPU还是GPU,我们处理的绝大部分计算,都是IO密集型计算,目前流行的架构中,都需要从外部存储设备中调取资源进行计算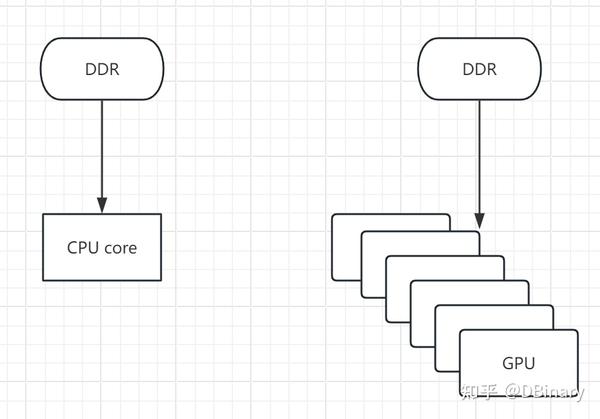
你会发现哪怕GPU拥有再多的核心,再快的运算速度,但是运算的数据仍然需要从DDR中获取,但在大部分情况下,不论是CPU还是GPU,其运算速率都会受制于与DDR总线的通讯速率,而其中通讯总线严格来说本质上是串行的,你太不可能直接连线到ddr中的每一个cell,不论是经济上还是存储的物理位置可能导致的通讯相位差异上,都不是一个好主意。那么如果我们有一个计算需求是串行的,你会发现GPU运算的并行也会退化成串行。
你会发现这样一个矛盾的点,
比如说我们有一个非常复杂的任务X,当然了,绝大多数复杂的任务,都可以分解为简单任务比如1,2,3,4,5
因为是串行的任务,所以GPU的并行根本派不上用场,而经典的CPU,受制于其运算资源和寄存器,仍然傻傻的完成任务1,然后任务2,任务3.......,然后再完成所有任务之后再取下一个数据,重复这个过程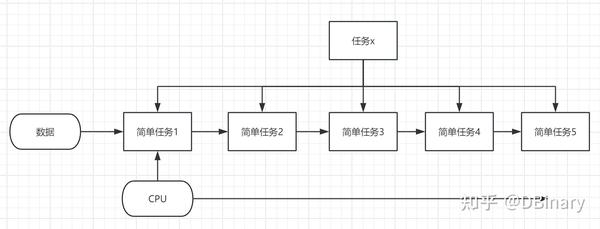
如果我们要将这个任务x,重复几千万遍,你会发现这是相当低效的,但是如果我们用专属的电路,这个电路能够在一个时钟周期内完成特定的简单任务时,你会发现效率提高了很多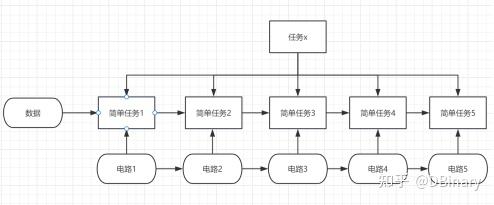
因为这个时候数据可以源源不断的送入进来,电路处理完自己得任务,将数据送给下一个电路就行了,当这个任务x重复的次数越多,其运算优势将会越明显并越接近数据的理论通讯带宽.
这就是经典的流水线结构,尽管CPU也有经典的5级流水线结构在处理复杂任务时仍然心有余而力不足,这个时候,ASIC或者说异构的FPGA,就能在从中获得巨大的运算优势.可以说不论是并行还是串行,同等工艺和材料水平下的定制化电路设计都是性能的理论天花板.
但这在近期注定也无法普及,毕竟不是人人家里都有一台光刻机,并且其开发和设计难度,也会远大于用上层语言设计搓代码。
但如果真有一天,打印芯片就像现在我们打印照片一样简单,家家都有一台光刻机的时候,那时我们的编程方式,也注定迎来巨大的变革。
Zynq7020 Soc的基础架构,我们的GPU架构模式
Zynq7000系列是一个异构的Soc,简单来说,其包含一个CPU(通常我们将它叫PS端)和四周外围的可编程逻辑门电路(通常我们称之为PL端),其中PS端负责处理复杂的控制逻辑,而PL端则可以根据上一章节的内容,设计为多级流水线结构,去加速处理在PS端本需要大量循环去处理的逻辑。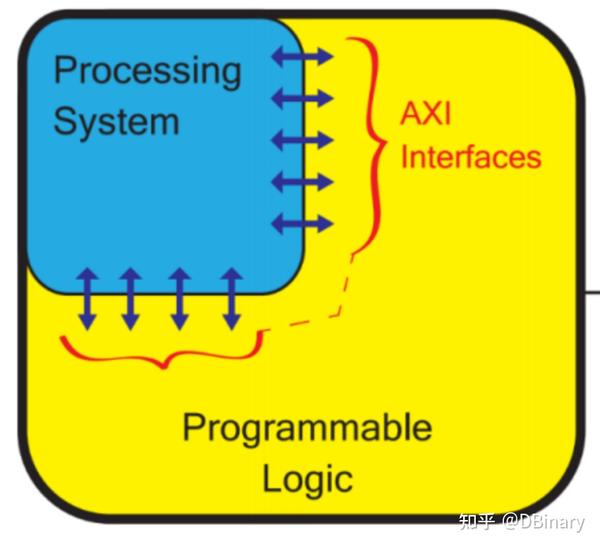
现在,让我们打开vivado(如果你已经安装好了的话),创建一个zynq7000系列的项目,那么在Block Design中创建一个Processing System,双击它,你将看到PS的架构图,让我们将重点放在下面这部分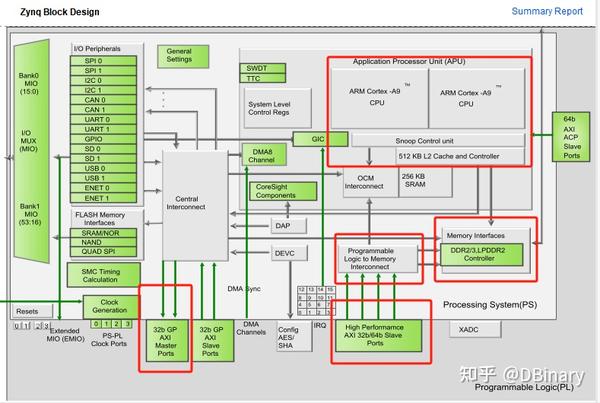
模块中的这几部分,是我们实现GPU时所需要直接涉及的部分,首先我们先看最顶上的APU(Application Processor Unit),它包含了两个ARM Cortex-A9 核心,在本例程中,我们只用到了其中的一个,请注意它包含了512KB 的Cache,因为在之后,我们需要考虑一些内存一致性的问题。
在下面是一个DDR Controller,它是内存控制器,而它连接到了一个PL to Memory InterConnect,这是一个以High Performance AXI总线所连接的模块(俗称HP口),这也就意味着,如果我们的GPU需要访问DDR作为显存,使用这个总线进行DDR的访问是一个实现简单且相当合算的选择。
最后注意到左下方一个32b GP AXI masterPorts,其同样属于AXI总线(AXI Lite俗称GP口),但是与上面的AXI接口比起来,这里是PS作为Master主动对PL进行访问,而上面则是作为Slave口,由PL对PS进行主动访问
我们进一步简化架构图,简单阐述一下GPU的工作原理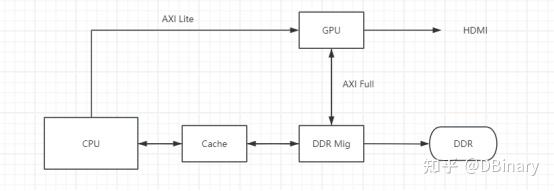
其中,CPU通过AXI Lite也就是GP口,向PL端的GPU模块发送渲染命令,这个过程由CPU主动发起
在GPU收到相关的渲染命令后,通过AXI Full(也就是HP)口访问DDR控制器读写DDR内存,完成一系列渲染工作,当然,GPU也有一个VDMA模块,该模块会循环不断从DDR读取Framebuffer的数据,然后将它输出到HDMI中,以实现屏幕显示。
最后GPU应该通过AXI Lite知道GPU的一些工作情况,当GPU运算完成后,CPU应该主动刷新Cache以保证渲染结果的一致性问题。
现在,是时候打开并部署我们的Vivado项目了,打开PainterEngine/platform/fpga_gpu/vivado,你将会看到一个压缩包,现在,将它放在与PainterEngine的级别目录,然后解压它

点进该文件夹,打开其中的xpr也就是vivado项目文件
点击左侧的Open Block Design,查看PainterEngine_GPU的整体结构图
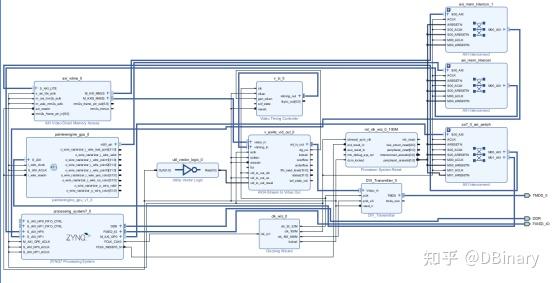
其中,painterengine_gpu_0是我们的核心工作模块,它占用了一个GP口和一个HP口,我们的渲染加速工作,就在这个模块中完成,axi_vdma模块占用一个HP口,循环从DDR中读取Framebuffer,然后将数据传递到vid_out模块中,v_lc_0是一个video timing controller,它用于生成HDMI的行场同步信号,最后vid_out输出到DVI_Transmitter,最终生成差分信号对,将信号输出HDMI.
右下角还有一个Clocking wizard,输入是从PS出来的一个50Mhz时钟,输出33.33Mhz频率信号及166.66Mhz信号,用于HDMI的Pixel Clock及Serial Clock,关于HDMI的生成时序,本文中不再详细参数,请自行查阅相关资料,而100Mhz的输出时钟,则作为GPU的工作时钟。
其余模块则是一些用于AXI总线调度仲裁及复位相关模块,不一一描述了。
实现AXI总线,完成CPU-GPU之间的数据交互
现在终于来到了代码解析阶段了,在本章节中,我们将实现AXI总线协议,完成PS-PL之间的数据交互。
AXI(Advanced eXtensible Interface)是一种总线协议,该协议是ARM公司提出的AMBA(Advanced Microcontroller Bus Architecture)3.0协议中最重要的部分,是一种面向高性能、高带宽、低延迟的片内总线。它的地址/控制和数据相位是分离的,支持不对齐的数据传输,同时在突发传输中,只需要首地址,同时分离的读写数据通道、并支持Outstanding传输访问和乱序访问,并更加容易进行时序收敛。AXI 是AMBA 中一个新的高性能协议。AXI 技术丰富了现有的AMBA 标准内容,满足超高性能和复杂的片上系统(SoC)设计的需求。
打开Block Design,其中下图中的两部分,就是AXI之间的连接引脚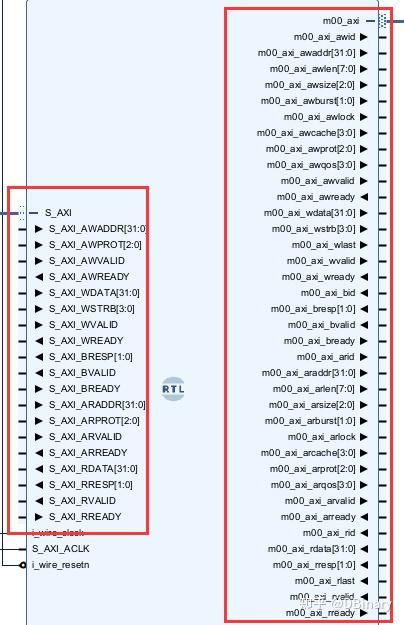
在PainterEngine_GPU中,同时实现了AXI Master(右)及AXI Slave(左)
别看AXI协议的引脚众多,其实AXI协议的通讯实现写起来非常的简单,可以说是众多通信底层协议中,相当友好相当方便实现的协议.
AXI协议分为了4个通道
- 读地址通道
- 读数据通道
- 写地址通道
- 写数据通道
简单来说,如果你想读一段数据,显然的,你需要给出读数据的地址和长度,那么这个地址和长度就是通过读地址通道进行传输的,而从机在获得了地址和长度之后,再将数据通过读数据通道发送回去.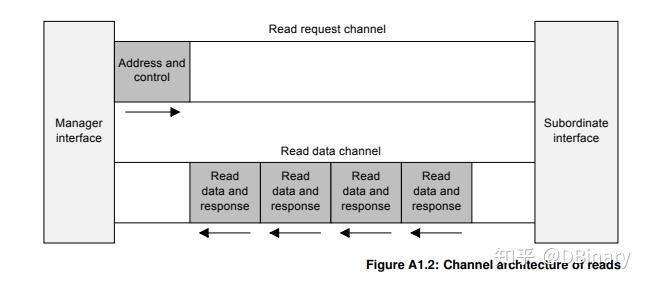
当然,读通道如此,写通道也差不多,当你发送完地址后,从机返回READY信号表示已经准备好接收数据,然后你就可以将数据源源不断往从机发送了。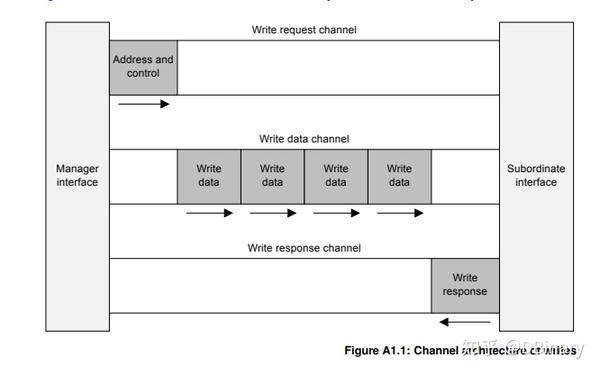
打个比方地址和长度就像编程语言中函数的参数,地址通道就是用来传输参数的,而数据通道就是在收到参数以后传输数据的。
你可以查阅IHI0022K_amba_axi_protocol_spec这份文档,获取AXI总线详细的视线描述,在下面我给出众多引脚的功能定义的关键几页内容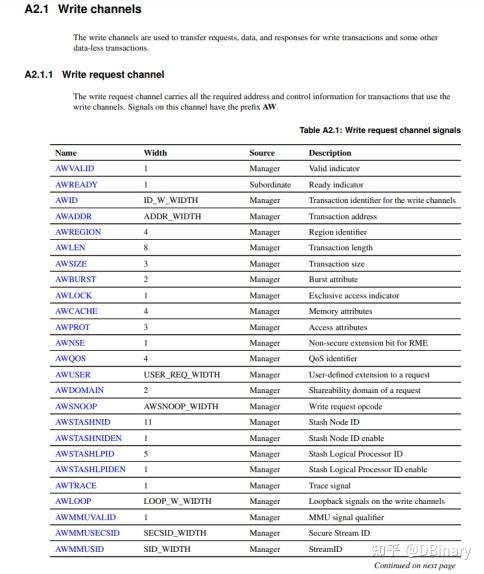
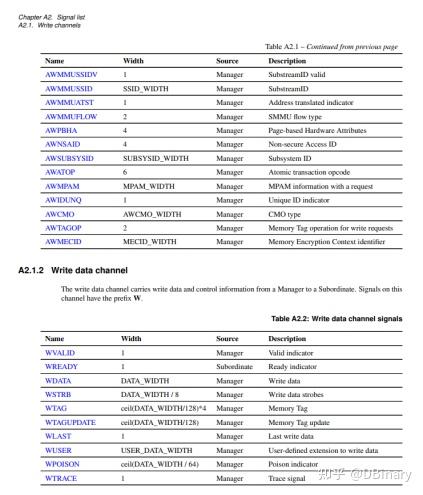
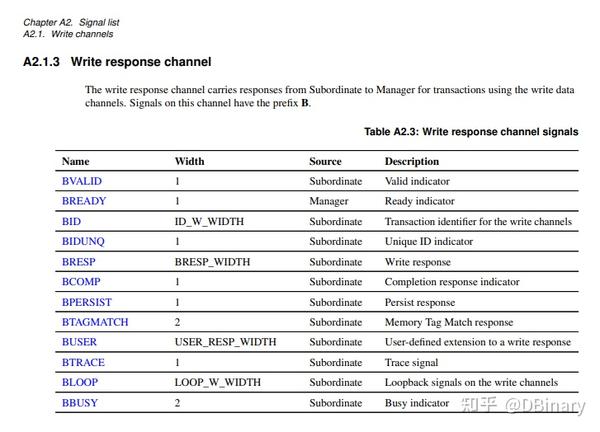
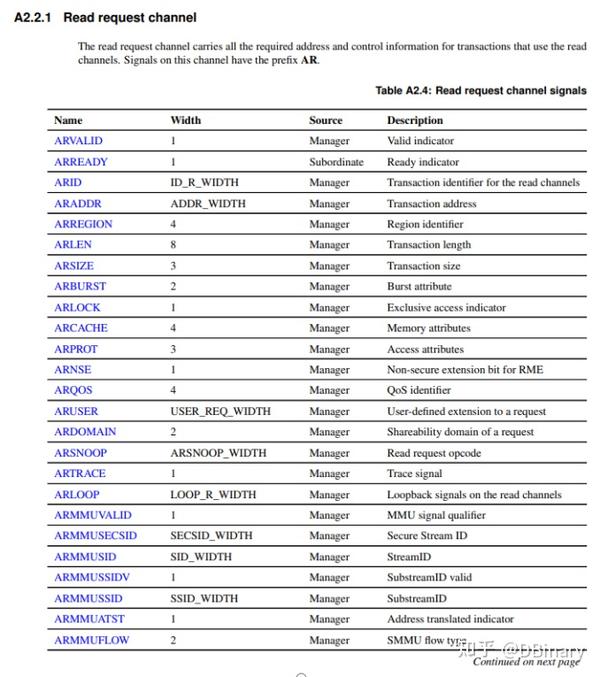
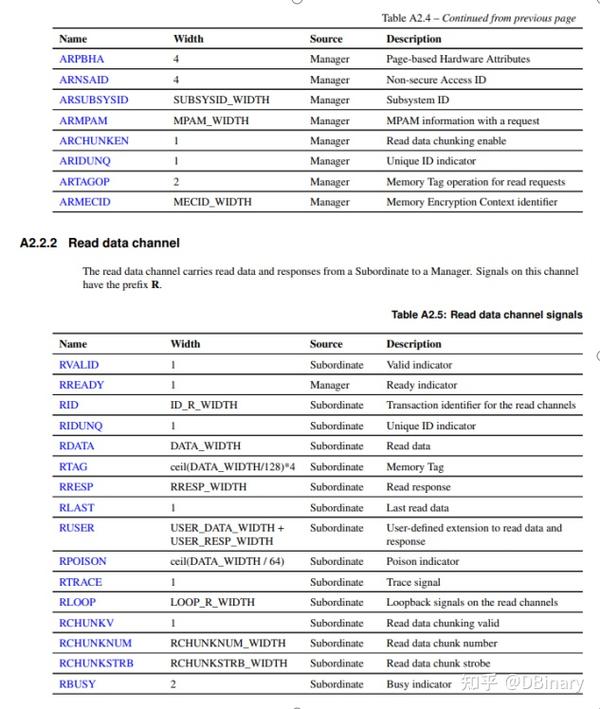
看官们可以先不必着急搞明白每一个引脚的详细定义和内容,在这里,我们先说说相对简单的Slave的实现,即使我们不懂上面的每个引脚定义,我们也可以偷个懒,在Create new IP中选择new AXI4 peripheral,然后点击下一步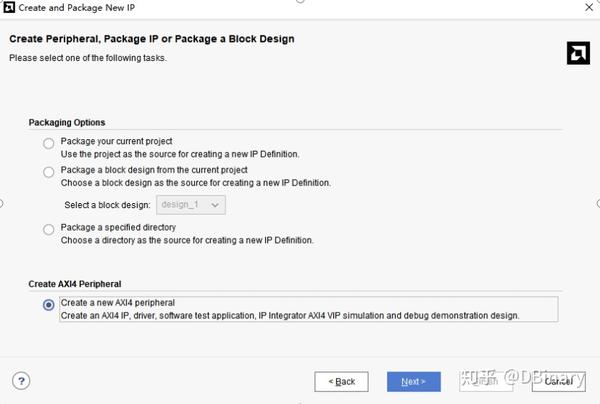
协议类型配置如下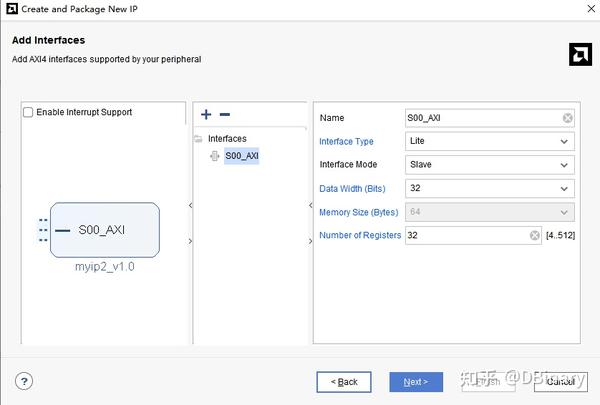
然后下一步,我们点击Edit IP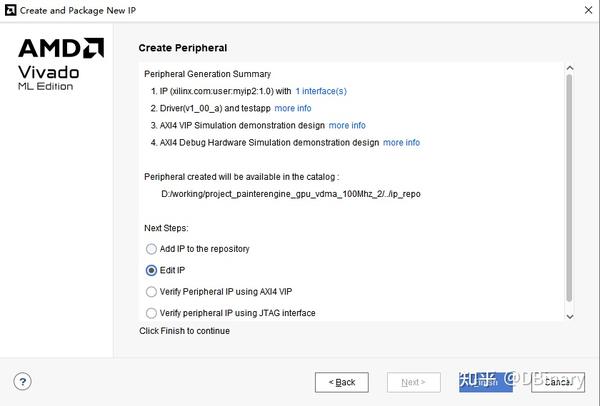
之后,Xilinx会给你生成一段AXI Lite Slave的代码,你可以直接将这堆代码给复制下来,而我则将新建了一个painterengine_gpu_registers.v将所有代码复制了过去,我们真正要改的,是399-437这几十行的代码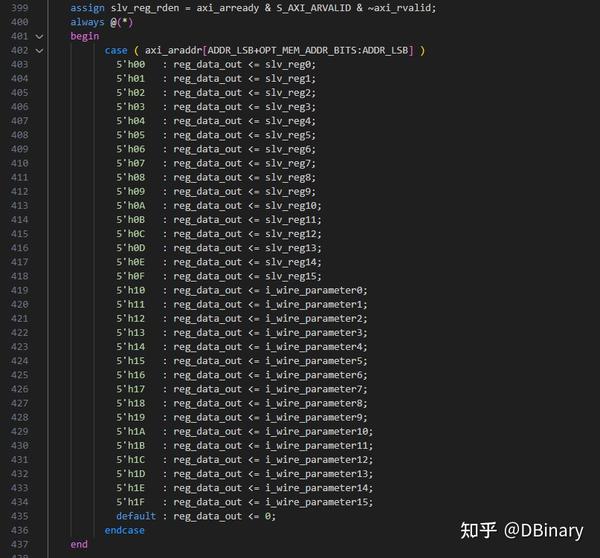
因为AXI总线总会被映射到一个地址中,而在之前我们设置了32个寄存器,每个寄存器是32位的,而我将0-15寄存器用于GPU的读通道,也就是CPU往GPU发送的命令和参数,就是通过这16个寄存器传递过来的,而16-31号寄存器则用于写通道,也就是GPU执行命令后的一些返回值,还有一些模块的工作状态,CPU可以通过这16个寄存器获取,当然我原本可以将读写通道复用在同一地址,但我觉得还是分开为好,避免驱动代码编写时让不熟悉底层架构的人产生一些困惑。
Slave的实现就这样完成了,在registers之上,我另外包装了一个顶层模块称之为painterengine_controller,在接收到CPU传递过来的命令后,Controller将会根据命令,使能GPU的其它工作模块,并让这些工作模块完成最终的渲染操作,同时Controller也会根据模块的工作情况,给出模块报错,执行状态,复位操作之类的内容.
这部分的代码,在painterengine_gpu_controller.v中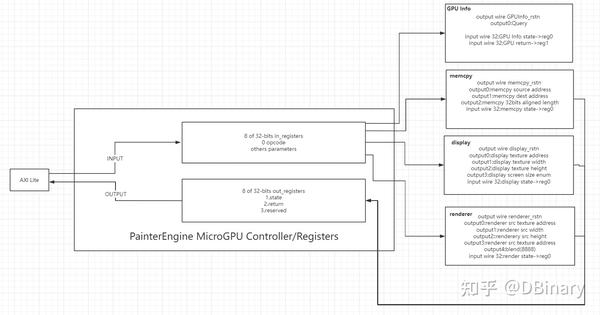
虽然slave我们舒舒服服偷了个懒,但是在GPU的axi master实现中,我们还是得自己搓一遍AXI协议,在GPU中,我将AXI的读和写分开进行了
你可以找到painterengine_gpu_reader.v和painterengine_gpu_writer.v,它们是一个4路的AXI协议读写模块,其中的代码我并不想花笔墨去解释,这样讲起来很低效,所以我打算使用testbench模块,演示memcpy模块的工作过程,因为这个模块同时使用到了读和写模块的功能.
我们先从写读通道开始,在通讯的一开始时,我们将需要读的地址写在M_AXI_ARADDR端口上,把需要读取的长度卸载M_AXI_ARLEN上(请注意,实际读长度为M_AXI_ARLEN+1),然后我们就可以拉高M_AXI_ARVALID引脚,然后等待M_AXI_ARREADY信号拉高,代表从机已经接收到信号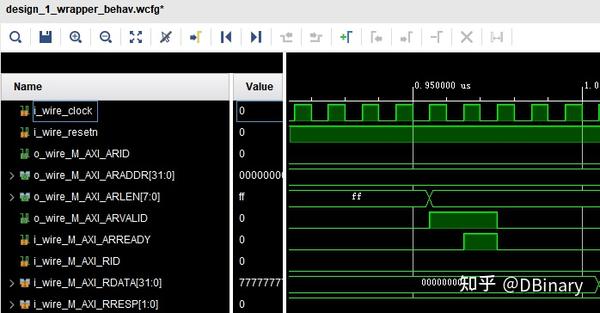
当监测到M_AXI_ARREADY后,就可以从读通道拉取数据了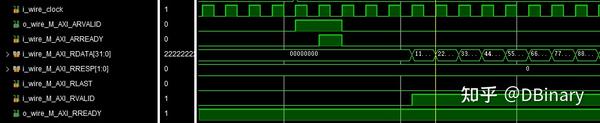
当检测到M_AXI_RVALID时,表示这个数据已经准备好了,那么当你接收完成这个数据时,你应该拉高M_AXI_RREADY信号,表示你已经成功接收到这一数据,那么从机将会继续在总线上放置下一数据,并拉高M_AXI_RVALID,之后就是循环这个过程.
我们再来看看写数据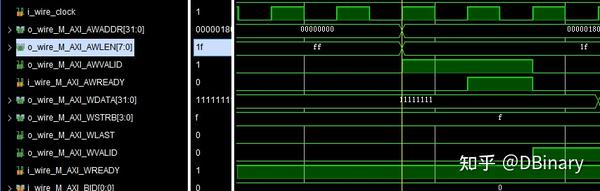
首先我们仍然将要写的地址放在M_AXI_AWADDR端口上,把需要写入的长度-1,然后放在M_AXI_AWLEN上,之后等待从机准备好,等待M_AXI_AWREADY信号拉高,如果M_AXI_AWREADY拉高了,我们就可以开始数据传输了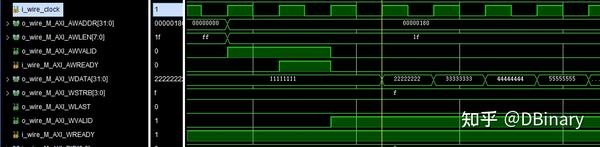
往M_AXI_WDATA上写数据,然后拉高M_AXI_WVALID信号,表示我们已经将数据传输在总线上,如果在下一周期M_AXI_WREADY信号是拉高的,表示从机已经成功接收到了这一个数据,那么我们就可以把下一个数据放在M_AXI_WDATA上写数据,然后拉高M_AXI_WVALID信号,循环往复直到所有信号发送完成.
写数据需要注意的是,在发送最后一个数据时,你需要拉高M_AXI_WLAST信号表示这是最后一个数据了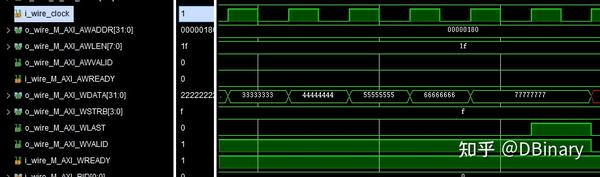
在读数据时这个引脚会被从机拉高,你可以检查当它拉高时是否是长度内最后一个数据,如果不是很可能代表你的数据传输出了问题.
最后拉高M_AXI_BREADY并检查M_AXI_BVALID,如果M_AXI_BRESP是0的话,表示这个数据传输成功完成了
最后在reader和writer的verilog代码中你可以看到下面的代码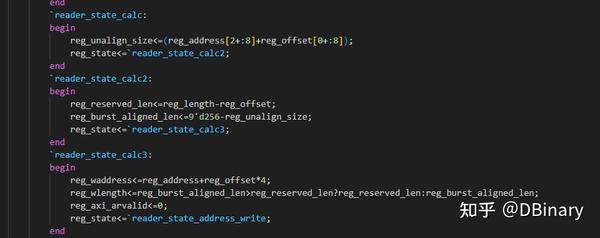
因为AXI不能跨越4K边界传输,所以这部分代码实际做的是做4K对齐.
FIFO,Memcpy,GPU Info的工作原理
下面,我们将简单阐述RTL设计中,最为重要的模块之一,FIFO的工作原理。
FIFO(First In, First Out,先进先出)是一种常见且重要的模块,用于数据缓冲和流量控制。它遵循“先进先出”的原则,即最早进入的数据最早被读取。它通常由一个存储单元阵列和两个指针(读指针和写指针)构成,用来管理数据的存取顺序。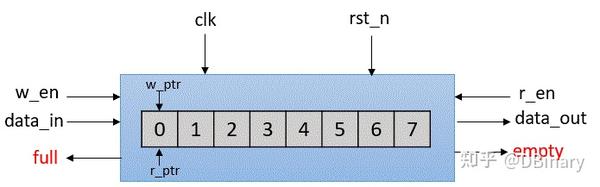
写指针(w_ptr):用于指向当前要写入数据的位置。每次写入数据后,写指针会自动递增,指向下一个存储单元。如果写指针到达阵列的末尾,它会返回到阵列的起始位置(即循环缓冲区)。
写使能信号(w_en):在写操作时,如果写使能信号有效且FIFO未满,数据会被写入由写指针指示的位置。
读指针(r_ptr):用于指向当前要读出数据的位置。每次读出数据后,读指针会自动递增,指向下一个存储单元。如果读指针到达阵列的末尾,它也会返回到起始位置。
读使能信号(r_en):在读操作时,如果读使能信号有效且FIFO不为空,数据会从由读指针指示的位置读出。
当然,在本文中,FIFO最重要的内容是用于数据缓存与数据同步,这就意味着,读写都拥有独立的时钟源,这可能导致当读写指针接近时出现一些亚稳态问题,但只要我们稍加注意一下用法,就可以很方便的处理一些列数据同步问题也避免这种亚稳态问题.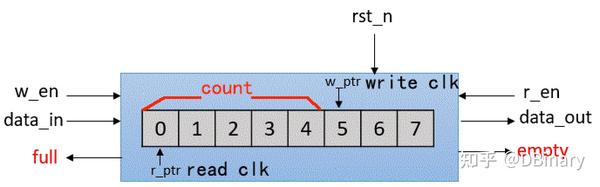
打开painterengine_gpu_fifo.v,其主要有三个并行单元构成
always @(posedge i_wire_write_clock)
begin
if(i_wire_write)
begin
if(wire_fifo_data_count0)
begin
reg_fifo_read_index<=reg_fifo_read_index+1'b1;
end
else
begin
reg_fifo_read_index<=reg_fifo_read_index;
end
end
End 可以看到它们分别操作读写指针,并处理数据写入的问题,而读写的触发则分别由不同的时钟源进行控制。
在处理完成fifo模块后,我们就可以完成我们GPU的第一个工作模块了,也就是memcpy
为了方便理解,我们来看下面的构造设计图
Controller相关的代码在painterengine_gpu_memcpy.v当memcpy模块被激活后,控制器会使能reader,fifo和writer
- controller向DMA reader发送地址和读长度命令,激活reader
- Reader开始读取ddr数据,数据将会存储在fifo
- 随后controller向DMA writer发送地址和长度,激活DMA writer,writer从fifo中拉取数据写入到ddr中
以上过程可能会循环多次,因为AXI的突发传输长度每次最大256次(32b),因此会一直循环到所有数据都传输完成为止.而memcpy模块,可以绕过CPU直接完成DDR-DDR的DMA传输,这意味着如果有较大的纹理拷贝,memcpy模块可以让CPU节省下运算资源去完成其它的工作.
讲完了memcpy模块,下面讲个比较简单的GPUinfo模块,这个模块用不到FIFO及AXI-DMA的读写,它主要完成以下两个功能
- 实现一个us级别的timer,用于时间计数
- 输出当前GPU的版本,并且用于和CPU交互一些调试信息
其中timer模块的实现比较简单,因为GPU的工作模块是100Mhz,所以我们只需要设计一个寄存器,当它累加到100时就刚好是1us,我们就让us寄存器+1,然后把这个寄存器通过AXI-Lite也就是之前写好的registers模块提供给CPU读取
reg[6 : 0] reg_tick_div100;
reg[31 : 0] reg_tick_us;
always @(posedge i_wire_clock or negedge i_wire_tick_resetn)
begin
if(!i_wire_tick_resetn)
begin
reg_tick_div100<=7'd0;
reg_tick_us<=0;
end
else
begin
if(reg_tick_div100==7'd100)
begin
reg_tick_div100<=7'd0;
reg_tick_us<=reg_tick_us+1;
end
else
begin
reg_tick_div100<=reg_tick_div100+1;
end
end
end而gpuinfo支持一个opcode及一个param,当opcode为1时,返回GPU的版本,当opcode为2时,返回一个调试信息,为3时,则返回us timer的计数器。相关实现的详细代码,你可以查阅painterengine_gpu_gpuinfo.v
调用VDMA IP核,实现HDMI输出
VDMA是vivado官方提供的IP核,首先添加一个VDMA模块,搜索并添加VDMA模块,并双击打开这个模块的配置页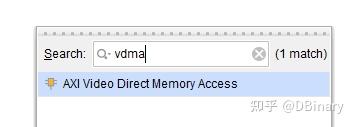
因为我们不需要写HDMI数据,所以可以直接把Enable Write Channel这个通道删掉,开启Read Channel就像,注意把Steam Data Width改成24,因为我们只需要输出RGB颜色就可以了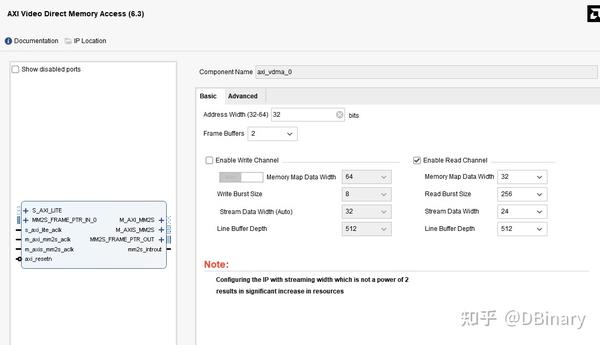
随后我们创建AXI4-Stream to video out模块,这个模块将会吧DMA数据按照DVI的时序进行输出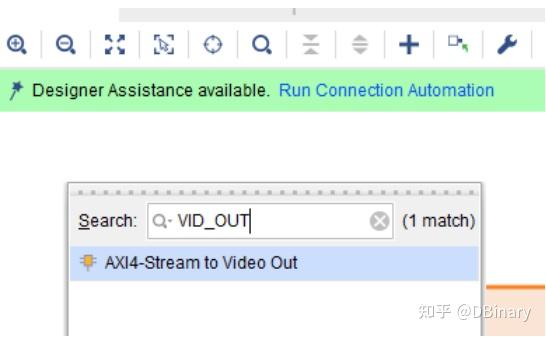
打开模块进行设置,参数设置除了clock mode 修改成独立,其余都保留默认值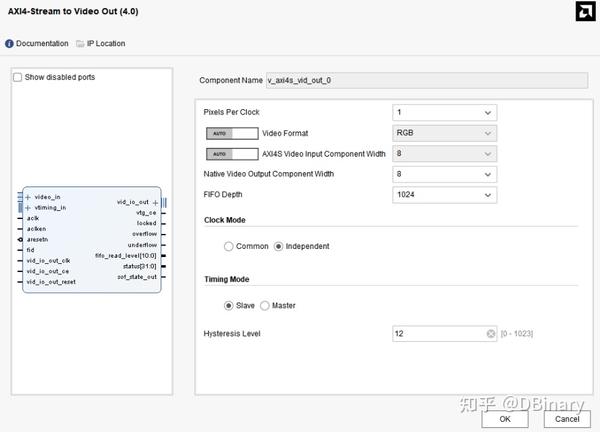
因为后面我们要用video timing controller 模块来提供视频时序,所以Timing Mode这里选择slave模式
我们还需要用到一个DVI_Transmitter模块,点击Setting-->IP-->Repository
这里我已经把这个DVI_Transmitter模块放在了PainterEngine/platform/gpu_ip/目录下,直接引用就可以了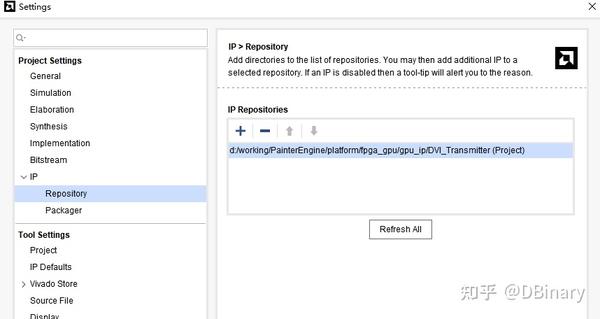
最后增加Video Timing Controller 模块
video Timing Controller是视频时序控制器,支持AXI-Lite接口协议(可通过该接口在PS端动态调整分辨率不过这里用不到,所以把Include AXI4-Lite Interface关掉就可以了)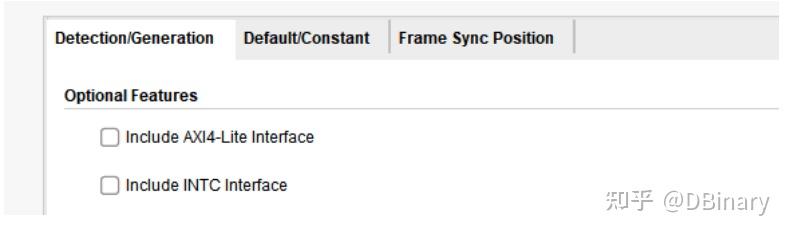
而在Default参数页面,我采用的是一个800x480分辨率的HDMI输出时序,HDMI具有严格的时序时钟要求,因此这部分内容按照以下参数进行设置就可以了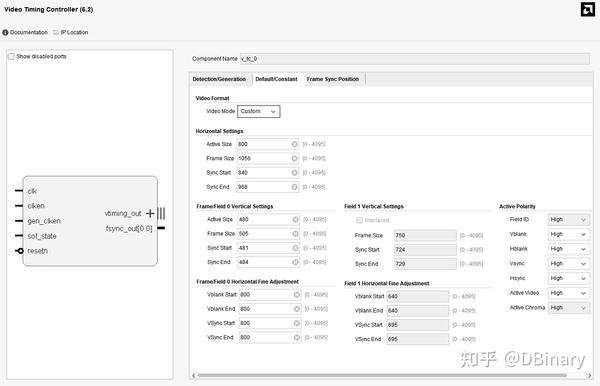
最后我们需要给HDMI模块和我们的GPU模块添加工作时钟,于是添加一个Clock Wizard,其中33.33Mhz提供给了Pixel Clock,166.66Mhz提供给了DVI serial clock,100Mhz则是GPU的工作时钟,输入则是PS端出来的50Mhz时钟,当然,PainterEngine GPU应该可以超频到150Mhz左右,这部分就自行测试,改改输出时钟即可.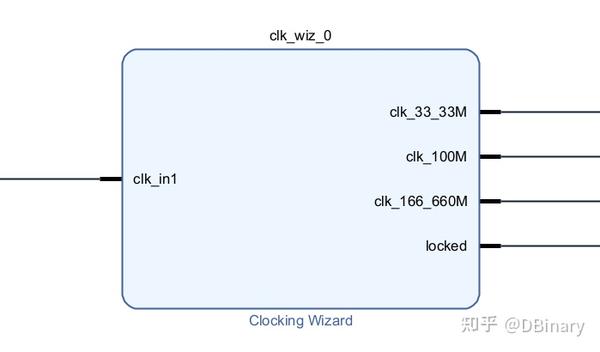
本章节的最后,显然上面的内容只是让你了解这些模块的大致功能,实际上项目中我已经连接好了,你直接打开项目即可.
实现颜色纹理的AlphaBlend
到这里,我们最终来到GPU的最关键模块之一,也就是实现颜色的AlphaBlend,当然AlphaBlend其实有多重混合算法,这里我选用其中比较常用的一种.
代码中的数学公式可以分为颜色通道(红、绿、蓝)和透明度通道的计算公式。
对于红色通道 `r`,绿色通道 `g`,蓝色通道 `b`,混合公式如下:
简化为:
其中:
是混合后的颜色分量(红、绿、蓝通道中的一个)。
是原来表面像素的颜色分量。
是要叠加的颜色分量。
是要叠加颜色的 alpha 值,表示透明度。
透明度的混合公式为:
其中:
- 是混合后的透明度。
- 是原来表面像素的透明度。
- 是要叠加颜色的透明度。
最终,混合后的颜色值 \( (r_{\text{new}}, g_{\text{new}}, b_{\text{new}}, a_{\text{new}}) \) 是由上述公式计算得到的,其中每个通道的计算方式依赖于原有像素的颜色分量和新颜色的颜色分量及其透明度。
我们先来看看AlphaBlend的C语言实现
c = psurface->surfaceBuffer[X + psurface->width * Y];
c._argb.r = (px_uchar)(((256 - COLOR._argb.a) * c._argb.r + COLOR._argb.r * (COLOR._argb.a+1)) >>8);
c._argb.g = (px_uchar)(((256 - COLOR._argb.a) * c._argb.g + COLOR._argb.g * (COLOR._argb.a+1)) >>8);
c._argb.b = (px_uchar)(((256 - COLOR._argb.a) * c._argb.b + COLOR._argb.b * (COLOR._argb.a+1)) >>8);
c._argb.a = 255 - (((256 - c._argb.a) * (255 - COLOR._argb.a)) >>8);
psurface->surfaceBuffer[X + psurface->width * Y] = c;让我们逐行解释:
- c = psurface->surfaceBuffer[X + psurface->width * Y];
这行代码获取了位于图像表面 `psurface` 上 `(X, Y)` 坐标的像素颜色,并将其存储在 `c` 变量中。`psurface->surfaceBuffer` 是一个像素缓冲区,`X + psurface->width * Y` 是 `(X, Y)` 坐标在一维数组中的索引。 - 红色通道计算:
c._argb.r = (px_uchar)(((256 - COLOR._argb.a) * c._argb.r + COLOR._argb.r * (COLOR._argb.a + 1)) >> 8);
这段代码进行红色通道的α混合计算。`COLOR._argb.a` 是新颜色的α值(透明度),`c._argb.r` 是原本像素的红色分量,`COLOR._argb.r` 是新颜色的红色分量。通过混合公式,新的红色值会根据原本的像素颜色和新颜色的透明度来计算。 - 绿色通道计算:
c._argb.g = (px_uchar)(((256 - COLOR._argb.a) * c._argb.g + COLOR._argb.g * (COLOR._argb.a + 1)) >> 8);
绿色通道的计算方式与红色通道相同,依赖于绿色分量的值。 - 蓝色通道计算:
c._argb.b = (px_uchar)(((256 - COLOR._argb.a) * c._argb.b + COLOR._argb.b * (COLOR._argb.a + 1)) >> 8);
蓝色通道的计算方式同样相似。 - α通道计算:
c._argb.a = 255 - (((256 - c._argb.a) * (255 - COLOR._argb.a)) >> 8);
这行代码计算新的α值,也就是透明度。这一步将新颜色的透明度与原有像素的透明度进行混合。 - **`psurface->surfaceBuffer[X + psurface->width * Y] = c;`**
最后,将计算得到的新颜色值存回表面缓冲区中,更新该像素的颜色。
现在,我们将上面的运算,能够并行的做成并行,不能并行的设计为流水线运算,将其转换成verilog代码,详细的代码位于painterengine_gpu_blender.v中,因为代码的片段比较长,在这里就不详细的描述了.
除了颜色的AlphaBlend,另一个需要实现的,则是颜色的混合Blender系数,例如在渲染一张半透明的纹理时,我想要进一步减少其透明度,或者说是减少某一颜色通道的权重,那么,我会设置另一个Blender系数,来完成这个功能
在C语言中,它的表述为如下代码
clr = pdata[(clipy + j) * tex->width + (clipx + i)];
bA = (px_int)(clr._argb.a * Ab) >> 7;
bR = (px_int)(clr._argb.r * Rb) >> 7;
bG = (px_int)(clr._argb.g * Gb) >> 7;
bB = (px_int)(clr._argb.b * Bb) >> 7;其中,Ab,Rb,Gb,Bb都是一个8位数据,如果将其系数以浮点来计算,其范围是0-2,即128表示其系数1,255表示其系数1.99,其中0-1的范围为减弱,1-2的范围为增益,最大增益1.99倍,bA,Br,BG,bB是混合后的颜色值,这个Blender系数的混合过程在AlphaBlend之前,其实现代码同样在painterengine_gpu_blender.v中.
完成三角图元的光栅化渲染
最后,我们来完成GPU的最后一个功能渲染模块,以重心法完成图元的光栅化渲染,同样的,我们仍然从C语言开始:
void rasterizeTriangle(int x1, int y1, int x2, int y2, int x3, int y3, int grey) {
int minX = (x1 < x2) ? ((x1 < x3) ? x1 : x3) : ((x2 < x3) ? x2 : x3), maxX = (x1 > x2) ? ((x1 > x3) ? x1 : x3) : ((x2 > x3) ? x2 : x3);
int minY = (y1 < y2) ? ((y1 < y3) ? y1 : y3) : ((y2 < y3) ? y2 : y3), maxY = (y1 > y2) ? ((y1 > y3) ? y1 : y3) : ((y2 > y3) ? y2 : y3);
for (int y = minY; y <= maxY; y++) for (int x = minX; x <= maxX; x++)
{
int area1 = (x2 - x1) * (y - y1) - (y2 - y1) * (x - x1);
int area2 = (x3 - x2) * (y - y2) - (y3 - y2) * (x - x2);
int area3 = (x1 - x3) * (y - y3) - (y1 - y3) * (x - x3);
if ((area1 >= 0 && area2 >= 0 && area3 >= 0) || (area1 <= 0 && area2 <= 0 && area3 <= 0))
{
PainterEngine_DrawPixel(x, y, PX_COLOR_RED);
}
}
}上面的代码是一个重心法光栅化图元的代码
计算三角形的包围矩形:
int minX = (x1 < x2) ? ((x1 < x3) ? x1 : x3) : ((x2 < x3) ? x2 : x3);
int maxX = (x1 > x2) ? ((x1 > x3) ? x1 : x3) : ((x2 > x3) ? x2 : x3);
int minY = (y1 < y2) ? ((y1 < y3) ? y1 : y3) : ((y2 < y3) ? y2 : y3);
int maxY = (y1 > y2) ? ((y1 > y3) ? y1 : y3) : ((y2 > y3) ? y2 : y3);
- 通过比较顶点的 x 和 y 坐标,找到三角形在 x 轴和 y 轴方向上的最小值和最大值。
- `minX, maxX` 是包围矩形在 x 轴上的范围。
- `minY, maxY` 是包围矩形在 y 轴上的范围。
遍历包围矩形中的所有像素:
for (int y = minY; y <= maxY; y++)
for (int x = minX; x <= maxX; x++)
- 使用双重循环遍历从 `minY` 到 `maxY`,以及从 `minX` 到 `maxX` 的所有像素点 `(x, y)`。
使用重心坐标判断像素是否在三角形内:
int area1 = (x2 - x1) * (y - y1) - (y2 - y1) * (x - x1);
int area2 = (x3 - x2) * (y - y2) - (y3 - y2) * (x - x2);
int area3 = (x1 - x3) * (y - y3) - (y1 - y3) * (x - x3);
- 对于每个像素点 `(x, y)`,计算它与三角形的三个边的相对位置。
- `area1, area2, area3` 分别代表点 `(x, y)` 相对于三角形的三条边的位置。
- 如果 `(x, y)` 在三角形内或边界上,那么 `area1, area2, area3` 的符号要么全为正,要么全为负。
- 上色:
if ((area1 >= 0 && area2 >= 0 && area3 >= 0) || (area1 <= 0 && area2 <= 0 && area3 <= 0))
{
PainterEngine_DrawPixel(x, y, PX_COLOR_RED);
}- 如果 `(x, y)` 在三角形内或边界上,则调用 `PainterEngine_DrawPixel` 函数对这个点进行上色(这里使用的是红色 `PX_COLOR_RED`)。
当然,上述的图元光栅化代码仍然相当的原始,它既没有没有Zbuffer,也没有进行纹理映射等运算,只能够完成基础的图元颜色填充渲染.
如果你对完整的Zbuffer及纹理隐射有兴趣,你可以在PainterEngine PX_D.c中PX_3D_RenderListRasterization函数中找到这部分的完整支持,为什么我不将这部分放在Verilog中实现,是因为Zynq的BRAM资源仅仅只有1MB,如果要做Zbuffer及纹理采样,低延迟的BRAM是完全不够用的,但如果我使用DDR做ZBuffer或纹理采样器,那么DDR访问将会有相当严重的Latency问题,导致最终的渲染速度还不如在PS端直接运行软渲染。
根据以上,你可以在painterengine_gpu_rasterizer.v中找到以上光栅化的verilog模块实现,至此,我们实现renderer模块的准备工作也算最终完成了。
实现renderer模块
我们来看看renderer模块的架构设计图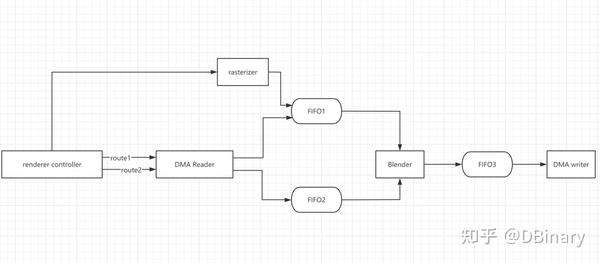
首先,当我们准备好对2个纹理做AlphaBlend的时候
- renderer controller将会先获取需要做混合渲染的原始图像的内存地址,使能DMA Reader的route1,DMA Reader将会读取一行中一个Block的颜色序列将它存储在FIFO1中
- renderer controller将会先获取需要做混合渲染的目标图像的内存地址,使能DMA Reader的route2,DMA Reader将会读取一行中一个Block的颜色序列将它存储在FIFO2中
- 当FIFO2有数据时,Blender就已经开始工作了,它将会把FIFO1和FIFO2中的颜色数据做AlphaBlend,然后输出到FIFO3,这个过程在DMA Reader还在读取目标图像数据时就已经开始了
- 当renderer controller读取完FIFO2的内容后,会直接使能DMA writer,DMA writer将会将最终渲染好的数据写到目标图像的DDR内存空间中,从而完成这个AlphaBlend的过程
第二部分是完成rasterizer模块,完成图元渲染的过程,流程如下 - Renderer将图元顶点及颜色数据,直接传递给rasterizer模块中,rasterizer会以行扫描的方式,完成三角形一行的光栅化,然后把光栅化数据存储在FIFO1中
- renderer controller将会先获取需要做混合渲染的目标图像的内存地址,使能DMA Reader的route2,DMA Reader将会读取一行中一个Block的颜色序列将它存储在FIFO2中
- 当FIFO2有数据时,Blender就已经开始工作了,它将会把FIFO1和FIFO2中的颜色数据做AlphaBlend,然后输出到FIFO3,这个过程在DMA Reader还在读取目标图像数据时就已经开始了
- 当renderer controller读取完FIFO2的内容后,会直接使能DMA writer,DMA writer将会将最终渲染好的数据写到目标图像的DDR内存空间中,从而完成这个三角形光栅化的过程
这里也最终回收了之前为什么使用重心法来作图元光栅化的坑,因为这样AlphaBlend和rasterizer将会有很大一部分的功能模块能完成重合,实现功能模块最大的复用性,可以看到,我本质只是在FIFO1之前加入了几何光栅化模块,就可以完成该图元光栅化,当然,如果想添加uv运算或采样器,也可以在这里实现,这种添加并不会特别困难,读者如果有兴趣完全可以自己实现。
Renderer模块的代码,你可以在painterengine_gpu_renderer.v中找到。
编写GPU驱动
最终,让我们查看PL端GPU的整个结构设计图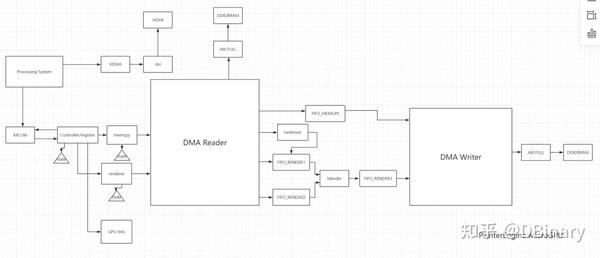
以上整个模块的例化及连接关系,你可以在painterengine_gpu.v中找到,最后就是为我们的GPU编写驱动程序了.
在registers和controller模块中,我们提到了AXI总线是以地址隐射关系进行操作的,因此,打开vivado,打开address editor你可以查看到各AXI Port的地址隐射关系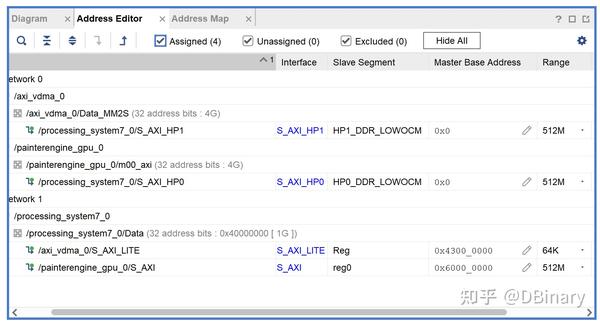
但一般情况下,完全可以不使用这种硬编码地址的方式来操作我们的GPU
回到vivado,我们点击左下角的generate bitstream,等待整个PainterEngine GPU综合完成
在成功之后,导出hardware
除此之外,我们也需要导出对应的Bitstream
我们打开Vitis,新建一个项目,然后点击Create Platform Component
然后选中我们刚刚导出的hardware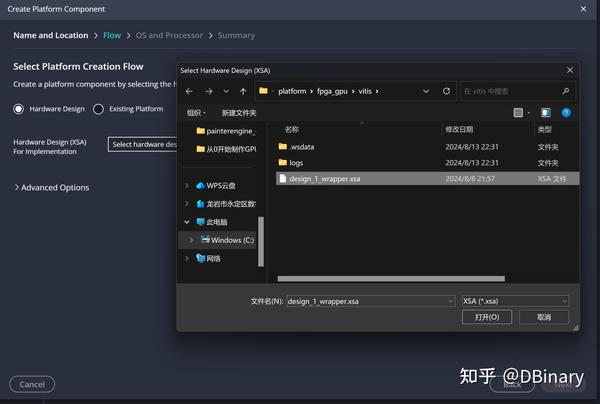
在平台选择上,我们选择无操作系统的standalone环境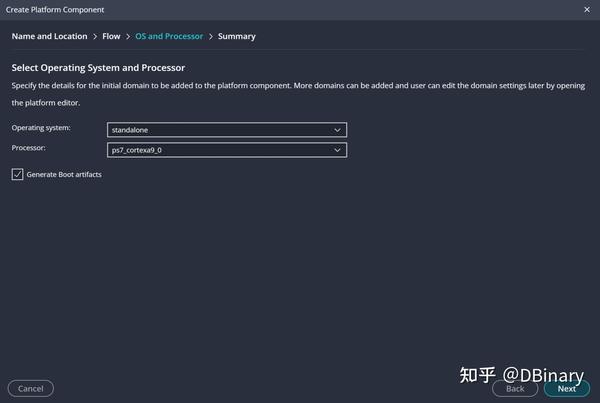
点击完成,然后build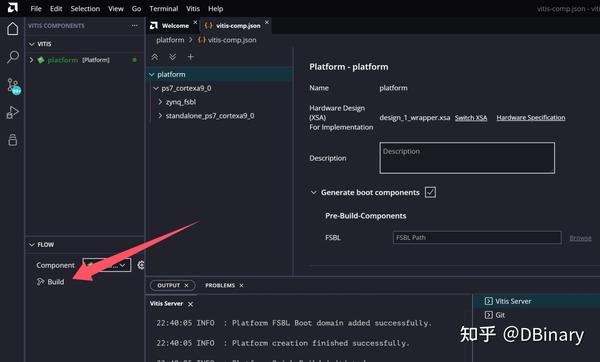
等待完成后,再次点击File-->new Component-->Application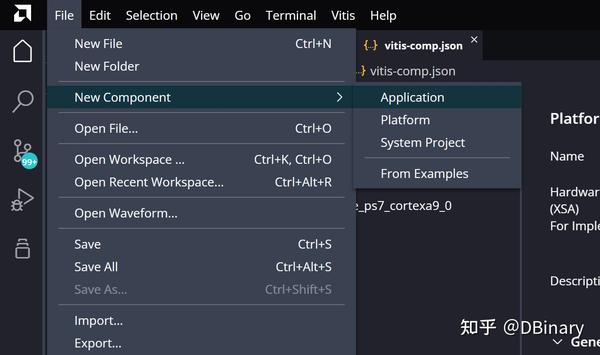
选中刚刚的platform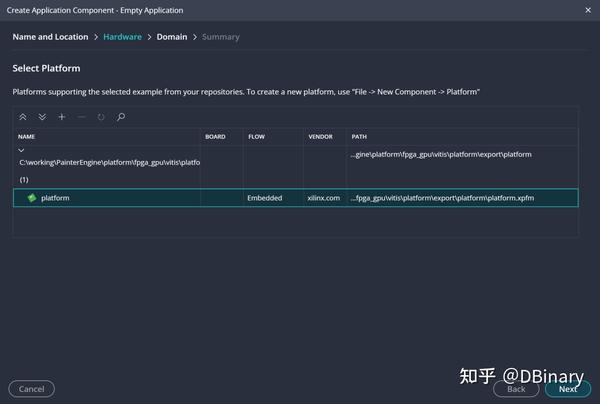
点击Next Finish,找到PainterEngine/platform/fpga_gpu/processing_system,将里面的文件复制到当前目录的src下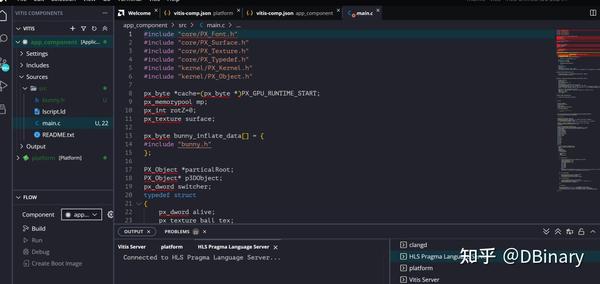
打开PainterEngine/core/PX_GPU.h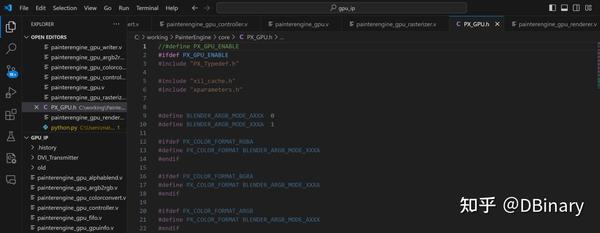
将最顶部的注释去掉,使能PainterEngine GPU的硬件加速
在左边的launch.json中右侧的bitstream中,选中我们刚刚导出的bitstream file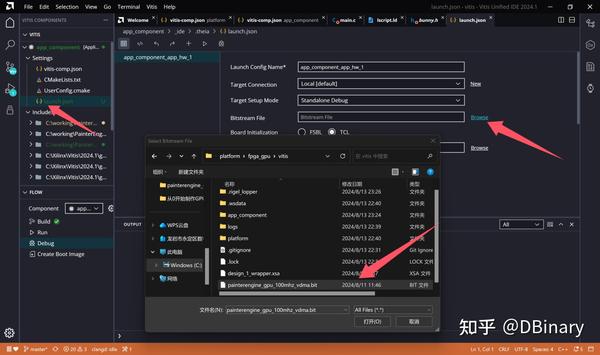
现在,让我们点开PainterEngine/core/PX_GPU.c,这是GPU的软件驱动,我们回到一开始的地址映射问题,在xparameter.h中你都可以找到对应的宏定义,例如在下面的定义中,我们知道AXI-VDMA的映射开始地址是0x43000000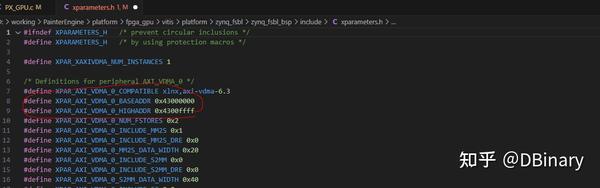
同样的,用于GPU工作的AXI也可以找到
现在,知道了映射的地址后,我们可以开始实现驱动了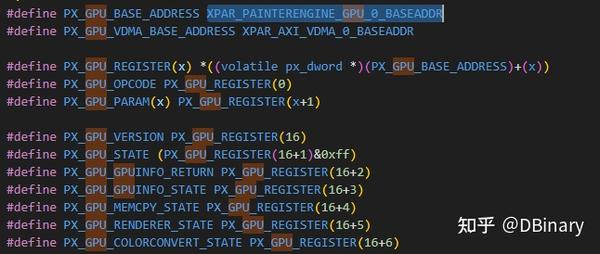
我们先将xparameter中的映射宏包含进来,然后使用PX_GPU_REGISTER访问映射地址内的各个寄存器变量
之前我们已经说过了,在registers中,有16个输入寄存器和16个输出寄存器,其中,输入寄存器的第一个寄存器为操作码寄存器,相当于告诉GPU我们想要调用哪个模块实现哪一部分的功能
我们用PX_GPU_OPCODE来代表它
其它的寄存器则为参数寄存器,比如我们实现三角形光栅化,那么我们应该同时传递三角形的顶点和颜色等参数过去.
输出寄存器从16开始,输出寄存器大部分为当前模块的状态,通过这些寄存器我们可以知道GPU当前是否已经完成了诸如渲染等任务,是否已经准备好下一个事务.
在此之前我们先完成GPU的初始化工作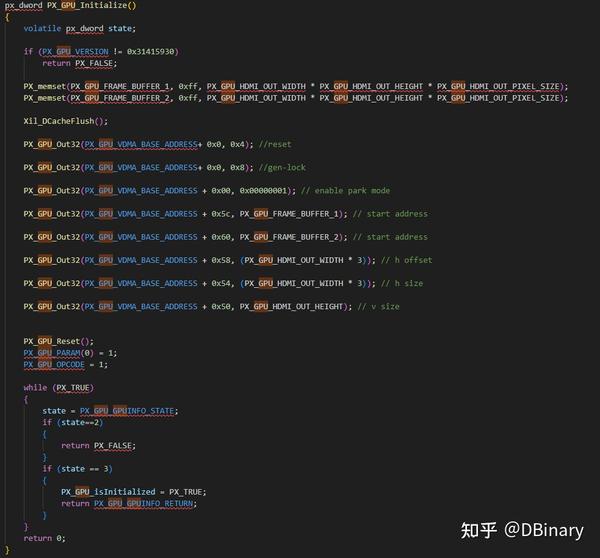
首先这段代码会在DDR空间中,划出2块800x480的RGB空间作为framebuffer,然后它将会使能VDMA模块,将两个Framebuffer的地址传递进去.然后执行GPU工作模块的复位操作也就是PX_GPU_Reset(),在复位操作中,会检查一些寄存器的magic number,以确保和GPU的通讯是正常工作且GPU的版本是适配当前驱动的.当执行完初始化代码后,HDMI输出就已经开始工作了.
之后是present的代码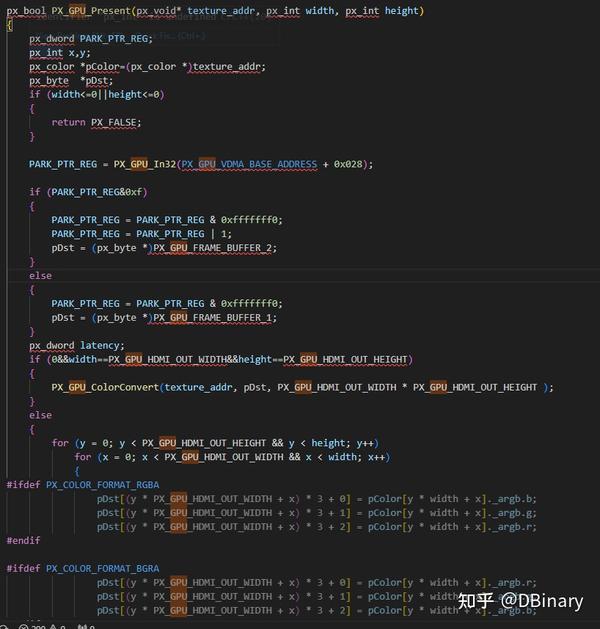
这部分的代码主要功能是把texture/surface的ARGB数据转换成适合显示的RGB数据,当然这部分也将由GPU的ColorConvert模块负责完成,颜色转换的数据将会直接写入到framebuffer当中,并通过配置寄存器让当前的现实帧实现切换.
另一个更具有代表性的则是实现AlphaBlend和rasterize功能的renderer模块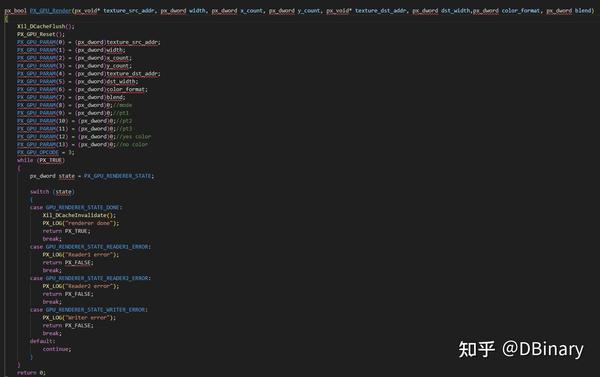
首先我们先将Cache的数据同步到DDR中,然后我们将需要混合或者光栅化的surface在DDR的地址传递给GPU,或者是三角形的顶点信息传递给GPU模块,随后将OPCCODE赋值为3,这个时候,当GPU检测到该OPCODE,就会开始对应的渲染操作,随后是一个循环,它将会循环读取renderer模块的寄存器信息,直到渲染完成后将DDR数据拉回到Cache,完成渲染,当然你完全可以在置位Opcode中返回,这个时候你可以用CPU去处理其它的事情,这并不是影响GPU的工作(但你不能访问当前正在渲染的纹理,这样可能会导致一系列数据不一致的问题),在下一个操作前,再去检查GPU上一个工作事务是否已经完成了,这是非常高效的一种工作模式,我为了避免读者在不清楚底层原理的情况下可能做出这种导致渲染数据不一致的问题,因此我并没有采用这种工作模式,但缺点也就是我不得不浪费一些CPU资源,空等GPU完成这部分的渲染操作.
其余的像memcpy之类的驱动,基本也都大同小异,我就不一一举例了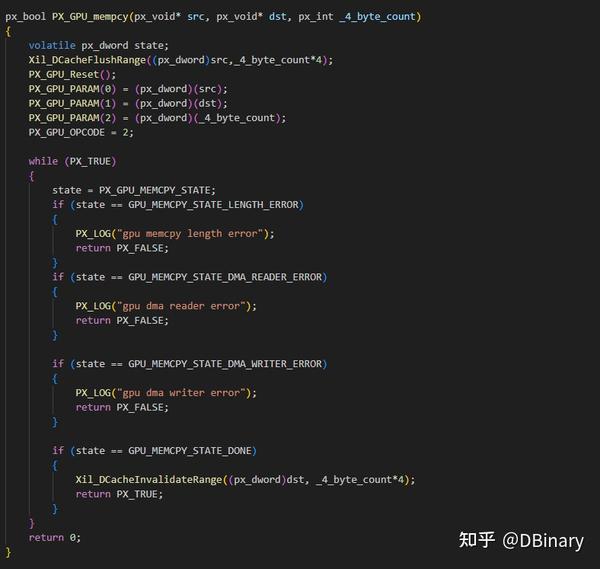
软硬结合渲染图元、模型、实现一个粒子系统
最后,我们点击build,然后点击debug,等待我们的程序烧录到zynq芯片上,位于PainterEngine/platform/fpga_gpu/process_system中的main.c是一个示范程序,它将分别完成一个单个图元(三角形)渲染,一个例子系统渲染,一个基于图元渲染的模型渲染,将你的开发板接入到屏幕上,你就可以看到运行的结果了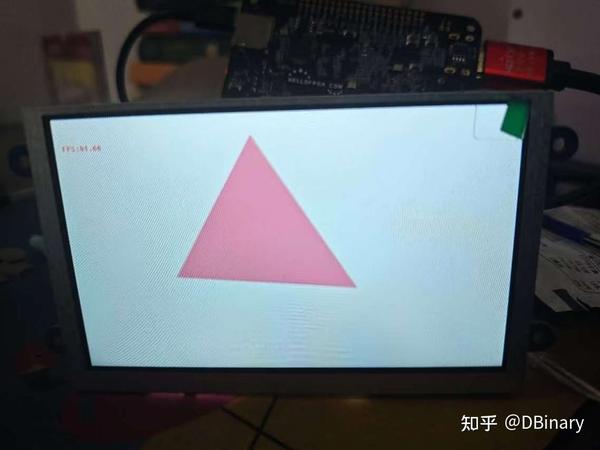

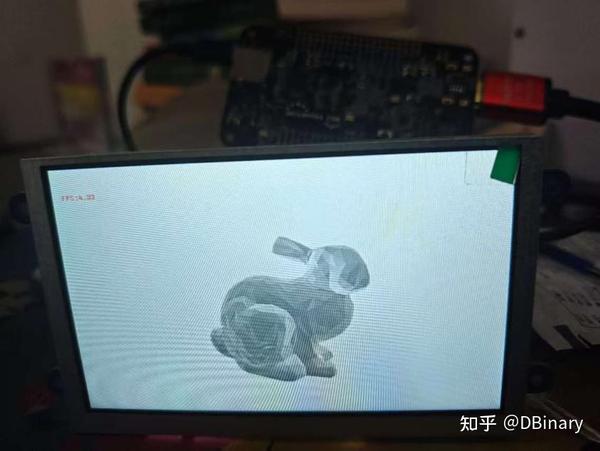
到此我们的FPGA-GPU项目完成
感言,后记
没啥感言,战斗,爽
来源:知乎 www.zhihu.com
作者:DBinary
【知乎日报】千万用户的选择,做朋友圈里的新鲜事分享大牛。
点击下载