














![【XGAMER 元代碼 - 主題曲: 寂聲 (日本語)】 日語歌詞: Verse 1 目を閉じたいだけ 気にしていないふうに... 内の信念は 正しくない 風と海[真実を]告げて 失くしない 幻がなくて Chorus: 徹夜で戦った 日差し...](https://scontent.fdsa2-1.fna.fbcdn.net/v/t15.5256-10/336656091_162215126698640_3843734250325810940_n.jpg?stp=dst-jpg_p600x600&_nc_cat=102&ccb=1-7&_nc_sid=08861d&_nc_ohc=kQATFNXRo-kAX9EeaEw&_nc_ht=scontent.fdsa2-1.fna&oh=00_AfCnUOW2Bv6j_cgJTtG7RU2CcjvsthXu1Pj6XjGBE5943w&oe=641C69A7#)




































如何使用 Embedding 提升回答质量?
summary使用 embedding 计算语料和提问的相似度,在 prompt 里补充相对准确的上下文语料 (prompt design),来获取更准确的回答OpenAI 提供了 Completion API 来实现问答的功能。但是它只提供了固定的 models,用户不能修改他们的 model,不过可以使用 fine-tune 来生成自己的 model。但是如果我们有自己的语料库,如何才能让 GPT-3 根据我们的语料来生成正确的答案呢?为什么不直接用 fine-tune为了提高问答质量, Open AI 提供了 fine-tune 可以对 prompt 和 completion 进行调优,虽然 fine-tune 可以稍微提升质量,让 API 更好的理解你的 prompt ,并输出更符合预期的结果,但是它主要是为了节省每次 completion 提供相同 prompt 的 tokens,把类似的 prompt 可以训练成: 只需要更改具体问题,而不用重复写 context、example 。比如我们训练{"prompt":"Company: BHFF insurance\nProduct: allround insurance\nAd:One stop shop for all your insurance needs!\nSupported:", "completion":" yes"}{"prompt":"Company: Loft conversion specialists\nProduct: -\nAd:Straight teeth in weeks!\nSupported:", "completion":" no"}后面我们只需要提供 promptCompany: Reliable accountants LtdProduct: Personal Tax helpAd:Best advice in town!Supported:OpenAI 就会利用 fine-tune 学到的知识,自动返回 "yes" 或者 "no"如果不进行 fine-tune,那么需要在每次 completion 都需要给 GPT 一个例子Examples:*Company: BHFF insuranceProduct: allround insuranceAd:One stop shop for all your insurance needs!Supported: yes *Company: Loft conversion specialistsProduct: -Ad:Straight teeth in weeks!Supported: no Q:Company: Reliable accountants LtdProduct: Personal Tax helpAd:Best advice in town!Supported:可见,fune-tune 可以节省大量的请求 tokens,以减少使用费用(按 tokens 计费)使用 Embedding目前为了提高问答「准确率」,有两个优化方向增加训练集增加提问上下文,答案就在其中OpenAI 是不允许用户来训练数据的,他的 model 是固定且通用的。所以增加训练集数据并不可行。我们只能使用方法 2 :提供提问上下文(context)。在 OpenAI GPT-3 API 提供的能力中,可以在 prompt 中增加上下文,来提高 completion 准确率。但是我们如何从自己的语料库(由语料片段组成)中,找到和提问相关(答案需要在上下文中)的 context 呢?OpenAI 提供了 Embedding 的接口,可以用 input (输入一段文字)来计算一坨 embedding 向量值。 (https://platform.openai.com/docs/api-reference/embeddings/create)我们可以通过将「语料片段的向量」与「问题的向量」取「最相似的向量」,来判断问题和语料片段的相似(similarity)度,这样我们在 prompt 里,把最相似的语料片段作为 context 放进 prompt ,就可以得到最正确的 completion。相似度计算官方推荐使用 https://en.wikipedia.org/wiki/Cosine_similarity 余弦相似度embedding 结合 fine-tuneembedding 可以将语料和提问结合,而 fine-tune 可以将我们的输入输出进行训练,让 GPT-3 更好的理解我们的提问、上下文关系。从而创建符合我们需求的服务。综上,使用 embedding 计算语料和提问的相似度,在 prompt 里补充相对准确的上下文,来获取更准确的回答。参考资料:1 一个简要的 Fine-tune 介绍 https://harishgarg.com/writing/how-to-fine-tune-gpt-3-api/2 用 embedding 问答 https://github.com/openai/openai-cookbook/blob/main/examples/Question_answering_using_embeddings.ipynb 来源:知乎 www.zhihu.com 作者:人类观察所主任 【知乎日报】千万用户的选择,做朋友圈里的新鲜事分享大牛。 点击下载

summary
使用 embedding 计算语料和提问的相似度,在 prompt 里补充相对准确的上下文语料 (prompt design),来获取更准确的回答
OpenAI 提供了 Completion API 来实现问答的功能。但是它只提供了固定的 models,用户不能修改他们的 model,不过可以使用 fine-tune 来生成自己的 model。
但是如果我们有自己的语料库,如何才能让 GPT-3 根据我们的语料来生成正确的答案呢?
为什么不直接用 fine-tune
为了提高问答质量, Open AI 提供了 fine-tune 可以对 prompt 和 completion 进行调优,
虽然 fine-tune 可以稍微提升质量,让 API 更好的理解你的 prompt ,并输出更符合预期的结果,
但是它主要是为了节省每次 completion 提供相同 prompt 的 tokens,把类似的 prompt 可以训练成: 只需要更改具体问题,而不用重复写 context、example 。
比如我们训练
{"prompt":"Company: BHFF insurance\nProduct: allround insurance\nAd:One stop shop for all your insurance needs!\nSupported:", "completion":" yes"}{"prompt":"Company: Loft conversion specialists\nProduct: -\nAd:Straight teeth in weeks!\nSupported:", "completion":" no"}后面我们只需要提供 prompt
Company: Reliable accountants LtdProduct: Personal Tax helpAd:Best advice in town!Supported:OpenAI 就会利用 fine-tune 学到的知识,自动返回 "yes" 或者 "no"
如果不进行 fine-tune,那么需要在每次 completion 都需要给 GPT 一个例子
Examples:*Company: BHFF insuranceProduct: allround insuranceAd:One stop shop for all your insurance needs!Supported: yes *Company: Loft conversion specialistsProduct: -Ad:Straight teeth in weeks!Supported: no Q:Company: Reliable accountants LtdProduct: Personal Tax helpAd:Best advice in town!Supported:可见,fune-tune 可以节省大量的请求 tokens,以减少使用费用(按 tokens 计费)
使用 Embedding
目前为了提高问答「准确率」,有两个优化方向
- 增加训练集
- 增加提问上下文,答案就在其中
OpenAI 是不允许用户来训练数据的,他的 model 是固定且通用的。所以增加训练集数据并不可行。
我们只能使用方法 2 :提供提问上下文(context)。
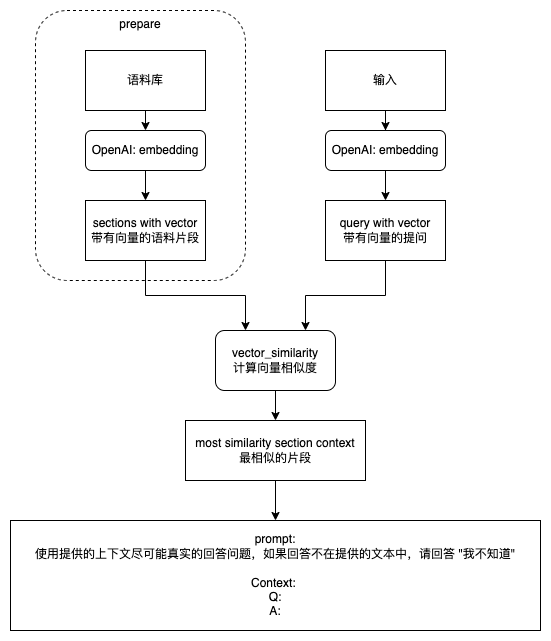
在 OpenAI GPT-3 API 提供的能力中,可以在 prompt 中增加上下文,来提高 completion 准确率。
但是我们如何从自己的语料库(由语料片段组成)中,找到和提问相关(答案需要在上下文中)的 context 呢?
OpenAI 提供了 Embedding 的接口,可以用 input (输入一段文字)来计算一坨 embedding 向量值。
(https://platform.openai.com/docs/api-reference/embeddings/create)
我们可以通过将「语料片段的向量」与「问题的向量」取「最相似的向量」,来判断问题和语料片段的相似(similarity)度,
这样我们在 prompt 里,把最相似的语料片段作为 context 放进 prompt ,就可以得到最正确的 completion。
相似度计算官方推荐使用 https://en.wikipedia.org/wiki/Cosine_similarity 余弦相似度
embedding 结合 fine-tune
embedding 可以将语料和提问结合,而 fine-tune 可以将我们的输入输出进行训练,让 GPT-3 更好的理解我们的提问、上下文关系。从而创建符合我们需求的服务。
综上,使用 embedding 计算语料和提问的相似度,在 prompt 里补充相对准确的上下文,来获取更准确的回答。
参考资料:
1 一个简要的 Fine-tune 介绍 https://harishgarg.com/writing/how-to-fine-tune-gpt-3-api/
2 用 embedding 问答 https://github.com/openai/openai-cookbook/blob/main/examples/Question_answering_using_embeddings.ipynb
来源:知乎 www.zhihu.com
作者:人类观察所主任
【知乎日报】千万用户的选择,做朋友圈里的新鲜事分享大牛。
点击下载