















![【XGAMER 元代碼 - 主題曲: 寂聲 (日本語)】 日語歌詞: Verse 1 目を閉じたいだけ 気にしていないふうに... 内の信念は 正しくない 風と海[真実を]告げて 失くしない 幻がなくて Chorus: 徹夜で戦った 日差し...](https://scontent.fdsa2-1.fna.fbcdn.net/v/t15.5256-10/336656091_162215126698640_3843734250325810940_n.jpg?stp=dst-jpg_p600x600&_nc_cat=102&ccb=1-7&_nc_sid=08861d&_nc_ohc=kQATFNXRo-kAX9EeaEw&_nc_ht=scontent.fdsa2-1.fna&oh=00_AfCnUOW2Bv6j_cgJTtG7RU2CcjvsthXu1Pj6XjGBE5943w&oe=641C69A7#)




































基于方言之间的预测相似度进行方言聚类
问题去年,我在基于自编码器的方言祖语音系嵌入中尝试根据某个字在多个方言点中的读音对字进行聚类,实际上,由于这些读音构成了以字为行、以方言点为列的矩阵,一个自然的推广就是用类似的方法对方言点也进行聚类,借助聚类的结果辅助考察方言之间的亲缘关系。但是方言点和字音不同的是,方言之间相似不一定蕴含方言字音之间相同或相似。举个极端的情况,如果 a 方言读 x 的字在 b 方言无例外都读 y,同时 a 方言读 y 的字在 b 方言无例外都读 x,从表面的音值看 a、b 两种方言是截然相反的,但是在音类上却极其相似,因为两者可以通过非常简单的规则相互推导出来。甚至有时这种音值的差异不是方言语音本身造成的,而仅仅是不同来源的材料处理的偏好不同造成的。比如广州和湛江的方言相当接近,两者都有一套咝音,这套咝音在不同的人、不同的条件有不同的变体,由于记音宽严的差别,或者由于其他音系以外的因素,《珠江三角洲方言调查报告》把广州的咝音记成 s,而《粤西湛茂地区粤语语音研究》把湛江对应的咝音记成 ʃ。如果不加处理地直接对比原始字音,其结果就是大量的字音不同,从而得出广州和湛江的方言差异很大的结论。这是比较方法以外的、材料层面的因素对分析结果造成的影响,必须先行消除。数学描述方言比较关心的是音类而非音值的相关性。具体地说,一个方言的音类可以表示成由若干个等价类构成的集合每个等价类 是字的集合,同类的所有字都同音。 所谓同音,是指方言的字音可以表示为从字集合到音节集合的映射 或写成函数的形式其中 为所有方言字的集合, 为方言所有音节的集合。如 。一组字在某个方言的同音关系上构成等价类,是指这些字通过该方言的上述映射函数都映射到相同音节这些等价类构成了对方言字集合 的一个划分,只与映射函数的关系有关,而与映射结果的具体值无关。如果方言 a 的所有音类划分和方言 b 相同, ,则说 a 音类和 b 音类相同,方言的具体音值不影响比较结果。需要说明的是上文的描述及下文的讨论中提到的字并不是指字符层面的汉字,而是指隐含在汉字表面下的不可拆分的字音单位,对汉语来说,通常对应于一个单音节语素。之所以需要做这么细微的区分是因为存在一字多音的情况,有些多音字对应了不同的义项,这些是大部分方言共有的,还有一些方言中的一字多音是由于存在多个语音层次造成的。确定 a 方言的某个字某个音对应于 b 方言的哪个字哪个音,或简单地称之为字音对齐,是一项极其繁琐的工作,这里不再展开。相似度计算方法上文通过字音映射函数以及集合划分定义了方言音类,在此基础上,在 的情况下,怎样度量 和 的相似性呢?一种角度是概率分布的观点。在概率观点下,音值 作为随机变量形成了一个离散的分布,其概率函数为其中 取平均分布对于确定的字音映射函数来说在上述模型下,方言 a 和 b 音类的相似度表现为音值的条件分布,极端情况下,如果 a 方言的 x 总是对应 b 方言的 y,则 ,反之亦然。 最简单的方法是使用 和 的共现频率来估计条件概率。条件熵@王赟 Maigo 在9978 方言音系/韵母“存古度”的一种定量描述中提出了一种使用条件熵来度量方言之间的这种分布相似度的方法。条件熵(conditional entropy) 量化了随机变量 的出现为随机变量 提供了多少确定性。 越小, 预测 的能力越强。条件熵是单向的,即 。这很好理解,a 方言能推导 b 方言,反过来不一定成立。为了得到对称性,使用作为 a、b 方言之间的距离。对此直观的解释是,如果 a 方言可以预测 b 方言,同时 b 方言也可以预测 a 方言,那么这两种方言是相似的。条件熵作为距离有一个很好的性质即任一方言到它自己的距离为0。在实际操作中,统计的粒度细到音节会使统频率数据过于稀疏,降低结果可信度,比如说某个音节辖字极少,其中某个字由于偶然的原因读音不规则,或者仅仅由于使用的材料没有收录某个字的读音,都会大大影响统计出的概率。为了提高结果健壮性,对条件熵 切分为声母、韵母、声调作一些近似,把 拆分成声母、韵母、声调的三元组 分别计算条件熵。 上式最后一步的近似的考虑为,存在这样一种情况,a 方言的声母不能预测 b 方言的声母,但是 a 方言的声母加韵母、或者声母加声调能预测 b 方言的声母,只统计声母之间的条件熵会这种预测能力抹杀掉。例如广州的 p 对应上海的 p、b,单独根据广州的 p 不能预测上海是 p 还是 b,但是再增加考虑声调是阴调还是阳调其实是可以预测的。基于这一点,分别统计 a 方言声母和韵母、声母和声调联合分布对 b 方言声母的条件熵,取其中较小者。举 为例其中 分别表示字到声母、韵母的映射函数。上式的条件概率可以通过统计样本的频率估算得到。卡方检验本质上,上述方法中的互信息量度量的是方言之间预测的能力,因此可以尝试使用其他度量指标来代替,比如说特征选择中用的比较多的卡方检验(chi-square test)。卡方检验的思路是假设 和 是独立随机变量,由此它们分组统计共现得到的 统计量符合自由度为 的卡方分布其中 表示每组期望出现的频次,一般通过统计频率估计, 表示实际观察到的频次,自由度 由分组数量得到。然后根据卡方分布的累积分布函数计算 对应的剩余概率 , 越大, 越小,说明实际情况偏离假设越多, 和 越不可能相互独立,或者反过来说, 和 越相关。理论上说,由于不同方言对的自由度 不同,在进行方言之间相似度比较时,应该比较置信度 而不是直接比较 值。但由于方言之间的相关性足够显著,即使差别很大的方言之间也是如此,统计出来的 值普遍很大,导致对应的 值下溢为0,无法使用。另一方面这些 的自由度 也足够大,根据卡方分布的定义及中心极限定理,当 趋向正无穷时, 趋向于高斯分布标准化之后从而允许比较 值的大小,方言之间的 值越大,表明越相似。为了降低统计数据的稀疏性,采用和条件熵类似的、 分声母、韵母、声调统计 $\chi^2$ 的处理方法。所不同的是,卡方检验对于 和 是对称的。为了保持这种对称性,在拆分统计共现矩阵的时候对 和 的处理也是对称的,即统计 a 方言的声母韵母组合、和 b 方言的声母韵母组合的共现矩阵的 值,如此类推。最后取所有 值的平均。由此,方言两两之间的 值组成了方言之间的相似度矩阵 ,该矩阵经过一定的变换可以得到和条件熵相似的距离矩阵。数据以下统计分析使用中国语言资源保护工程采录展示平台的汉语方言字音数据,使用其中的方言老男单字音。共1287个方言点,每点收录1000个单字音,有些点一个字有多个音,有些点个别字缺数据。数据概览:方言点数单字数记录数128710041341693广州的数据样例:iidfinalsinitialtonename0001ɔt53多0002ɔth53拖0003ait22大0004ɔl21锣0005ɔtʃ35左对于方言中一字多音的情况,只取每个字在该方言的第一个读音,由于语保的数据格式规范,实际通过字 ID 做了字级别的对齐,而且往往把白读排在文读的前面,这样简单处理对结果的影响较小。相似度结果条件熵对上述方言两两一对使用上述卡方统计计算相似性,得到1278 × 1278的相似度矩阵和距离矩阵。对归一化的相似度矩阵分别使用 SVD、spectral embedding 和 t-SNE 降维,结果如下图所示,方言点在图中的距离越近表示越相似。 汉语方言条件熵降维散点图下图是从中抽样100个方言点的距离矩阵热度图。 抽样100方言条件熵相似度距离热度图把上述 spectral embedding 降维的结果映射到 CIE L*a*b 色度,然后标注在地图上,就得到方言相似度地图,方言点的颜色越接近表示越相似。 汉语方言相似度地图条件熵卡方相似度汉语方言卡方相似度降维散点图抽样100方言卡方距离热度图方言聚类得到方言点之间的相似度或距离矩阵之后,就可以对该矩阵实施各种聚类算法。由于矩阵不代表方言点在欧氏空间中的位置,因此常用的 K-means 算法不适用。但是可以把该矩阵看成图的邻接矩阵,因此可以应用各种针对图的聚类算法。下文主要描述根据条件熵计算的聚类结果,只在结果差异较大的时候,适当补充一些根据卡方相似度聚类的结果。需要说明的是,统计的方法受数据扰动影响较大,由于对原始方言读音数据进行了一次较大的清洗修正,部分聚类的结果对比之前放出的版本有较大不同。条件熵AP 聚类首先尝试对原始的相似度矩阵实施 AP 聚类(affinity propagation),但效果不理想,结果就不放出来了。谱聚类谱聚类(spectral clustering) 的思想是先把相似度矩阵表示的样本间相似度分解到低维的向量空间,再针对降维后的样本应用 K-means 等基于样本坐标的聚类算法。 使用归一化的相似度矩阵进行谱聚类,设置聚类数量为10,所得结果在不同的降维方法下表示如下图。 汉语方言谱聚类降维散点图条件熵10类聚类的结果在地图上的分布如下图。 汉语方言谱聚类地图条件熵10类从图中可以看到,聚类的结果总体体现了主流意见对汉语方言的分类,几大方言区的边界大致都落在聚类的边界上。在划分方言区的同一层级也划分了官话的大区,一些边界也和主流的划分一致。所不同的有以下几点:雷琼闽语单独分为一类,其他闽语为另一类赣语和客家话合为一类长江中游的湘语、一部分西南官话、一部分江淮官话、以及一部分赣语组成一个大类晋语从北方官话分出,但又和江淮官话合并了,少量应该是保留入声的西南官话也归这一类北方官话分为两类,一类大致就是中原官话加蓝银官话,另一类包含了北京官话、东北官话、冀鲁官话和胶辽官话,但两类的边界不完全和传统分区重合一些更细微的观察:无论桂南平话还是桂北平话都没有分立,归入粤语同一类湘南粤北土话大部分归入湘语一类,一部分归客家话,少数归粤语通泰归北吴层次聚类从传统观点来看,方言之间的亲缘关系是树状的,因此更适合使用层次聚类。层次聚类(hierarchical clustering) 每次按样本的距离和计算子树间距离的方法,取距离最小的两棵子树合并,直到所有样本合并为一类。由此生成的结果是树状图,树状图可以直观地表示出方言在什么层级被分开到不同的子树。层次聚类和树状图的不便之处是当方言数量很多的时候树状图会非常庞大,而且通常各个分支下面的方言数量会非常悬殊,不便于查看。需要注意的是层次聚类的结果不能直接等同于方言谱系树,层次聚类的依据是方言之间的距离而不是历史上的亲缘关系。虽然在计算方言相似度和距离时谨慎地消除了具体音值的影响,但方言音类相似度和亲缘关系之间的相关性还没经过严格检验,特别是存在方言接触产生的影响,使得相似度计算的结果和真实的亲缘关系不相称。因此在检验了具体方言的音类细节之前,层次聚类的结果只是作为参考。对距离矩阵实施层次聚类,最开始分出来的是湘西南、桂东北的一些很小的分支,以及零星的单点方言,第一次分离的大分支是闽语和非闽语。截取树状图的最根部如下图: 汉语方言树状图条件熵较早区分闽语和非闽语这一点符合部分学者认为闽语和其他方言关系较远的观点。然后非闽语在分出了徽语等较小的分支之后,其主体部分分成了南北两大支,南支包含吴语、大部分赣语、客家话、粤语和平话,另一支则依次分出一小部分赣语、湘语、一小部分江淮官话,最终官话的主体和晋语,超过样本半数的方言点,全部挤在剩余的一个末端分支上。下面是根据树状图分成64类的降维散点图和地图,在这个层级上,各大类大致沿着传统分区的边界划分,官话和晋语为一类,赣语、客家话、粤语、平话为一类,吴语为一类,而闽语已经细分到方言片一级了。汉语方言层次聚类降维散点图条件熵64类汉语方言层次聚类地图条件熵64类举其中方言数较少而分支比较丰富的闽语为例,下图是闽语方言之间的距离热度图: 汉语方言距离热度图条件熵闽语 闽南语和闽东语分别构成了两个大聚类中心,闽南内部的潮汕、漳州又构成了次一级的中心。而内陆闽语和雷琼闽语虽然数量也不少,但是和其他闽语的距离较
问题
去年,我在基于自编码器的方言祖语音系嵌入中尝试根据某个字在多个方言点中的读音对字进行聚类,实际上,由于这些读音构成了以字为行、以方言点为列的矩阵,一个自然的推广就是用类似的方法对方言点也进行聚类,借助聚类的结果辅助考察方言之间的亲缘关系。
但是方言点和字音不同的是,方言之间相似不一定蕴含方言字音之间相同或相似。举个极端的情况,如果 a 方言读 x 的字在 b 方言无例外都读 y,同时 a 方言读 y 的字在 b 方言无例外都读 x,从表面的音值看 a、b 两种方言是截然相反的,但是在音类上却极其相似,因为两者可以通过非常简单的规则相互推导出来。
甚至有时这种音值的差异不是方言语音本身造成的,而仅仅是不同来源的材料处理的偏好不同造成的。比如广州和湛江的方言相当接近,两者都有一套咝音,这套咝音在不同的人、不同的条件有不同的变体,由于记音宽严的差别,或者由于其他音系以外的因素,《珠江三角洲方言调查报告》把广州的咝音记成 s,而《粤西湛茂地区粤语语音研究》把湛江对应的咝音记成 ʃ。如果不加处理地直接对比原始字音,其结果就是大量的字音不同,从而得出广州和湛江的方言差异很大的结论。这是比较方法以外的、材料层面的因素对分析结果造成的影响,必须先行消除。
数学描述
方言比较关心的是音类而非音值的相关性。具体地说,一个方言的音类可以表示成由若干个等价类构成的集合
每个等价类 是字的集合,同类的所有字都同音。 所谓同音,是指方言的字音可以表示为从字集合到音节集合的映射
或写成函数的形式
其中 为所有方言字的集合,
为方言所有音节的集合。如
。一组字在某个方言的同音关系上构成等价类,是指这些字通过该方言的上述映射函数都映射到相同音节
这些等价类构成了对方言字集合 的一个划分,只与映射函数的关系有关,而与映射结果的具体值无关。如果方言 a 的所有音类划分和方言 b 相同,
,则说 a 音类和 b 音类相同,方言的具体音值不影响比较结果。
需要说明的是上文的描述及下文的讨论中提到的字并不是指字符层面的汉字,而是指隐含在汉字表面下的不可拆分的字音单位,对汉语来说,通常对应于一个单音节语素。之所以需要做这么细微的区分是因为存在一字多音的情况,有些多音字对应了不同的义项,这些是大部分方言共有的,还有一些方言中的一字多音是由于存在多个语音层次造成的。确定 a 方言的某个字某个音对应于 b 方言的哪个字哪个音,或简单地称之为字音对齐,是一项极其繁琐的工作,这里不再展开。
相似度计算方法
上文通过字音映射函数以及集合划分定义了方言音类,在此基础上,在 的情况下,怎样度量
和
的相似性呢?一种角度是概率分布的观点。在概率观点下,音值
作为随机变量形成了一个离散的分布,其概率函数为
其中 取平均分布
对于确定的字音映射函数来说
在上述模型下,方言 a 和 b 音类的相似度表现为音值的条件分布,极端情况下,如果 a 方言的 x 总是对应 b 方言的 y,则 ,反之亦然。 最简单的方法是使用
和
的共现频率来估计条件概率。
条件熵
@王赟 Maigo 在9978 方言音系/韵母“存古度”的一种定量描述中提出了一种使用条件熵来度量方言之间的这种分布相似度的方法。条件熵(conditional entropy) 量化了随机变量
的出现为随机变量
提供了多少确定性。
越小,
预测
的能力越强。
条件熵是单向的,即 。这很好理解,a 方言能推导 b 方言,反过来不一定成立。为了得到对称性,使用
作为 a、b 方言之间的距离。对此直观的解释是,如果 a 方言可以预测 b 方言,同时 b 方言也可以预测 a 方言,那么这两种方言是相似的。条件熵作为距离有一个很好的性质
即任一方言到它自己的距离为0。
在实际操作中,统计的粒度细到音节会使统频率数据过于稀疏,降低结果可信度,比如说某个音节辖字极少,其中某个字由于偶然的原因读音不规则,或者仅仅由于使用的材料没有收录某个字的读音,都会大大影响统计出的概率。为了提高结果健壮性,对条件熵 切分为声母、韵母、声调作一些近似,把
拆分成声母、韵母、声调的三元组
分别计算条件熵。
上式最后一步的近似的考虑为,存在这样一种情况,a 方言的声母不能预测 b 方言的声母,但是 a 方言的声母加韵母、或者声母加声调能预测 b 方言的声母,只统计声母之间的条件熵会这种预测能力抹杀掉。例如广州的 p 对应上海的 p、b,单独根据广州的 p 不能预测上海是 p 还是 b,但是再增加考虑声调是阴调还是阳调其实是可以预测的。基于这一点,分别统计 a 方言声母和韵母、声母和声调联合分布对 b 方言声母的条件熵,取其中较小者。
举 为例
其中 分别表示字到声母、韵母的映射函数。上式的条件概率可以通过统计样本的频率估算得到。
卡方检验
本质上,上述方法中的互信息量度量的是方言之间预测的能力,因此可以尝试使用其他度量指标来代替,比如说特征选择中用的比较多的卡方检验(chi-square test)。卡方检验的思路是假设 和
是独立随机变量,由此它们分组统计共现得到的
统计量符合自由度为
的卡方分布
其中 表示每组期望出现的频次,一般通过统计频率估计,
表示实际观察到的频次,自由度
由分组数量得到。然后根据卡方分布的累积分布函数计算
对应的剩余概率
,
越大,
越小,说明实际情况偏离假设越多,
和
越不可能相互独立,或者反过来说,
和
越相关。
理论上说,由于不同方言对的自由度 不同,在进行方言之间相似度比较时,应该比较置信度
而不是直接比较
值。但由于方言之间的相关性足够显著,即使差别很大的方言之间也是如此,统计出来的
值普遍很大,导致对应的
值下溢为0,无法使用。另一方面这些
的自由度
也足够大,根据卡方分布的定义及中心极限定理,当
趋向正无穷时,
趋向于高斯分布
标准化之后
从而允许比较 值的大小,方言之间的
值越大,表明越相似。
为了降低统计数据的稀疏性,采用和条件熵类似的、 分声母、韵母、声调统计 $\chi^2$ 的处理方法。所不同的是,卡方检验对于 和
是对称的。为了保持这种对称性,在拆分统计共现矩阵的时候对
和
的处理也是对称的,即统计 a 方言的声母韵母组合、和 b 方言的声母韵母组合的共现矩阵的
值,如此类推。最后取所有
值的平均。
由此,方言两两之间的 值组成了方言之间的相似度矩阵
,该矩阵经过一定的变换可以得到和条件熵相似的距离矩阵。
数据
以下统计分析使用中国语言资源保护工程采录展示平台的汉语方言字音数据,使用其中的方言老男单字音。共1287个方言点,每点收录1000个单字音,有些点一个字有多个音,有些点个别字缺数据。
数据概览:
| 方言点数 | 单字数 | 记录数 |
|---|---|---|
| 1287 | 1004 | 1341693 |
广州的数据样例:
| iid | finals | initial | tone | name |
|---|---|---|---|---|
| 0001 | ɔ | t | 53 | 多 |
| 0002 | ɔ | th | 53 | 拖 |
| 0003 | ai | t | 22 | 大 |
| 0004 | ɔ | l | 21 | 锣 |
| 0005 | ɔ | tʃ | 35 | 左 |
对于方言中一字多音的情况,只取每个字在该方言的第一个读音,由于语保的数据格式规范,实际通过字 ID 做了字级别的对齐,而且往往把白读排在文读的前面,这样简单处理对结果的影响较小。
相似度结果
条件熵
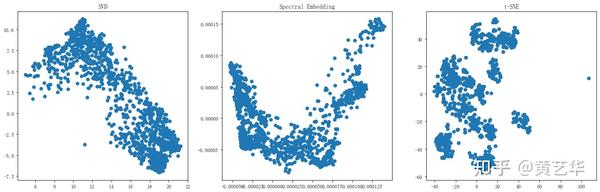
对上述方言两两一对使用上述卡方统计计算相似性,得到1278 × 1278的相似度矩阵和距离矩阵。对归一化的相似度矩阵分别使用 SVD、spectral embedding 和 t-SNE 降维,结果如下图所示,方言点在图中的距离越近表示越相似。 
下图是从中抽样100个方言点的距离矩阵热度图。 
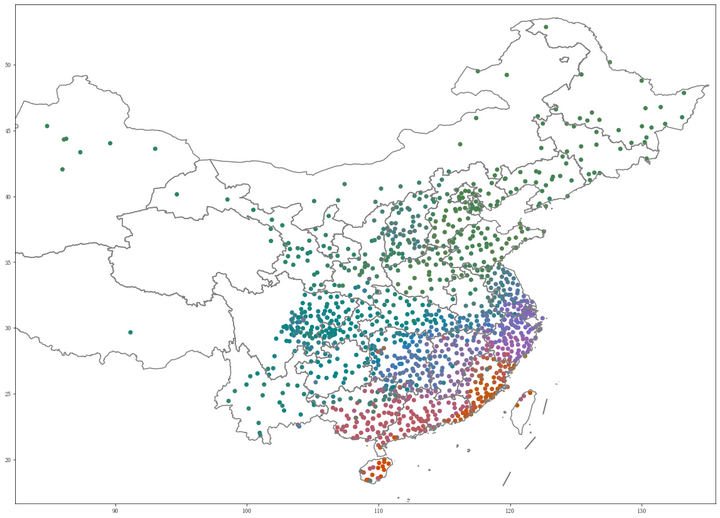
把上述 spectral embedding 降维的结果映射到 CIE L*a*b 色度,然后标注在地图上,就得到方言相似度地图,方言点的颜色越接近表示越相似。 
卡方相似度

方言聚类
得到方言点之间的相似度或距离矩阵之后,就可以对该矩阵实施各种聚类算法。由于矩阵不代表方言点在欧氏空间中的位置,因此常用的 K-means 算法不适用。但是可以把该矩阵看成图的邻接矩阵,因此可以应用各种针对图的聚类算法。
下文主要描述根据条件熵计算的聚类结果,只在结果差异较大的时候,适当补充一些根据卡方相似度聚类的结果。需要说明的是,统计的方法受数据扰动影响较大,由于对原始方言读音数据进行了一次较大的清洗修正,部分聚类的结果对比之前放出的版本有较大不同。
条件熵
AP 聚类
首先尝试对原始的相似度矩阵实施 AP 聚类(affinity propagation),但效果不理想,结果就不放出来了。
谱聚类
谱聚类(spectral clustering) 的思想是先把相似度矩阵表示的样本间相似度分解到低维的向量空间,再针对降维后的样本应用 K-means 等基于样本坐标的聚类算法。 使用归一化的相似度矩阵进行谱聚类,设置聚类数量为10,所得结果在不同的降维方法下表示如下图。 
聚类的结果在地图上的分布如下图。 
从图中可以看到,聚类的结果总体体现了主流意见对汉语方言的分类,几大方言区的边界大致都落在聚类的边界上。在划分方言区的同一层级也划分了官话的大区,一些边界也和主流的划分一致。所不同的有以下几点:
- 雷琼闽语单独分为一类,其他闽语为另一类
- 赣语和客家话合为一类
- 长江中游的湘语、一部分西南官话、一部分江淮官话、以及一部分赣语组成一个大类
- 晋语从北方官话分出,但又和江淮官话合并了,少量应该是保留入声的西南官话也归这一类
- 北方官话分为两类,一类大致就是中原官话加蓝银官话,另一类包含了北京官话、东北官话、冀鲁官话和胶辽官话,但两类的边界不完全和传统分区重合
一些更细微的观察:
- 无论桂南平话还是桂北平话都没有分立,归入粤语同一类
- 湘南粤北土话大部分归入湘语一类,一部分归客家话,少数归粤语
- 通泰归北吴
层次聚类
从传统观点来看,方言之间的亲缘关系是树状的,因此更适合使用层次聚类。层次聚类(hierarchical clustering) 每次按样本的距离和计算子树间距离的方法,取距离最小的两棵子树合并,直到所有样本合并为一类。由此生成的结果是树状图,树状图可以直观地表示出方言在什么层级被分开到不同的子树。层次聚类和树状图的不便之处是当方言数量很多的时候树状图会非常庞大,而且通常各个分支下面的方言数量会非常悬殊,不便于查看。
需要注意的是层次聚类的结果不能直接等同于方言谱系树,层次聚类的依据是方言之间的距离而不是历史上的亲缘关系。虽然在计算方言相似度和距离时谨慎地消除了具体音值的影响,但方言音类相似度和亲缘关系之间的相关性还没经过严格检验,特别是存在方言接触产生的影响,使得相似度计算的结果和真实的亲缘关系不相称。因此在检验了具体方言的音类细节之前,层次聚类的结果只是作为参考。
对距离矩阵实施层次聚类,最开始分出来的是湘西南、桂东北的一些很小的分支,以及零星的单点方言,第一次分离的大分支是闽语和非闽语。截取树状图的最根部如下图: 
较早区分闽语和非闽语这一点符合部分学者认为闽语和其他方言关系较远的观点。然后非闽语在分出了徽语等较小的分支之后,其主体部分分成了南北两大支,南支包含吴语、大部分赣语、客家话、粤语和平话,另一支则依次分出一小部分赣语、湘语、一小部分江淮官话,最终官话的主体和晋语,超过样本半数的方言点,全部挤在剩余的一个末端分支上。
下面是根据树状图分成64类的降维散点图和地图,在这个层级上,各大类大致沿着传统分区的边界划分,官话和晋语为一类,赣语、客家话、粤语、平话为一类,吴语为一类,而闽语已经细分到方言片一级了。

举其中方言数较少而分支比较丰富的闽语为例,下图是闽语方言之间的距离热度图: 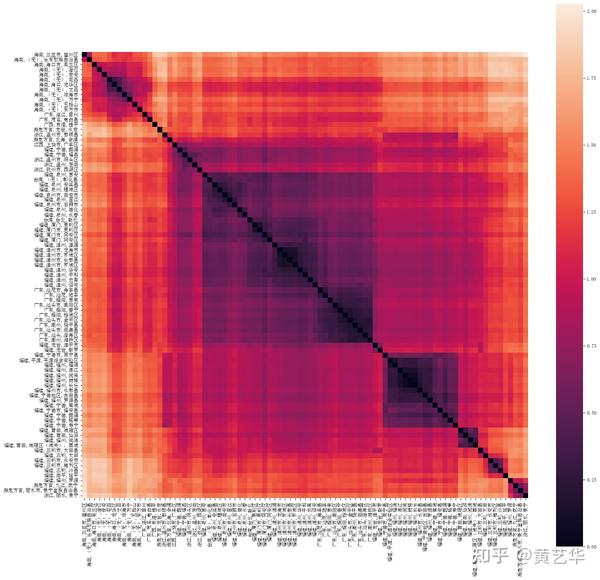
闽南语和闽东语分别构成了两个大聚类中心,闽南内部的潮汕、漳州又构成了次一级的中心。而内陆闽语和雷琼闽语虽然数量也不少,但是和其他闽语的距离较远,内部相互也不集中。
下面的树状图和聚类地图也反映了这种情况,在树状图上,雷琼闽语很早就分出来,然后依次是闽中和莆仙。剩余的主体分成闽南和闽东两大支,闽南语中比较大的子群有泉州和厦门、漳州、潮汕。较低层级的大子群大致对应了历史上大的行政中心,比如福州、泉州、漳州、潮州。
下图是上述树状图分成10类的地图,可见在总的树状图较小的分支上,仍然表现出了马太效应,在其他闽语已经分得比较细碎的层级上,闽南、闽东和莆仙还没有从沿海闽语分出来。
再举规模较大的官话为例,官话的雏形分出来之后,又经过了很多层级的分化才显得比较均衡的样子,之前一直是一支独大。这时南方官话、北方官话、较早就单独分为一支的长江中游的官话、以及在不同层级分出来的几支晋语在树状图中才初具规模,而从树根到这些分支的共组已经经过了6次分化,每次分为10类。
下图是在官话主体的树状图又往下一个层级分10类得到的地图,这样各类的数量才显得均衡一点。 
江淮官话除一部分已经在早前分出以外,剩余的部分这时仍然和西南官话合为一类。北方除了一部分晋语已经先一步分出,剩余的晋语也在这一层分出为一类,胶辽官话也单独分为一类,剩余包括传统分区的北京官话、东北官话、冀鲁官话、胶辽官话、中原官话、兰银官话,在这个层级仍然合在一大类。值得一提的是,此后又经过了4次、总共11次分化,北京官话和东北官话才开始分离,按本文的相似度度量方法来看,传统分区在大区一级划分北京官话和东北官话确实过分苛细了。
最后是包含大多数南方汉语的一支,这一支作为一个整体较早从非闽语中分离,包括传统的吴语、大部分赣语、客家话、粤语和平话。下图是这一支的树状图:
虽然树状图显示从这一支分离的顺序依次为吴语、粤语,最后是赣语和客家话,但它们分离的节点非常接近,可以认为是相互非常独立的分支。。粤语首先分出粤北的零星方言点和桂北平话,然后是四邑片,剩余的主体部分分成两支,一支是桂南平话和部分勾漏片,另一支包括大部分狭义的粤语。客家话首先分出四川、重庆等地的方言岛,然后是江西、福建的几支本地客家话,然后是东江本地话,剩余的部分其主要分支即为核心客家话。
根据树状图分10类得到的地图反映出吴、赣客、粤平三分的情况。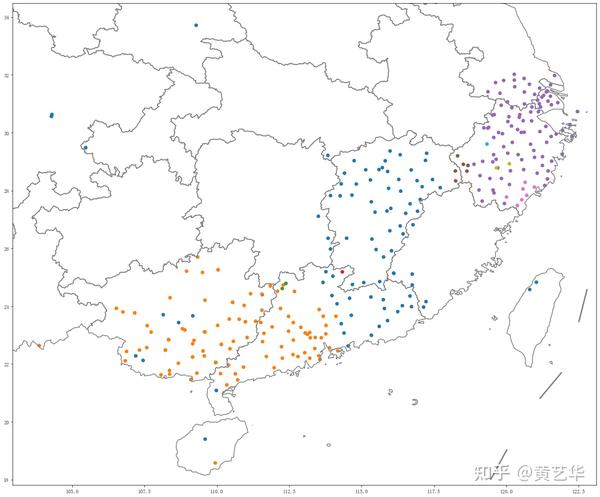
卡方相似度
谱聚类
使用卡方相似度进行谱聚类的结果如下图:
和条件熵差别较大的地方有如下几点:
- 北方官话和晋语合在一起分两大类,西边的一类包括晋语、中原官话西边的部分、和兰银官话,东边的一类包括北京官话、东北官话、冀鲁官话、胶辽官话、和中原官话东边的部分。
- 赣语、湘语、以及长江中游的一部分官话合并成了一个大类。
层次聚类
使用卡方距离的层次聚类倒是把沿海闽语和内陆闽语都归在了一类,但内陆闽语仍然非常早就和沿海闽语分开,紧接着分出的是雷琼闽语。从距离热度图也可以看出,这两类和其他闽语的相似度非常低。

官话上的层次聚类结果和条件熵差别较大,胶辽官话最先分出,然后是西北地区的一部分兰银官话。除此以外,在如下地图的层级上,剩余的北方官话更早地分成了东西两大类,而南方官话还是合而不分。

不足及改进
相似度计算的不足
在计算方言之间相似度的时候,为了平衡数据准确性和平滑性,做了很多琐碎的处理,这些处理还没有得到严格的证明。更好的办法是找到平滑的、最好是参数化的方法来估计 ,但是这样通常会增加计算方言对的耗时。
在计算 时假设每个字的出现是等概率的,或者说每条样本对期望的贡献一样大,实际情况不是这样的。特别是在对比不同来源的材料时,不同材料调查记录的字集可能会很不同,是否包含数量较多的非常用字会对统计结果有较大影响。处理这个问题的困难在于,反映方言用字频率的语料非常稀缺。另一方面,在统计两个方言相似度时,应该怎样折合两个方言的字频呢?
文章开头已经提到了字音对齐的困难,即确定 a 方言的某个字某个音对应 b 方言的哪个字哪个音不是一件显而易见的事情,这个问题不仅出现在一字多音的情况,而且出现在有音无字、或者不同方言用了不同俗字借字的情况。在进行词汇级别的对比的时候就更是如此。本文通过简单地取每个字的第一个读音回避了这个问题。改进思路是采用迭代的方法启发式地寻找跨方言的字音对应,这是一项庞大的工作,做完这一步,所有方言的音变规律基本也都找到了。
聚类的不足
上文已经指出聚类的结果不能等同于方言历史上的发生关系,但是仍然希望聚类的结果对方言谱系树有一定的启示。当前的方法无论从理论还是从聚类结果显示的一些情况来说,对这方面的支持还很欠缺。
本文使用的聚类方法只是沿用了常规算法对距离的简单处理,并没有对方言的生成过程建模。方言相似并不等于同源,在分析方言谱系的时候,一些方面的区别比另一些更加核心和本质,这些因素不一定能通过总体的相似度表现出来。例如罗杰瑞在《What is a Kejia Dialect?》中深有见地地指出,客家话鼻流音调类两分,可以和闽语的表现关联,应能追溯到共同祖语的清鼻流音。凭这一点,客家话应该很早就和赣语分开。但是这个特征体现的字不够多,被其他大量客家话和赣语的共同点所掩盖,其结果是谱聚类把赣语和客家话分了在一类。
方言音类相似也可能是由共同存古造成的,另一方面,由于语言接触引起的共同创新,和较小概率的音变巧合,音类相似在反映共同创新上也不太可靠。上面谱聚类的结果把晋语和江淮官话归为一类,可能就是因为它们都存古保存了入声,并且在入声韵、调的简并方面巧合了。层次聚类在处理晋语和官话的关系的时候,把通常认为的晋语分了三大批次从官话中分离出来,而不是作为一个整体一次分出,可能就是因为接触趋同影响了方言之间的相似性,而不是因为通常认为的晋语在来源上真的不统一。
反之当语言接触引起的借用深到一定程度,会造成边界位置的方言距两边的距离都较远,从而被层次聚类错误地安排在较顶层的分支。层次聚类最开始分出来的都是湘桂交界一带的方言,每支都只有一两个点,很难说每个方言都古老且独立,也可能是周边的方言以各种不同的方式借用混合,从而产生了多种多样和周边都不同的方言。
改进方向
本文度量方言相似度的方法只考虑了音类,音类在方言比较上很重要,但有时对比音值的相似性也是有意义的。鉴于音标代表的音值是离散值不便度量相似度或距离,因此首先要建立把音值映射到连续空间的方法。我在基于自编码器的方言祖语音系嵌入中提出了一种音系 embedding 的方法,实际上,考虑音值的语音学特征,应该能得到更有代表性的方法。获得了音值的连续表示之后,度量方言之间音值的距离,以及根据音值距离聚类,可以参考上面的方法修改而来。
另一个方向是方言音类的连续表示。本文用非参数化的方法构造了方言之间的相似度矩阵 ,即隐含假设了一个方言音类的连续空间
方言音类矩阵 的行数为方言点数,每一行为该方言在连续空间的向量表示。SVD 降维结果是这个音类矩阵在低维的投影,spectral embedding 则是另一种非线性变换的投影。既然字和方言点分别是字音矩阵的行和列,既然字的 embedding 是可行的,那么方言点的参数化 embedding 应该也是可行的。经过细致设计和训练,应该能找到一个非线性的矩阵分解映射函数
,以及最优的字矩阵
、方言矩阵
,使得
即通过字 embedding 和 方言 embedding 最大限度地还原字音矩阵。幸运的话,字 embedding 能表征字的相似度,方言 embedding
能表征方言的相似度,那么,
和
就可以直接拿来比较和聚类。
另一个考虑的角度是相似度矩阵构成了一个图的邻接矩阵,原始的相似度对应于有向图,规范化的相似度对应于无向图。在此基础上可以尝试各种图算法,特别是把图的顶点或子图映射到连续空间的图嵌入(graph embedding)算法。
代码
代码托管在 GitHub,也备份了一份在 Gitee。所有分析过程和图表都在其中的 Jupyter notebook,由于部分算法的随机性,更新后的 notebook 内容主要是地图配色和本文有细微差别,但本质是一样的。
- sinetym/dialect_cluster.ipynb at master · lernanto/sinetym (github.com)
- scripts/zhongguoyuyan/dialect_cluster.ipynb · 黄艺华/sinetym - 码云 - 开源中国 (gitee.com)
来源:知乎 www.zhihu.com
作者:黄艺华
【知乎日报】千万用户的选择,做朋友圈里的新鲜事分享大牛。 点击下载