




























大模型行业如何持续发展(知乎AI先行者沙龙)
以下是我在知乎AI先行者沙龙活动上的演讲实录,应线上线下听众们的诉求,现将演讲内容分享出来:非常荣幸,能够在这里分享我自己对于大模型这个行业目前的一些认识。首先说一下我,我是清华大学电子工程系的教授,今天在座各位可能做算法和应用比较多。但我是一位做硬件、芯片和基础软件更多的学者,以及有过一定的创业经历,所以从我的角度来给大家去讲一讲我怎么去看人工智能,特别是这一波大模型的发展。大模型这一次出来以后对于AIGC、自动驾驶、科学计算,特别是我最感兴趣的机器人方向有着非常大的促进作用,作为电子系的系主任,每年9月份我都会在新生的迎新活动上讲话。在跟这200多名新生去分析未来从事行业的时候,其中有一个方向就会去讲机器人这个方面。这几年的高考人数还比较多,竞争是比较激烈的,因为当年是1800万的出生人口,到了去年和前年大概是800万左右的出生人口。我每次问他们说,同学们你们看一看我今年40多岁了,为祖国可以健康工作到50岁,甚至更多,等我到了七八十岁,也就是30年以后谁来照顾我是一个问题。那个时候人不够了,2050年赡养老人的压力是很大的,因为我们的GDP要发展,GDP等于什么?GDP=人数×人均GDP。现在中国经济发展的基本特征由高速增长转向高质量发展,那就提高人均GDP,但是如果人口降了,光提高人均GDP可能也赶不上,所以我们还是要大力推动机器人这个行业。我们可以看见中国服务机器人的产量已经在进一步提升,当然目前还是完成一些相对简单的任务,但已经开始深入千家万户。我以这个举例子,我们可以看到在通用机器人,包括人形机器人领域,一方面需要很多决策算法,我们可以看到状态空间不断地增大,用更大的算力和更好的算法能够解决更复杂的问题。另外一个层面,感知的能力在不断升级。可以看到我们这几年包括像Google、特斯拉这样的企业,实践过程中都是把感知、决策和控制集合在一起了,这是一个很大的系统。在这么大的系统里面,要用端到端的大模型,在其中实时进行操作,这对于计算量、响应速度、吞吐量都有很高的要求,所以这一类应用场景就给我们提出了“硬件怎么样能够跟上软件的发展”,甚至是“支撑软件的发展”的更高要求。从我的角度来看,我觉得主要有三个方面的挑战:第一,当然这也是面向中国大陆非常重要的挑战,从2022年到2023年两次的法案对算力的限制、对芯片的限制。 第二,现在推理和包括训练的成本是非常高的,在座的各位做创业也好、大公司也好,都会面临这样的一个挑战。第三,我们中国其实是比较独特的一类算法和芯片的生态,怎么样能够去更好地推动这样一个生态的发展,其实也是现在面临的一个很重要的挑战。首先,芯片和算力。芯片是我最了解的东西,从设计、制造,到测试封装,最后造出来,这里面中国的产业链并不是完全自主可控的,有很多环节需要进口,比如说EDA的软件最大的几家都是美国的,制造生产过程中的一些关键的材料、设备,其实中国都还在努力追赶的过程中。芯片的制造,包括刚才说了1017法案限制了我们芯片算力的密度,中国正在讨论1Tops/Watt的设计(就是每瓦能够提供1T次运算)。人脑的功耗大概是20瓦,在有一些任务上我们类比了一下则需要1000Tops/Watt这样的指标,那怎么样通过芯片做到Tops,甚至几百T几千Tops/Watt?在过去几年里,计算芯片从大概1Gops/Watt做到了10Tops/W、甚至100Tops/W,通过尺寸微缩的红利,实现了各种各样的专用处理器。现在我们开始关注做近存储计算和存内计算,因为数据搬运比数据计算更费电了,搬数(带宽)更加复杂;再进一步,我们也在看有没有不用硅基芯片,不用微电子,而用光电子去做的芯片,这是我们所关注的一系列研究方向。PPT右侧是讲机器人领域,机器人是异构的,这里我们不展开。总的来说,我们有各种各样的路径,比如说通过设计新的芯片架构,能够提高每瓦特的算力。另外一个方面,其实大模型的发展需要很高的互联的带宽。从推导出的数据中,我希望大家能够看到很多信息,比如说通信量,根据实验室理论计算,GPT-3所需要的互联带宽是1380TB/s,一个英伟达的卡它自带的600GB/s互联带宽与这一需求之间的差距是很大的,这也是为什么需要把很多很多块卡联在一起,才能把这个模型训练出来。现在计算性能的提升比带宽的增速要大,目前在中国的互联应用场景里,怎么样把机器连起来是非常费劲的。算力受限之后,比如训练GPT-4是用到2.4万张A100 GPU(当我们进口的单卡能力受限了,而且我们自己的芯片能力本身不如A100的话),那么我可能需要10万块算力卡才能完成这些计算工作。但这10万块卡怎么互联在一起做训练,这件事本身是对中国的AI系统能力提出的一个更高的、更难的需求,需要在系统层面进行突破。大家简单算一下,哪怕每一个卡或者每一台机器出错的概率是万分之一,但连成十万次的出错概率,一定远大于连成一万次。出错的概率如此大,这是一个非常难的课题。其次,就是成本。现在我们也看到了很多厂商都在做自己的模型,不管是做基础模型,还是训一个自己的垂类模型,成本都是非常不友好的。所以我也很期待看一看张拳石老师(下一位演讲者),看看他们是怎么在学校里面做大模型的研究的。同时我们更需要跟工业界合作,因为训练的成本确实是一个非常严肃的问题。那么推理会好一些吗?我们发现也不会。我们看到一些数据:按不同模型的类型、用户数来算,算力费用=日活用户×平均token使用数×单位token算力费用,自建算力集群的情况下,每天的费用是690万。如果你要调用现有API来运营,费用会更高。所以如果GPT-4 Turbo每天服务10亿的活跃用户,每年算力成本是两千多个亿,虽然这个数今天不一定准确,但是数量级在这。我相信绝大多数中国的公司,收入是在亿这个量级,肯定不是在千亿这个量级,所以怎么样去打平这个成本是非常难的一件事情。同样,对于一个个体来说,如果一个用户平均每天浏览10篇文章,一年的成本可能就是5000块钱,试想谁愿意花5000块钱来使用这样一个单一功能?一定是不愿意的。所以我们在思考大模型的成本,举一些例子,比如《三体3》全书40万字,如果我用GPT-4 Turbo来去做估算,一次就需要大概几十块人民币。这个量级让我觉得这件事情不是刚需,可能一块钱、一毛钱甚至一分钱以下才是我可以接受的。还有电商购物,我为了让大家买一个100块钱以内的东西,要花几十块钱劝他买或者帮他买吗?这是不可能的。成本是大模型推理未来必须要考虑的,降低成本才有希望实现大规模商业应用。我是一个做硬件的,我的角度去看,垂类模型一定是可以做到更小的。不需要千亿级别参数,通过优化模型这一侧的大小,我们可以通过降低每一次调用的计算次数或存储的次数,进而降低处理器的功耗;此外,我们会发现还有一些可能的方法,比如算法方面的优化、对于模型本身的算子的优化;来到云端,我们还可以做错峰把闲置的算力用起来;以及我自己最擅长的芯片硬件层面,在端侧做一类能够跑大模型的硬件,专用于大模型的高效计算等。通过这一整套从算法到芯片的协同优化工作,大家想一想如果成本能够降低4个数量级的话,从100块到1分钱级别,我相信很多习以为常的事情就都可以用大模型了。最后,是生态。首先芯片层,绝大多数的人会直接在英伟达上搭建环境,很多西方国家也很郁闷,也被英伟达生态卡着。所以有些人试图摆脱这种生态束缚,比如Google要做TPU,以更低的价格来服务更多的用户,但它的用户目前还相对少。AMD最近发布了一款MI300,使股价一下子提高了很多,因为它有可能能够跟英伟达PK了。其次是模型层,有很多模型,这一点大家都是一样的。然后中间层,在美国至少大家会分层去做软件服务以及一些软件类的收费,所以在软件中间层,可以看到已经有一批企业在为这件事情努力,帮助这些模型公司把算力发挥到极致。而在中国,模型层我们有“百模大战”,芯片层是我比较熟悉的,有看到一些芯片厂商,有十家到二十家还不错的企业,正在努力突破巨头的束缚,也有一些初创企业正在融资。在模型层和芯片层之间,怎么做高效的部署,也是一个非常重要的话题。我们也在思考,是不是应该有一类相对统一的中间层,能够支持长文本、能够做到更高的性价比、能够做到一键部署,并且里面有一些工具可以辅助算法和应用的开发商们。把算法压缩、算子优化包括自动编译全都囊括在内,这样做成的一类中间层,是有望把M个大模型和N个硬件更好地匹配起来的,这是一个理想,我们做理想的同时就得去找资金,一块来干这个事情。所以最近我们也在努力地做这样一个中间层,作为在云端优化不同的中国的(当然也有英伟达和AMD)算力的第一步,以此来支撑更多不同的模型。中国的大模型生态,最后是需要应用、模型、算法框架开发平台和基础设施联合起来做的,今天我看了看日程,绝大部分不是讨论硬件的,所以把我硬件放在第一个,谢谢知乎举办了这么好一个活动,将大家汇聚到一起,去思考大模型应该怎么走。谢谢! 来源:知乎 www.zhihu.com 作者:汪玉 【知乎日报】千万用户的选择,做朋友圈里的新鲜事分享大牛。 点击下载

以下是我在知乎AI先行者沙龙活动上的演讲实录,应线上线下听众们的诉求,现将演讲内容分享出来:
非常荣幸,能够在这里分享我自己对于大模型这个行业目前的一些认识。首先说一下我,我是清华大学电子工程系的教授,今天在座各位可能做算法和应用比较多。但我是一位做硬件、芯片和基础软件更多的学者,以及有过一定的创业经历,所以从我的角度来给大家去讲一讲我怎么去看人工智能,特别是这一波大模型的发展。
大模型这一次出来以后对于AIGC、自动驾驶、科学计算,特别是我最感兴趣的机器人方向有着非常大的促进作用,作为电子系的系主任,每年9月份我都会在新生的迎新活动上讲话。在跟这200多名新生去分析未来从事行业的时候,其中有一个方向就会去讲机器人这个方面。这几年的高考人数还比较多,竞争是比较激烈的,因为当年是1800万的出生人口,到了去年和前年大概是800万左右的出生人口。我每次问他们说,同学们你们看一看我今年40多岁了,为祖国可以健康工作到50岁,甚至更多,等我到了七八十岁,也就是30年以后谁来照顾我是一个问题。那个时候人不够了,2050年赡养老人的压力是很大的,因为我们的GDP要发展,GDP等于什么?GDP=人数×人均GDP。现在中国经济发展的基本特征由高速增长转向高质量发展,那就提高人均GDP,但是如果人口降了,光提高人均GDP可能也赶不上,所以我们还是要大力推动机器人这个行业。
我们可以看见中国服务机器人的产量已经在进一步提升,当然目前还是完成一些相对简单的任务,但已经开始深入千家万户。我以这个举例子,我们可以看到在通用机器人,包括人形机器人领域,一方面需要很多决策算法,我们可以看到状态空间不断地增大,用更大的算力和更好的算法能够解决更复杂的问题。另外一个层面,感知的能力在不断升级。可以看到我们这几年包括像Google、特斯拉这样的企业,实践过程中都是把感知、决策和控制集合在一起了,这是一个很大的系统。
在这么大的系统里面,要用端到端的大模型,在其中实时进行操作,这对于计算量、响应速度、吞吐量都有很高的要求,所以这一类应用场景就给我们提出了“硬件怎么样能够跟上软件的发展”,甚至是“支撑软件的发展”的更高要求。
从我的角度来看,我觉得主要有三个方面的挑战:
第一,当然这也是面向中国大陆非常重要的挑战,从2022年到2023年两次的法案对算力的限制、对芯片的限制。
第二,现在推理和包括训练的成本是非常高的,在座的各位做创业也好、大公司也好,都会面临这样的一个挑战。
第三,我们中国其实是比较独特的一类算法和芯片的生态,怎么样能够去更好地推动这样一个生态的发展,其实也是现在面临的一个很重要的挑战。
首先,芯片和算力。
芯片是我最了解的东西,从设计、制造,到测试封装,最后造出来,这里面中国的产业链并不是完全自主可控的,有很多环节需要进口,比如说EDA的软件最大的几家都是美国的,制造生产过程中的一些关键的材料、设备,其实中国都还在努力追赶的过程中。
芯片的制造,包括刚才说了1017法案限制了我们芯片算力的密度,中国正在讨论1Tops/Watt的设计(就是每瓦能够提供1T次运算)。人脑的功耗大概是20瓦,在有一些任务上我们类比了一下则需要1000Tops/Watt这样的指标,那怎么样通过芯片做到Tops,甚至几百T几千Tops/Watt?在过去几年里,计算芯片从大概1Gops/Watt做到了10Tops/W、甚至100Tops/W,通过尺寸微缩的红利,实现了各种各样的专用处理器。现在我们开始关注做近存储计算和存内计算,因为数据搬运比数据计算更费电了,搬数(带宽)更加复杂;再进一步,我们也在看有没有不用硅基芯片,不用微电子,而用光电子去做的芯片,这是我们所关注的一系列研究方向。PPT右侧是讲机器人领域,机器人是异构的,这里我们不展开。总的来说,我们有各种各样的路径,比如说通过设计新的芯片架构,能够提高每瓦特的算力。
另外一个方面,其实大模型的发展需要很高的互联的带宽。从推导出的数据中,我希望大家能够看到很多信息,比如说通信量,根据实验室理论计算,GPT-3所需要的互联带宽是1380TB/s,一个英伟达的卡它自带的600GB/s互联带宽与这一需求之间的差距是很大的,这也是为什么需要把很多很多块卡联在一起,才能把这个模型训练出来。现在计算性能的提升比带宽的增速要大,目前在中国的互联应用场景里,怎么样把机器连起来是非常费劲的。
算力受限之后,比如训练GPT-4是用到2.4万张A100 GPU(当我们进口的单卡能力受限了,而且我们自己的芯片能力本身不如A100的话),那么我可能需要10万块算力卡才能完成这些计算工作。但这10万块卡怎么互联在一起做训练,这件事本身是对中国的AI系统能力提出的一个更高的、更难的需求,需要在系统层面进行突破。
大家简单算一下,哪怕每一个卡或者每一台机器出错的概率是万分之一,但连成十万次的出错概率,一定远大于连成一万次。出错的概率如此大,这是一个非常难的课题。
其次,就是成本。
现在我们也看到了很多厂商都在做自己的模型,不管是做基础模型,还是训一个自己的垂类模型,成本都是非常不友好的。所以我也很期待看一看张拳石老师(下一位演讲者),看看他们是怎么在学校里面做大模型的研究的。同时我们更需要跟工业界合作,因为训练的成本确实是一个非常严肃的问题。
那么推理会好一些吗?我们发现也不会。我们看到一些数据:按不同模型的类型、用户数来算,算力费用=日活用户×平均token使用数×单位token算力费用,自建算力集群的情况下,每天的费用是690万。如果你要调用现有API来运营,费用会更高。所以如果GPT-4 Turbo每天服务10亿的活跃用户,每年算力成本是两千多个亿,虽然这个数今天不一定准确,但是数量级在这。我相信绝大多数中国的公司,收入是在亿这个量级,肯定不是在千亿这个量级,所以怎么样去打平这个成本是非常难的一件事情。同样,对于一个个体来说,如果一个用户平均每天浏览10篇文章,一年的成本可能就是5000块钱,试想谁愿意花5000块钱来使用这样一个单一功能?一定是不愿意的。
所以我们在思考大模型的成本,举一些例子,比如《三体3》全书40万字,如果我用GPT-4 Turbo来去做估算,一次就需要大概几十块人民币。这个量级让我觉得这件事情不是刚需,可能一块钱、一毛钱甚至一分钱以下才是我可以接受的。还有电商购物,我为了让大家买一个100块钱以内的东西,要花几十块钱劝他买或者帮他买吗?这是不可能的。成本是大模型推理未来必须要考虑的,降低成本才有希望实现大规模商业应用。
我是一个做硬件的,我的角度去看,垂类模型一定是可以做到更小的。不需要千亿级别参数,通过优化模型这一侧的大小,我们可以通过降低每一次调用的计算次数或存储的次数,进而降低处理器的功耗;此外,我们会发现还有一些可能的方法,比如算法方面的优化、对于模型本身的算子的优化;来到云端,我们还可以做错峰把闲置的算力用起来;以及我自己最擅长的芯片硬件层面,在端侧做一类能够跑大模型的硬件,专用于大模型的高效计算等。
通过这一整套从算法到芯片的协同优化工作,大家想一想如果成本能够降低4个数量级的话,从100块到1分钱级别,我相信很多习以为常的事情就都可以用大模型了。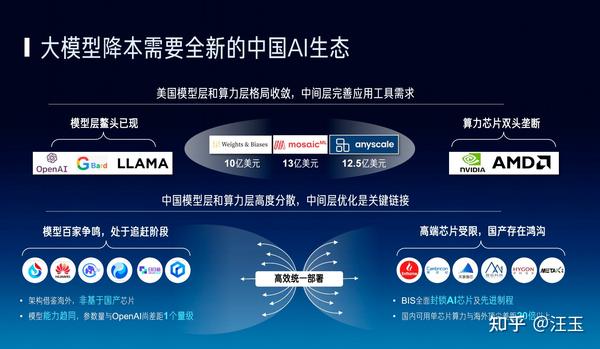
最后,是生态。
首先芯片层,绝大多数的人会直接在英伟达上搭建环境,很多西方国家也很郁闷,也被英伟达生态卡着。所以有些人试图摆脱这种生态束缚,比如Google要做TPU,以更低的价格来服务更多的用户,但它的用户目前还相对少。AMD最近发布了一款MI300,使股价一下子提高了很多,因为它有可能能够跟英伟达PK了。其次是模型层,有很多模型,这一点大家都是一样的。然后中间层,在美国至少大家会分层去做软件服务以及一些软件类的收费,所以在软件中间层,可以看到已经有一批企业在为这件事情努力,帮助这些模型公司把算力发挥到极致。
而在中国,模型层我们有“百模大战”,芯片层是我比较熟悉的,有看到一些芯片厂商,有十家到二十家还不错的企业,正在努力突破巨头的束缚,也有一些初创企业正在融资。在模型层和芯片层之间,怎么做高效的部署,也是一个非常重要的话题。
我们也在思考,是不是应该有一类相对统一的中间层,能够支持长文本、能够做到更高的性价比、能够做到一键部署,并且里面有一些工具可以辅助算法和应用的开发商们。把算法压缩、算子优化包括自动编译全都囊括在内,这样做成的一类中间层,是有望把M个大模型和N个硬件更好地匹配起来的,这是一个理想,我们做理想的同时就得去找资金,一块来干这个事情。所以最近我们也在努力地做这样一个中间层,作为在云端优化不同的中国的(当然也有英伟达和AMD)算力的第一步,以此来支撑更多不同的模型。
中国的大模型生态,最后是需要应用、模型、算法框架开发平台和基础设施联合起来做的,今天我看了看日程,绝大部分不是讨论硬件的,所以把我硬件放在第一个,谢谢知乎举办了这么好一个活动,将大家汇聚到一起,去思考大模型应该怎么走。
谢谢!
来源:知乎 www.zhihu.com
作者:汪玉
【知乎日报】千万用户的选择,做朋友圈里的新鲜事分享大牛。
点击下载