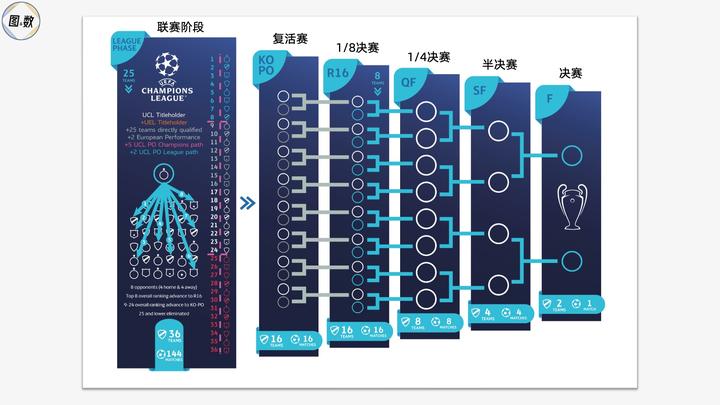





























「百模大战」之后,预见行业新生态|AI 先行者沙龙圆桌实录
2024 年 1 月 6 日,知乎科技举办「破晓 · 知乎 AI 先行者沙龙」,此为上半场圆桌对谈「『百模大战』之后,预见行业新生态」实录文字。嘉宾:(主持人)骆轶航 硅星人/品玩 CEO,硅基立场主理人黄文灏 零一万物技术副总裁及 Pretrain 负责人林俊旸 通义实验室通义千问开源负责人王铁震 HuggingFace 工程师张俊林 新浪微博新技术研发负责人,知乎深度学习优秀答主百模大战与开源生态骆轶航:今天我非常荣幸能够主持知乎AI先行者沙龙。刚刚听了汪玉教授和张拳石教授的分享,我感到心情有些沉重。这种情况很正常,每次参加这类活动,我总是带着乐观的态度来,自己也是大模型的乐观主义者。但是,聊着聊着就会发现其实困惑和挑战都很多。我们是否拥有比挑战更多的解决办法,这一点我们并不知道。这两场分享下来,我发现汪玉教授主要是从算力、硬件和成本的角度思考这个问题。有很多问题摆在我们面前,但我们不知道是否有解。张拳石教授的分享让我更加困惑。我并不是说我们没听懂,而是我承认我们并没有完全听懂。我们神经网络能在多大程度上解决大模型的真正存在的幻觉问题、准确性问题、拟合如何去做,这也是我们每天都在探讨的问题。现在我看着台上的四位嘉宾,我心情也非常困惑。我们今天要聊“百模大战”遇见行业新生态,你看这前后两部分,“百模大战”本身这个事情我们应该怎么来看?这是一个好事还是一个有疑问的事?我觉得这个事实本身就是open to debate,遇见行业新生态,现在的行业一年下来了有没有新生态?这个生态新不新?还是说我们跟去年一样还在一个旧生态里面,其实本身也很有意思。在座的四位其实我仔细看了看,张俊林其实观察的角色更多一点,我本身我的工作是信息跟资源的二道贩子,内容、社区、媒体,科技类的新媒体和社区本身就是二道贩子,其实我更是一个观察者。中间三位仔细一看就很不幸,基本都在搞开源,我不是说搞开源很不幸,我就是说其实过去一年非常有意思,包括我们在中国讨论“百模大战”的时候,其实我觉得我们某种程度上来说,我们很大程度上是在一个开源社区,或者在一个开源工程的环境里去讨论。其实国内任何一个做大模型的公司,包括头部的巨头其实也都至少号称自己是开源社区的贡献者,基本上是这样一个情况。但是过去一年其实我们看到的一个状况其实是一些全球的头部的闭源的大语言模型吸引了人们最多的眼球,事实上创造了最多的使用量和用户量,以及产品化的进度是非常快的。开源领域其实我们看到了那么多大语言模型,但是也有很多被高新,也有很多使用量和下载量,其实舆论作为一个新生态它是不是真的存在?或者说你认为它本身真正地对大语言模型快速地落地和产品化这个事到底有多大的贡献?其实有的时候我还是蛮怀疑的。包括7月份LLaMA 2发布,6月底7月初LLaMA 2发布,国内也有一些人基于LLaMA 2做一些成果,全球也有很多人用它在做,我们私下里在聊,这个事情好像现在也出现了一些瓶颈、也出现了一些问题。所以我觉得第一个问题我还是想先请教各位,大家怎么看过去一年全球也好、中国也好,整个基于开源的这个生态,除了LLaMA这个东西之外,其实我们看到的有哪些真的是对整个大语言模型向前发展有重要意义的突破?这事到底存在不存在?还是说其实开源搞了一年,事实上对于大语言模型的落地和发展来说其实我们是有点自嗨了?首先来聊聊这个话题,这个话题每个人都聊一聊吧。张俊林:那我先来吧。首先我特别支持开源这个形态,我认为过去一年,从去年年初到现在,开源对于我们对大模型的认知、了解,包括对整个生态,包括对应用落地的繁荣,有很大的促进作用。我们首先说对大模型的深入了解,对我来说,过去一年有两个进展我是印象特别深的。第一个方面,我们知道大语言模型分两个阶段,第一个阶段是基座预训练、第二个阶段是post training阶段,包括SFT,instruction tuning等,就是让大模型更能遵循命令,经过一年的研究我们可以认为第一阶段的结论没有大的变化,还是推大模型、增加数据规模和质量,这个没有大的变化。 但是第二阶段,我认为这个事大方向已经基本摸透了,怎么把第二阶段做好呢?其实很简单,就是你用少量的但是高质量的instruction数据去tune一下基座模型,那么大模型就能更好地理解命令,包括遵循价值观等,我认为这个基本可以下定论,这可以认为是过去一年通过开源得出的结论,细节不说,肯定还有很多需要探索的,但是大方向我认为没有问题。 这意味着说对于我们来说,就是没有能力做巨大基座的人来说,其实我们可以把精力花在这一部分,这部分不太消耗资源,可以想想怎么能做得更好。骆轶航:俊林老师,我能不能理解这个意思,其实对于很多训练者来说,数据本身比模型重要?张俊林:我觉得可以下这个结论,包括基座模型其实也是类似的,数据质量比数量重要得多。虽说这个结论其实很早之前就有,但是最近一年很多研究再次验证了这一点,这是第一个。第二个我印象比较深的,跟刚才这个也有关系,从大模型出现开始我一直问自己这样一个问题,我们能不能把大模型做小?我现在判断,当然比较主观,我的结论首先我们应该去做这件事,而且从过去一年进展来看,将来你可以说我不需要那么多数据,我可以把数据质量提上去,模型规模可以压下去,在这个基础上再大量加高质量数据,通过这种方式把大模型做小,目前看是可以的。我相信2024年大概率会推出性能非常好的小模型。骆轶航:现在已经有了。张俊林:对,现在已经有了一些,比如微软2.7B的phi-2,包括Mistral 7B,这些模型效果其实不差,我相信未来会更强。过去一年开源对这件事的贡献是什么呢?我认为有两个,一个证明这条路是可行的,第二个开源项目指出了路径,说到路径也很简单,回到刚才那个问题了,还是数据质量的问题。我可以把模型规模推得很小,但是我要用更多的高质量的数据,这个量也不用特别大(phi-2),可以保证这个小模型效果还是不错的。当然目前这个阶段小模型的水准跟GPT4肯定还是没法比,但是我们如果把大模型能力拆解一下,你会发现将来我们把小模型做强这个方向是非常乐观的。我来拆一下,如果比较粗粒度地把大模型能力拆分,有三种能力特别重要,第一种是语言能力,小模型哪怕你再小,1B的、2B的都可以,和大模型比、包括和GPT 4这个规模等级的模型比没有什么问题,语言能力小模型没有任何问题,已经追上了,所以这方面能力不是问题。 第二个,我们叫知识能力或知识获取能力,知识获取能力原则上应该是模型越大越好,但是不要忘了我们最近一年有个进展RAG外挂知识库,如果说小模型再加外挂知识库,其实它的知识能力不一定比大模型差,如果做法得当,甚至可能会更好,这是第二种重要能力。这两种能力(语言+知识)我觉得现在就可以下结论,小模型不会比大模型差,不说更好,起码能够相当。第三个,逻辑推理能力。其实小模型的缺陷在逻辑推理能力,逻辑推理能力大模型现在也有问题,但是如果是比较小模型和大模型的逻辑推理能力的话,小模型还是会弱一些。不过我觉得未来一年如果我们有办法能够打破这个障碍,把小模型的推理能力提上去,我目前从最近一年的进展上来看应该是有路径的,应该可以做到这一点。如果把小模型的推理能力提上去,我们在2024年应该能看到小模型的效果可能不一定比闭源的大模型差,以上两点是我最近一年体会最深的两个点。骆轶航:简单总结一下,俊林老师这一年觉得开源给我们带来的两个 new learning,一个就是说高质量的、少量的高质量的数据对于训练一个模型的重要性,哪怕你对于大部分没有能力,没有办法从基座去做的。第二个小语言模型的普适性,尤其是小语言模型在推理能力方面如何能够实现,至少在某些方面,或者某一个维度、某一个领域和大模型不相上下的一个效果。其他的谁来讲一讲?这个铁震必须得讲。王铁震:我接着张老师的讲,我其实特别同意张老师的观点,我觉得开源提供了多样性,你有更多的选择,你去看模型的效果来看,当前闭源模型比开源模型好,毕竟闭源模型它要收费。骆轶航:你刚才这个话是个肯定的话是吗?王铁震:肯定的话。是,如果这个闭源模型它是收费的,它要向用户收费,它还没有一个外面大家随便就能在HuggingFace上下载的免费模型好,那这个闭源公司它也运作不下去的,而且开源模型不管我们在这儿做什么样的创新,它是开源的,它的东西是发paper大家都知道,闭源这些公司它可以去吸取里面好的地方用在他的模型里面,但是闭源模型它用的什么技术,开源这边可能不知道的,如果他不写paper。骆轶航:他们现在基本都不发paper了。王铁震:所以ChatGPT出来之后呢,其实这个对行业来讲是一个好的事情,你去看行业AI这些年都是开源推动的,直到GPT3大家那个时候出现,大家说我花了几百万、几千万去训练一个模型,我为什么要把它开源?而且那个时候大家对文本模型,除了我们圈子以外的人,对这种文本模型没有那么多关注的,一个学校它说我搞几千万的资金去训练一个模型,最后还没有什么人关注,其实大家是不愿意去开源,那个时候开源我感觉都有点停滞了,我甚至都有点担心。GPT4一出来之后大家就更担心了,对话模型,比以前的文本模型做的能力更强,对话的模型又出来,感觉里面有很多黑科技我们都不知道,我感觉过去一年,年初的时候开源还是比较沮丧的这么一个状态,但是经过这一年的发展,包括您说的LLaMA的出现,我感觉开源这个活力又回来了,大家又开始愿意去开源很多模型,愿意去把自己的知识贡献出来,愿意基于一个比如说LLaMA的生态,大家形成合力了,每个人可以去探索不同的方向,有的人可以做预训练、去调数据,有的人可以做微调,甚至把模型做小,做在不同的硬件上面,你提供了比ChatGPT一个公司、OpenAI一个公司在这个领域进化快得多的一个能量,所以我觉得开源还是在这个领域做了非常多有价值的工作。但你说单靠开源一个产品,当前它的技术能力和产品跟闭源还是有差距的,这都很正常,这两个其实是互相促进的,闭源打在前面,开源后面去追,大家一起去把这个领域去做得更深,让更多的人把这个技术用起来。骆轶航:其实反而我刚才听到一个关键我觉得还蛮有意思的,反而是闭源的大模型这一两年,然后说白了就是2022年底到2023年进展其实反而推动了开源本身再去做一些新的突破和尝试。王铁震:因为一开始开源更多的是在机器学习圈内,然而闭源产品出圈,让更多圈外人知道了我们都在做些什么,同时也让更多的人知道了什么是开源。骆轶航:HuggingFace是受益者毫无疑问是吗?王铁震:对,没错。骆轶航:我们聊了HuggingFace这个受益者,我们看看通义千问,通义是开源人类历史上参数最大的一个开源模型对吗?我能这么说吗?林俊旸:其实也不算,Falcon其实更大。骆轶航:那其实我想聊聊,俊旸聊一聊开源的事吧,从过去一年有什么成就?从你们这个角度。林俊旸:骆老师总是提非常敏感的问题,开源是否造成虚假繁荣这个现象,其实刚才铁震的回答我觉得他是想逼我放更强的模型到他们社区。骆轶航:他就希望所有人都做雷锋嘛。林俊旸:我是这么看这个问题的,我觉得开闭源是一个选择,闭源模型比开源模型更强这个东西是不是成立我其实是打问号,我其实是反对的。我们今天在谈的是OpenAI和非OpenAI是这个差距,我其实个人感觉可能我有点暴论,我个人感觉像Gemini AI和Claude的话,我觉得我还是非常有信心,单从语言模型来说,多模态另说了。骆轶航:你意思是说我们搞不了OpenAI,我们还超不过GeminiAI和Claude吗?是这个意思吗?林俊旸:至少有戏,至少在很多场合里面还是有来有回的。我觉得好多模型都做得不错,可能是部分方面的,之前我们可能会有一些部分方面,甚至有一些是部分地超越GPT4,但是大家始终感觉跟GPT4的差距还是很大,但是今年比如说大家看国内的模型,开源也好、闭源也好,大家觉得我其实不用3.5,我用这个其实会更好,跟GPT4可能有一些差距,是不是有一些人在用Bard、在用 Claude呢?尤其是用Claude的话,我们上半年的时候我觉得差距跟Claude还比较有差距,下半年我感觉这个在缩小,我甚至跟同样是做开源模型的国外的人去聊,像up

2024 年 1 月 6 日,知乎科技举办「破晓 · 知乎 AI 先行者沙龙」,此为上半场圆桌对谈「『百模大战』之后,预见行业新生态」实录文字。
嘉宾:
(主持人)骆轶航 硅星人/品玩 CEO,硅基立场主理人
黄文灏 零一万物技术副总裁及 Pretrain 负责人
林俊旸 通义实验室通义千问开源负责人
王铁震 HuggingFace 工程师
张俊林 新浪微博新技术研发负责人,知乎深度学习优秀答主
百模大战与开源生态
骆轶航:今天我非常荣幸能够主持知乎AI先行者沙龙。刚刚听了汪玉教授和张拳石教授的分享,我感到心情有些沉重。这种情况很正常,每次参加这类活动,我总是带着乐观的态度来,自己也是大模型的乐观主义者。但是,聊着聊着就会发现其实困惑和挑战都很多。我们是否拥有比挑战更多的解决办法,这一点我们并不知道。这两场分享下来,我发现汪玉教授主要是从算力、硬件和成本的角度思考这个问题。有很多问题摆在我们面前,但我们不知道是否有解。
张拳石教授的分享让我更加困惑。我并不是说我们没听懂,而是我承认我们并没有完全听懂。我们神经网络能在多大程度上解决大模型的真正存在的幻觉问题、准确性问题、拟合如何去做,这也是我们每天都在探讨的问题。现在我看着台上的四位嘉宾,我心情也非常困惑。
我们今天要聊“百模大战”遇见行业新生态,你看这前后两部分,“百模大战”本身这个事情我们应该怎么来看?这是一个好事还是一个有疑问的事?我觉得这个事实本身就是open to debate,遇见行业新生态,现在的行业一年下来了有没有新生态?这个生态新不新?还是说我们跟去年一样还在一个旧生态里面,其实本身也很有意思。
在座的四位其实我仔细看了看,张俊林其实观察的角色更多一点,我本身我的工作是信息跟资源的二道贩子,内容、社区、媒体,科技类的新媒体和社区本身就是二道贩子,其实我更是一个观察者。中间三位仔细一看就很不幸,基本都在搞开源,我不是说搞开源很不幸,我就是说其实过去一年非常有意思,包括我们在中国讨论“百模大战”的时候,其实我觉得我们某种程度上来说,我们很大程度上是在一个开源社区,或者在一个开源工程的环境里去讨论。
其实国内任何一个做大模型的公司,包括头部的巨头其实也都至少号称自己是开源社区的贡献者,基本上是这样一个情况。但是过去一年其实我们看到的一个状况其实是一些全球的头部的闭源的大语言模型吸引了人们最多的眼球,事实上创造了最多的使用量和用户量,以及产品化的进度是非常快的。
开源领域其实我们看到了那么多大语言模型,但是也有很多被高新,也有很多使用量和下载量,其实舆论作为一个新生态它是不是真的存在?或者说你认为它本身真正地对大语言模型快速地落地和产品化这个事到底有多大的贡献?其实有的时候我还是蛮怀疑的。包括7月份LLaMA 2发布,6月底7月初LLaMA 2发布,国内也有一些人基于LLaMA 2做一些成果,全球也有很多人用它在做,我们私下里在聊,这个事情好像现在也出现了一些瓶颈、也出现了一些问题。所以我觉得第一个问题我还是想先请教各位,大家怎么看过去一年全球也好、中国也好,整个基于开源的这个生态,除了LLaMA这个东西之外,其实我们看到的有哪些真的是对整个大语言模型向前发展有重要意义的突破?这事到底存在不存在?还是说其实开源搞了一年,事实上对于大语言模型的落地和发展来说其实我们是有点自嗨了?
首先来聊聊这个话题,这个话题每个人都聊一聊吧。
张俊林:那我先来吧。首先我特别支持开源这个形态,我认为过去一年,从去年年初到现在,开源对于我们对大模型的认知、了解,包括对整个生态,包括对应用落地的繁荣,有很大的促进作用。我们首先说对大模型的深入了解,对我来说,过去一年有两个进展我是印象特别深的。
第一个方面,我们知道大语言模型分两个阶段,第一个阶段是基座预训练、第二个阶段是post training阶段,包括SFT,instruction tuning等,就是让大模型更能遵循命令,经过一年的研究我们可以认为第一阶段的结论没有大的变化,还是推大模型、增加数据规模和质量,这个没有大的变化。
但是第二阶段,我认为这个事大方向已经基本摸透了,怎么把第二阶段做好呢?其实很简单,就是你用少量的但是高质量的instruction数据去tune一下基座模型,那么大模型就能更好地理解命令,包括遵循价值观等,我认为这个基本可以下定论,这可以认为是过去一年通过开源得出的结论,细节不说,肯定还有很多需要探索的,但是大方向我认为没有问题。
这意味着说对于我们来说,就是没有能力做巨大基座的人来说,其实我们可以把精力花在这一部分,这部分不太消耗资源,可以想想怎么能做得更好。
骆轶航:俊林老师,我能不能理解这个意思,其实对于很多训练者来说,数据本身比模型重要?
张俊林:我觉得可以下这个结论,包括基座模型其实也是类似的,数据质量比数量重要得多。虽说这个结论其实很早之前就有,但是最近一年很多研究再次验证了这一点,这是第一个。
第二个我印象比较深的,跟刚才这个也有关系,从大模型出现开始我一直问自己这样一个问题,我们能不能把大模型做小?我现在判断,当然比较主观,我的结论首先我们应该去做这件事,而且从过去一年进展来看,将来你可以说我不需要那么多数据,我可以把数据质量提上去,模型规模可以压下去,在这个基础上再大量加高质量数据,通过这种方式把大模型做小,目前看是可以的。我相信2024年大概率会推出性能非常好的小模型。
骆轶航:现在已经有了。
张俊林:对,现在已经有了一些,比如微软2.7B的phi-2,包括Mistral 7B,这些模型效果其实不差,我相信未来会更强。过去一年开源对这件事的贡献是什么呢?我认为有两个,一个证明这条路是可行的,第二个开源项目指出了路径,说到路径也很简单,回到刚才那个问题了,还是数据质量的问题。我可以把模型规模推得很小,但是我要用更多的高质量的数据,这个量也不用特别大(phi-2),可以保证这个小模型效果还是不错的。当然目前这个阶段小模型的水准跟GPT4肯定还是没法比,但是我们如果把大模型能力拆解一下,你会发现将来我们把小模型做强这个方向是非常乐观的。
我来拆一下,如果比较粗粒度地把大模型能力拆分,有三种能力特别重要,第一种是语言能力,小模型哪怕你再小,1B的、2B的都可以,和大模型比、包括和GPT 4这个规模等级的模型比没有什么问题,语言能力小模型没有任何问题,已经追上了,所以这方面能力不是问题。
第二个,我们叫知识能力或知识获取能力,知识获取能力原则上应该是模型越大越好,但是不要忘了我们最近一年有个进展RAG外挂知识库,如果说小模型再加外挂知识库,其实它的知识能力不一定比大模型差,如果做法得当,甚至可能会更好,这是第二种重要能力。这两种能力(语言+知识)我觉得现在就可以下结论,小模型不会比大模型差,不说更好,起码能够相当。
第三个,逻辑推理能力。其实小模型的缺陷在逻辑推理能力,逻辑推理能力大模型现在也有问题,但是如果是比较小模型和大模型的逻辑推理能力的话,小模型还是会弱一些。不过我觉得未来一年如果我们有办法能够打破这个障碍,把小模型的推理能力提上去,我目前从最近一年的进展上来看应该是有路径的,应该可以做到这一点。如果把小模型的推理能力提上去,我们在2024年应该能看到小模型的效果可能不一定比闭源的大模型差,以上两点是我最近一年体会最深的两个点。
骆轶航:简单总结一下,俊林老师这一年觉得开源给我们带来的两个 new learning,一个就是说高质量的、少量的高质量的数据对于训练一个模型的重要性,哪怕你对于大部分没有能力,没有办法从基座去做的。第二个小语言模型的普适性,尤其是小语言模型在推理能力方面如何能够实现,至少在某些方面,或者某一个维度、某一个领域和大模型不相上下的一个效果。
其他的谁来讲一讲?这个铁震必须得讲。
王铁震:我接着张老师的讲,我其实特别同意张老师的观点,我觉得开源提供了多样性,你有更多的选择,你去看模型的效果来看,当前闭源模型比开源模型好,毕竟闭源模型它要收费。
骆轶航:你刚才这个话是个肯定的话是吗?
王铁震:肯定的话。是,如果这个闭源模型它是收费的,它要向用户收费,它还没有一个外面大家随便就能在HuggingFace上下载的免费模型好,那这个闭源公司它也运作不下去的,而且开源模型不管我们在这儿做什么样的创新,它是开源的,它的东西是发paper大家都知道,闭源这些公司它可以去吸取里面好的地方用在他的模型里面,但是闭源模型它用的什么技术,开源这边可能不知道的,如果他不写paper。
骆轶航:他们现在基本都不发paper了。
王铁震:所以ChatGPT出来之后呢,其实这个对行业来讲是一个好的事情,你去看行业AI这些年都是开源推动的,直到GPT3大家那个时候出现,大家说我花了几百万、几千万去训练一个模型,我为什么要把它开源?而且那个时候大家对文本模型,除了我们圈子以外的人,对这种文本模型没有那么多关注的,一个学校它说我搞几千万的资金去训练一个模型,最后还没有什么人关注,其实大家是不愿意去开源,那个时候开源我感觉都有点停滞了,我甚至都有点担心。GPT4一出来之后大家就更担心了,对话模型,比以前的文本模型做的能力更强,对话的模型又出来,感觉里面有很多黑科技我们都不知道,我感觉过去一年,年初的时候开源还是比较沮丧的这么一个状态,但是经过这一年的发展,包括您说的LLaMA的出现,我感觉开源这个活力又回来了,大家又开始愿意去开源很多模型,愿意去把自己的知识贡献出来,愿意基于一个比如说LLaMA的生态,大家形成合力了,每个人可以去探索不同的方向,有的人可以做预训练、去调数据,有的人可以做微调,甚至把模型做小,做在不同的硬件上面,你提供了比ChatGPT一个公司、OpenAI一个公司在这个领域进化快得多的一个能量,所以我觉得开源还是在这个领域做了非常多有价值的工作。
但你说单靠开源一个产品,当前它的技术能力和产品跟闭源还是有差距的,这都很正常,这两个其实是互相促进的,闭源打在前面,开源后面去追,大家一起去把这个领域去做得更深,让更多的人把这个技术用起来。
骆轶航:其实反而我刚才听到一个关键我觉得还蛮有意思的,反而是闭源的大模型这一两年,然后说白了就是2022年底到2023年进展其实反而推动了开源本身再去做一些新的突破和尝试。
王铁震:因为一开始开源更多的是在机器学习圈内,然而闭源产品出圈,让更多圈外人知道了我们都在做些什么,同时也让更多的人知道了什么是开源。
骆轶航:HuggingFace是受益者毫无疑问是吗?
王铁震:对,没错。
骆轶航:我们聊了HuggingFace这个受益者,我们看看通义千问,通义是开源人类历史上参数最大的一个开源模型对吗?我能这么说吗?
林俊旸:其实也不算,Falcon其实更大。
骆轶航:那其实我想聊聊,俊旸聊一聊开源的事吧,从过去一年有什么成就?从你们这个角度。
林俊旸:骆老师总是提非常敏感的问题,开源是否造成虚假繁荣这个现象,其实刚才铁震的回答我觉得他是想逼我放更强的模型到他们社区。
骆轶航:他就希望所有人都做雷锋嘛。
林俊旸:我是这么看这个问题的,我觉得开闭源是一个选择,闭源模型比开源模型更强这个东西是不是成立我其实是打问号,我其实是反对的。我们今天在谈的是OpenAI和非OpenAI是这个差距,我其实个人感觉可能我有点暴论,我个人感觉像Gemini AI和Claude的话,我觉得我还是非常有信心,单从语言模型来说,多模态另说了。
骆轶航:你意思是说我们搞不了OpenAI,我们还超不过GeminiAI和Claude吗?是这个意思吗?
林俊旸:至少有戏,至少在很多场合里面还是有来有回的。
我觉得好多模型都做得不错,可能是部分方面的,之前我们可能会有一些部分方面,甚至有一些是部分地超越GPT4,但是大家始终感觉跟GPT4的差距还是很大,但是今年比如说大家看国内的模型,开源也好、闭源也好,大家觉得我其实不用3.5,我用这个其实会更好,跟GPT4可能有一些差距,是不是有一些人在用Bard、在用 Claude呢?尤其是用Claude的话,我们上半年的时候我觉得差距跟Claude还比较有差距,下半年我感觉这个在缩小,我甚至跟同样是做开源模型的国外的人去聊,像upstage刚出SOLAR,他们其实更加有信心,我当时我在他们的讲座里边,我说我们跟OpenAI可能还有一年的差距,当然这个一年是毛估了,这个就随便说的,他说你说得不对,我也有很多OpenAI的朋友,我觉得就半年的差距,他非常有信心。
但是我觉得开源对我来说帮助我们这个团队很大的一个点,大家可以看到通义千问,比如说上半年通义千问已经出来了,但是很少人在讨论通义千问,你能明显地感觉到,在那个时候大家会觉得说通义千问是一个so so的模型,但是到了今年这一个时候,也许我有点大言不惭,但是我至少能跟大家坐到这个台上来发表我刚才的这个暴论,我觉得一定程度上我们这个团队还是成功了那么一点点,铁震也会天天盯着我说你这个模型啥时候发呀?你的下一代的东西什么时候出呀?今天也看到一些模型出来。
我觉得开源是造福了全社会,让大家热情更高,能把更好的技术给弄出来,所以我们当时也尝试说如果我们觉得我们这个基座模型还不错,我们开出去会不会更好?我们开出去就发现了很多问题,用户会反馈说这个模型可以这样优化、哪方面优化,这些意见一回来我就知道说原来我们自己的评测还不能覆盖好我们自己做的这个事情,我们能做更好的模型。
如果我们作为开源的,一个是开更好的基座模型让大家去用,我们还要做一件事情,让大家怎么用得更爽,学界的人完全可以跟我们有更多的合作,今天我非常感谢HuggingFace,如果没有HuggingFace的话,今天大家根本不可能用大模型用得这么爽的。
骆轶航:你不感谢你们自己的ModelScope吗?
林俊旸:ModelScope这是第二个问题,我待会儿。
骆轶航:我一直不确定你能不能代表ModelScope说话主要是?
林俊旸:我算是友情代言,我一定程度上我也能说,但是我们ModelScope跟HuggingFace的合作也非常多,待会儿我们连还可以互动再聊一下ModelScope的这个问题。
骆轶航:我建议这一次一定要把你们俩放在一起,就是想看这个。
林俊旸:或者说感谢Transformer这个库,我是2020年的时候开始做大模型,当时做了100亿,非常非常地痛苦,你要训一个东西真的是很难,跟推理也没法搞,今天居然说笔记本拿着CPU居然可以跑70亿的模型,大家说70亿的模型是小模型,你放到几年前去看真的是非常天方夜谭的这个事情。所以有了这些事情之后,大模型已经越来越平民化,我在我的微信群里我知道中专的学生已经在学习大模型,普惠这件事情非常好,每个人都非常有创造力,大家都有创造力这个社区、这个行业才能发展得快,有了这个以后学界和业界真的能够发展得好,大家分清好自己的职责就好了。一些暴论。
骆轶航:简单总结一下这个暴论,第一个就是说开源模型做得好的话,我干不了ChatGPT,我还干不了cloud和Gemini AI吗?这是暴论一。
暴论二就是其实大厂们,以阿里为代表之一的大厂们,其实不光大厂,创业公司你刚才讲的我左手搞开源、右手怀里揣着一个更大的闭源,这个典型的还不是阿里,这个典型的分明是百川跟智谱,其实大家都在走这条路,这条路就是给自己留一条商业化的活路,同时把能开源的部分基本上能开源出去,繁荣社区、繁荣一个人同时让自己做得很好,这个是一个基本的路,大厂基本上都在干这个活,对吧。
从零一的角度来去看,本身我们也是开源社区的受益者,从这个角度到底有什么意义?对一个其实已经正经干活干了七八个月的大模型创业公司来说怎么看待这个问题?
黄文灏:我先说一下我对“百模大战”的看法,我觉得其实模型要分成两个部分,一个是基础模型,也就是pretrain部分;另一个是post-train部分,continue pretraining,SFT都是属于后面的部分。前面的部分真正做基础模型,从头开始用海量数据好好做训练的其实并没有特别多,过去一年大家都加一块可能十个,十几个模型吧,全球加在一块,大概也就这样一个量。
如果自己做过就知道训练一个模型,不管再小,7B、13B可能也是几百万的成本,刚才汪老师也说了,就像180B的模型几个亿只能训练一遍。我们现在也在训练比较大的模型,这个钱的开销是很恐怖的,所以这个事情不是传统意义上的开源社区可以做的。传统的开源是说大家联合来自不同组织的人去训练一个模型,这个事情在基础模型阶段很难做到。
另外一部分是post-train,基于前面提到的预训练模型,比如英文有LLaMA,中文有通义,还有我们有Yi模型。很多的开发者基于预训练模型,他们花很少的成本,比如说准备几千条数据,可能几千美金就可以微调一个很好的模型。当然我不赞成他们应该被称作“百模大战”,做了一些SFT以后就叫一个新的模型名字,但大家纷纷抢滩入局确实繁荣了很多行业的开发者。
刚才骆老师有个观点,没有看到用开源模型的应用,这个其实我们往下沉来看也不见得。ChatGPT用户量很大,它有几亿用户量在里面。但同时也有很多应用它已经开始用开源模型做了,它只要能Fit它的那个场景,就是到technology product fit,我可以把成本压下来,我可以自己去做distillation,我可以自己去做量化。在这种情况下,其实是有大量的比如说一个应用它有几万用户、几十万用户,但这样的用户应用的量其实是很大的,所以在这种情况下,其实整个开源社区还是给应用生态创造了一些很大的价值。
再回到刚才骆老师的问题,我觉得也可以澄清一下,之前我们也会有一些风波吧。
骆轶航:是你主动要谈的啊。
黄文灏:没关系,我觉得早晚还是要谈一下,刚才我记得汪老师的PPT里面有一句话,叫架构借鉴LLaMA,我可以简单说一下LLaMA的paper里面,关于Architectures(架构)的部分其实就很短,大概四分之一页吧,它原话是based on transformer architecture,leveraged various improvements,就是LLaMA基于transformer架构,用了一些常用的改进,具体说了三个,第一个他用了PreNorm,这个来自GPT3。第二个是SwiGLUE这个是Palm用的,第三个是RoPE,这个是GPTNeox用的。只有这三个不同,其他都跟Transformer一样,但这三个也是社区普遍在用的。所以很多人说LLaMA的架构让国内的大模型训练有了希望,这一点我是不认同的。我觉得大家的模型架构基本上都差不多,因为Transformer就长这样,它能变的地方很少,LLaMA出来之前国内做大模型的架构就是长这个样子的。而最核心的数据部分LLaMA并没有开源。过去一段时间国内的模型效果不错也是大家在数据上下了很大功夫,只要数据足够多质量足够高,大家就能训练出一些很不错的模型。
再回到开源的问题,我们在开源上的确做得不太到位,改了一些变量并没有说明。后面我们也招聘了开源经理,他今天也来了现场,之后他也跟开发者很频繁地互动。我觉得大家开源就应该以比较规范的方式开源,后面我们也发现我们改回了LLaMA架构以后发现突然变好了,很多国外的开发者就可以用了,他们就基于我们的模型去做各种各样的尝试、微调,使整个开源社区会非常繁荣。我觉得我们的Yi模型应该是在国外的开源社区里面用得最多的国内的几个模型之一。沿用LLaMA架构这个事情,这一点也是一个很有意思的。我发现后来开源的时候越来越多的人都是这样去做,整个生态其实也是在越变越好。
骆轶航:我觉得文灏其实也释放了两个暴论,第一个暴论就是其实没有真正的“百模大战”、真正从基础端能够去train一个模型的,十模大战、二十模大战到头了。在中国,其实不存在那个意义的“百模大战”。
第二个问题当时我听了之后我还是“嗯”了一下,其实就是说LLaMA架构的出现事实上繁荣了中国的基础模型的生态,这个事其实本身不是这个道理,跟大家看到的其实并不是完全一样的。
黄文灏:对,我觉得大部分做技术,真正训练模型的觉得LLaMA架构本质上还是Transformer架构,方便开发者使用是事实,但是把其说成是“架构的希望”,有点过度了。LLaMA出现之前,开源社区的BloomZ,OPT,GPTNeox基本都是这样的架构。
骆轶航:但是这里面我觉得刚才文灏提到一个点我个人觉得挺重要的,其实各位都提到了这个点,就是说我们中国的这些做无论是大厂做的基础模型,还是很多创业公司训练的模型,其实本身它参与了全球开源社区的建设,因为其实刚才汪玉教授也讲芯片领域也好、半导体领域也好,这块其实有很多你没法改变的限制。在开源这个领域其实是中国跟全球技术在这个领域非常好的一个有效的沟通、互动和共同促进一个非常好的环节,我记得特别清楚的一个事是OpenAI公告的那几天,我记得当时也有人去讲,讲到这个事情其实对于整个全球AI的影响,我觉得应该是Cosla Ventures的合伙人 Windows Cosla他就提到了,我不知道为什么他提到了,他说中国有可能会从开源社区中获得even still大量的东西去繁荣他们的生态,Windows Cosla一贯这么讲话,但是LeCun出来就开始反驳他,其实如果你仔细到HuggingFace去看一看,到开源社区看一看,中国基础的大语言模型开发者贡献是非常大的,这是一个非常有意思的现象。
涌现与幻觉
接下来我还是想跟大家去聊两个,这一场核心的是聊大语言模型本身未来的生态,其实现在还有两个关键的问题我们放在一起聊一下,这个问题谁想聊就聊一聊。
第一个问题,顺着“百模大战”,经常有人提“百模大战”,一般后边我会加四个字,叫“百模大战都不涌现”,大家经常去讨论这个事,大家经常会从某一两个维度上对标3.5,我们可能会超过它了,大家某种意义上会跟4去PK,但是没有实现真正意义上的涌现,现在又有新的论文——涌现是不存在的,涌现本身是度量标准的变化,而不是模型本身的结构发生了变化,要允许做这样一个思考。
第一个问题大家怎么看待涌现的问题?目前我们国内大语言模型,目前的这种智能化的现状、泛化的能力,和所谓的卡的涌现这种东西会在多大程度上影响大模型的落地和应用?第二个我还想知道所谓的幻觉问题到底该通过什么样的办法去解决?因为这个事其实也很有意思,大家都讲大模型的幻觉、丧失记忆,这个我们应该通过RAG去解决,现在也有人指出来RAG用多了会让大模型本身变笨,大模型基础的能力还是基础模型本身的能力,RAG让它强行记了很多东西,让它变笨了,它的学习能力并不像我们想象的那个样子,这两个问题我想请各位如果对这个问题有些观察、有些思考、有些尝试的话可以分享一下对这两个问题的看法,其实这两个还是蛮中性的问题,其实是影响开发者基于大模型开发应用和人们使用大模型体验的两个关键的问题。
黄文灏:这个问题首先从哲学层面我自己信奉的是幻觉是必须要存在的,Andrej Karparthy说过the most fascinating thing about large language model is hallucination,without hallucination the model cannot create, 就是说你没有幻觉的话这个模型是没有创造力的。
骆轶航:我插一句,我最近做了一个AI陪伴类应用的沉迷型玩家,我觉得AI陪伴类应用最有魅力的地方在于它的幻觉。
黄文灏:我觉得幻觉和创造力是相关的,大家不需要一个东西非常刻板地回答你的所有的问题,所以我觉得幻觉从某种程度上是和智能相关的。
骆轶航:对于垂直专业领域的应用也是这个样子吗?
黄文灏:这个其实是方法论的方面,我们可以根据不同的需求去控制他的幻觉,然后我自己觉得最好的方法,我的暴论其实是在知乎上写过scale up is all you need,就是模型越大就会越好,我们自己在做千亿和万亿模型的时候就会发现幻觉会显著地下降,现在很多幻觉都来自于模型不够大。涌现其实是一样的,模型大了以后涌现就会自然而然发生,我们只要训练更大模型就可以了。当然,如果用scaling law做好的训练预测建模,我们也会发现涌现不是一下子发生的,而是可以精确预测的。
林俊旸:涌现和幻觉的问题,首先先说涌现,其实 bench那个文章就已经在讨论这个事情了,只是大家没有认真去讨论Benchmark的文章,当我们真的去看他的TBL的时候,它其实还是比较稳定地在下降,比如说评测指标,代码的通过率你得完全对了才能通过,稍微错一点都不行,所以你会看到一个涌现的现象,这是我原来的一个理解。
今天我们怎么看它是不是还是涌现?我个人感觉是这样,现在的涌现更难去度量了,我们的感觉是刚才提到 scale up is all your need,我自己非常同意这个观点,因为我们自己我们甚至还有更大的模型,我们会去观测说它似乎变得更聪明了?更聪明这个事情你怎么去度量?它是非常难的一件事情,我最近的一个体会,或者是猜测吧,是它的各项的原子的基础能力的提升带来的给人的感觉就是推理能力,因为所谓的推理是一个很抽象的事情,每个人对推理有不同的看法,不同的推理它又是不一样的情况,但是它是很多能力的结果。
骆轶航:涌现也是没有标准的。
林俊旸:对。它其实是没有标准的,你的原子能力提升,代表说你组合起来的大家感觉的所谓的推理能力有了明显的提升,这是我的个人的看法。你想让你的原子能力水平不断提高,最简单的方式当然是 scaling up,当然我们可以在scaling的情况下,我们还能再优化这个模型当然也是可以的,因为我们现在比如说做1.8B的模型,他们也在用这个东西,比两年前的东西肯定是强多了,这不用说,这个还可以。但是你要说真跟同样的方案去训一个1.8B的模型和你去训一个72B的模型那是截然不同的,这是我涌现的点。
说到幻觉我觉得也是一样的问题,你的幻觉水平能不能降低,其实是看这个模型能不能遵循指令,能理解你的指令,比如说它该说想象的话的时候它说想象的话,该说事实的时候说事实,这个时候指令遵循能力的提升跟你scaling up 你这个模型能力就非常关键了。这是我一点看法。
王铁震:我觉得刚才两位把幻觉和涌现说得很到位了,我就只是插一句,大模型可能它现在是一个N2N的一个东西,但是你真正把它放产品里面,你起来外面还要包一些比如说SQL,你要加一些RAG,或者加一些幻觉的检测,尤其在领域上要做一些处理,所以这个可能不光是大模型要解决的问题,你要更多地想外面的问题。
比如说我写一个操作系统内核 (kernel),我外面要加一道防火墙的,我不是说我这个内核全都解决的,内核要来解决一个非常专注的问题,针对不同的场景你可能选外面的防火墙 (firewall/guardrail) 有幻觉还是没有幻觉等。
骆轶航:它有它的性格,我觉得这个是特别有意思的一个事。
王铁震:你会针对不同的任务,你会选择不同的模型,比如说通义的最大的模型可能就更擅长Agent,Yi这个模型就擅长日常替代3.5的东西,这是非常非常有意思的,我们也希望后面看到大家把开源模型用起来,因为开源模型的部署成本,其实用上芯片的加速,用上现在部署的优化会比3.5要低很多,也期待明年看到开源在生产环境上大规模的应用。
张俊林:时间原因我就讲讲涌现的事,我个人对这个事一直特别好奇,我很好奇它到底怎么产生的。咱们聊聊涌现存在不存在这个事。去年年初大家讲涌现讲得比较多,因为大模型存在涌现现象,所以大家都对大模型的发展非常乐观。涌现的本质是有些困难的任务小模型做不了,大模型突然就能做了,这自然带给大家对未来乐观的预期:就是说我将来把模型做得更大一点,现在尽管很多事都做不好,但是将来一定能做好,所以说大家非常乐观。去年年初的时候大家讲得比较多,2023年年中出了一篇论文说涌现是不存在的,把这条线给否掉了,那它到底存在不存在?我有几点看法。
第一,这点其实刚才林老师也讲了,我先说那个文章是怎么说这个事的,它是这么说的:如果我选一个不平滑的指标来评估一个任务的性能,比如说任务的准确率,我们就会看到涌现现象,模型小效果就不行,到了一定规模突然就变好了。如果用每个token的错误率,这就是平滑的一个指标,你就看到这个任务随着模型规模的增长,任务效果在平滑地增长,基本上是一个线性的关系。其实2022年已经有论文提出这个猜想了,这个文章我认为它只是说证实了这个猜想而已,这是第一点。
第二,涌现存在不存在呢?我觉得我们要辩证地看这个事。如果在预训练阶段按照这个论文提的,按照每token的错误率来评估Pre training整体效果,这肯定是没问题的,因为你没有具体的任务要去看它解决的好不好。
但是如果我们用它来评估每个具体任务是不太现实的,因为通过这个指标你没法判断每个任务到底好不好、或是否足够好(比如任务是三位数加法,你用每token错误率很难判断目前到底什么情况。假设100道题目,那需要输出大约300个数字,如果按照token错误率,如果300个输出token里错100个,那从每道题是否做对来看,正确率浮动范围很大,正确率在0%(就是每道题目都正好三个输出token里错1个)到66%之间都有可能,但是如果采用正确率就很直观,比如100道题对了70道,就是70%的正确率),所以我们真正看某个具体任务、或者做下游任务的时候肯定还是要看那个任务指标的。
所以涌现存在还是不存在?我觉得这取决于你怎么看这个事,是个看问题的角度问题。就跟从远处看一个人一样,如果你从前面看,比如从“每token错误率”看,那大模型就是没有涌现,指标是平滑增长的,但是你如果从背面看这个人,就是说我从我任务的指标来看,因为我看这个指标才能更好判断目前任务效果到底怎么样了,那你说涌现存在吗?其实还是存在的,也就是说模型小的时候我看就是不行,到了一定规模突然那个指标就上去了。所以我觉得它存在不存在取决于你从哪个角度看,人是同一个人,不同角度看上去差异就很大,所以是同一个事情的“一体两面”,而不是非此即彼,这是我的第二个看法。
第三,涌现本身的价值在哪儿?或者说我们对涌现的期望在哪儿?就像我刚才讲的,我们对涌现的本质期望是说希望我们将来把模型做大,它能把现在没有做好的做好。是这个,这篇论文它否认这个现象了吗?并没有,它只是解释一个现象而已。即使文章是完全正确的,并不妨碍我们得出这么一个结论:随着模型规模的增大,涌现是说原先不能做的突然间能做了,现在的结论是说随着模型的推大,以前做不好的我可以慢慢地做好,将来会做得越来越好,所以它并没有推翻我们对涌现的预期。所以从这个角度,我认为其实这个文章它只是对为什么我们会看到突变现象的一个解释,我记得我去年3月份也做过相关的分享,那时候也提到过这个猜想,所以说关于文章中这个解释我是赞成的,这个工作也是非常好的工作。但是这个事情我们还是要辩证全面地去看,不能说因为有人说涌现现象,就都很激动觉得大模型无所不能把它神秘化,也不能改天因为一篇文章否认涌现的存在,就认为它完全不存在,最好不要两极化走极端,这是我的第三点看法。
基础模型面向应用开发者
骆轶航:号称到时间了,我利用在台上可以不下去我准备耍个赖再延长5分钟的问题。刚才大家都讲到了一个点,也不是都讲到,大家讲到大模型、开源的模型怎么让大家用起来爽、用起来有个性,包括其实我们讨论到了所谓的Technology Transformer的问题,但其实我觉得这个事最近大家讨论得也蛮多的,关于TPEF的这个问题,大语言模型时代更要去讨论,这个比大模型时代讨论比之前移动互联网时代讨论起来要难,因为移动互联网时代技术的边界、产品经理,做应用的、做产品的他是很容易感知到的,因为一个东西实现不了就是实现不了,抖音这个东西只能等到视频技术成熟到那个阶段它才能够得到这样大的一个爆发,2013年、2014年就是出不来,你心里是知道的。
对于大模型来说,在座很多的做Agent,或者基于基础模型去做应用,做应用的其实很多人,我相信在座的很多人做应用的还是有技术积累的底子的,现在如果按各个主要的大平台的讲法,你未来不懂代码,用一些低代码你就可以去开发一个东西,大家都这么去讲。这么去讲之后,其实一个大模型、一个基础模型能帮助用户实现什么、和不能帮助用户实现什么,就包在一个黑盒子里面,你不知道它能实现什么、不能实现什么,它进了一个黑盒子,很多人就被忽悠了,结果实现不了,大模型垃圾,就变成了这样一个情况。
所以我想请教各位的是从基础模型的角度我们怎么能够跟我们的开发者,想在我们这上边做应用的人我们告诉他们我们能做什么、不能做什么,把这个大语言模型黑盒子给打开,从而让他们能够更好地管理自己真正 build up一个东西的预期,否则的话,其实对于很多基础模型可能是没有那么多好处的。这个是谁想回答谁就回答。
王铁震:这个问题其实是一个非常有意思的问题,大家一会儿陷入癫狂,觉得大语言模型无所不能,一会儿又觉得大语言模型又废了,跳出大语言模型很多事情都是这样,我记得我小时候接触互联网,还不是移动互联网,那个时候大家就说上面有很多的信息,你可以去上面搜索、可以去发现,结果被发现我们被关在推荐系统的这个牢笼里面,推给我们的信息,因为信息太多了,能够推给我们、能够有传播性的信息都是很极端的信息,他就说这个东西无所不能,我得赶紧去学一下,或者说这个东西好像就是套壳,这个是一个非常有话题性的东西,但是其实如果我们在大语言模型时代还继续这样走的话,其实我们就辜负了大语言模型,如果你去看推荐系统是把信息推给我们,你去用大语言模型的时候你是很主动地描述清楚你的需求,问大语言模型这个东西怎么怎么样,如果说有了这么好的一个工具,你还不能用它发现真相、找到一些真实的感受去做一些实证的话,这个工具就被我们浪费了。
骆轶航:你意思是开发者的问题?
王铁震:我的意思就是对开发者或者对传媒来讲,最主要的是大语言模型能够做什么?能不能在我的应用里面达到这个效果?最重要的是你先去试一下,我们做大语言模型我们是不知道用户的需求的,我们其实用大语言模型去做的这个东西,其实想象力是非常有限的,我们就知道有这么几个数据级我们去刷个榜结束了,真正做产品的人需要这个过来能不能做?如果能做,下面就不是 product market fit,而是 earning 和 cost 的fit(成本和利润的适应),就是我从大语言模型做了这个产品赚的钱能不能满足我的cost,未来有芯片的进步、有各种优化的进步,可能是这个是可以解决的,有些东西确实是大语言模型解决不了,现在最好的大语言模型都解决不了,那就不要想,那你有等等,等几年,说不定多模态识别可以用在自动驾驶了,那可能未来的时候可能有更好的模型,如果现在最好的模型都没有办法解决你的需求,那就不做。
骆轶航:其实product market fit在大语言模型领域不是讨论出来的,这个东西甚至它不存在。
王铁震:实证出来的。
骆轶航:实证出来的,所有的你绕不开它能做什么、不能做什么,没有人能够对这个事给出一个清晰的答案,有没有人有不同的看法?
林俊旸:我其实是比较buy in,因为我们大家可能体验都会比较一致,比如说上半年的时候你去卖你的大模型的时候是不好卖,有几种。第一个他可能觉得你很有意思,你根本解决不了我的问题,你到下半年之后他不一样,他用了开源模型,他知道他跟你说我要干什么,我最近跑了不少开发者,也是客户,虽然大家认知有高有低不一样,他会站在大模型角度提出他自己的问题。
骆轶航:上半年可能大家对这个东西没有一个轮廓和需求,我只知道这个东西可能我只有一个价值判断,但到了下半年我可能知道我该怎么去用了。
林俊旸:就是他知道说我想拿大模型帮他解决什么问题,而不是上半年说我为了用大模型而用大模型,这是开源的贡献。
骆轶航:这是开源的贡献还是用户自己的进步?
林俊旸:我觉得是开源的贡献,因为开源告诉大家怎么去用这个大模型,还有一种开源告诉大家大模型的潜力远不止于此,刚才铁震提到了一个很好事情,关于评测这个问题,其实背后是评测的问题,今天不管是说我们在追求榜单效果也好,还是等等也好,其实是我们自己的局限性,我们很难找到很好的评测,我们也不知道我们下游用户会去做什么,但是我们开源出去之后,大家会去报各种各样的方案,比如说今天看到 Langchain的发展,一年的发展很多,LLaMA index出来它干了很多事情,有了Agent的框架,不同的框架其实做的功能还都不一样,游戏领域也会随着Agent的框架发展做出更多有趣的事情,这个不是我们能做到的,所以今天我看这个事情我反而是学习的心态。今天2024年的这个目标我是想去学这些东西,反过来看其实是这样,所以我觉得接下来大家去用这个大模型的话肯定是能找到自己的需求,知道这个大模型怎么用。
观众提问
提问:刚才几位专家的观点我很认同,一些小模型在特定的场景下也能够追赶大模型和通用的能力,我们怎么用这些小模型更好地应用在垂直领域里面?在垂直领域去用的话怎么达到一个模型能力、算力成本和用户体验的平衡呢?这是我想问的,谢谢。
张俊林:我聊聊我的看法,我们为什么用小模型呢?我们用小模型的目的就是为了推理成本低一点,响应能够快一点,这是为什么大家想做小模型的目的。
小模型的问题是有些能力,比如刚才拆分完后说的逻辑推理能力,跟大模型比还是不如的,从这个角度上讲,小模型在成本方面肯定有巨大的优势,但它在某些方面不够好,不够好自然就产生刚才讲的用户体验问题,但我觉得可能是有解法的。
我拍脑袋举个例子,比如说你可不可以用若干个小模型,它各自擅长不同的能力,比如说这个擅长聊天、那个擅长创作,尤其重要的有一个很小的模型特别擅长逻辑推理,通过“小模型联盟”这种方式,当然前边可能要加一个分发,知道把问题发给联盟里哪个小模型,通过这种类似Agent联盟的方式,同时每个个体又是非常小的,我认为这个问题大致是可解的。所以我们讲这个问题实际本质是说小模型是我们想做的,出于成本的考虑,但是它在某些方面的能力还不足,我们能不能把这个能力补上去?我认为一方面可以采取一个小模型联盟的方式。
另外一种可能的思路,我刚才讲的我们有没有可能通过一种方式,既提升小模型的逻辑推理能力,又让它其他能力不丧失?这其实是非常重要的研究方向,而且我个人比较乐观地认为2024年应该会有一些突破性的技术出来,我是这么看这个问题的。
提问:各位老师好,我是来自学术界的,我想问一个问题,刚才提到的和学术界合作的事情,现在其实学术界能做的问题也比较有限,你们做的这些领域里面有哪些是你们觉得非常值得去研究的问题,它也是很适合去和学术界合作的?非常感谢!
林俊旸:这个点是我刚才扔出来的事情,我觉得学界和业界的合作你得看你怎么看,比如说你放到两年前,你拿着Bard也是在做微调的事情,你基础模型没有那么强,你今天拿着更强的模型RAG有很大的空间去做提升,今天即便是跟顶尖的高校的同学,美国也好、国内也好,他们其实大家讨论的还是有很多问题都是没有解决的太好,其实还能找到很多点,只是你站在一个更高的起点,说得难听一点,就是水文章没有以前那么容易了,以前你可能是本身你的基座也不咋的,你随便整整也算是突破了一个进展,你随便整整你就上不去了,大家解决硬核问题还是可以的,再加上这个平民化这个事情,不一定是说真的你需要这么多的卡才能够去做一些相应的研究,只是说我觉得学界和业界在做这件事情的时候可以做一点点互动,就是不要学界做了这个问题,即使是真实的,大家在做大模型的其实并不关心,有学界好的东西业界又用不上,把这个壁垒打掉,这个是我关心的问题。
提问:我想问一下知乎洞见上面的一个问题,就是您认为在未来的大模型里面它是会更倾向于通用型的还是专用的?包括刚才有在说的训练的语料的质量跟它的数量,哪个会是以后大模型训练的一个重点?谢谢。
黄文灏:我说一下我的观点,有可能是暴论,前面也说了,我其实是觉得小模型只是在大模型发展过程中的一个temporary的解决方案,就是它最终是会被取代掉了,所以ultimately 我们应该去支撑更大的模型,它无论在各个方面的能力上都会取代小模型。
如果考虑到成本的问题,其实你现在比如说你收入是1块钱,成本差十倍,一个花了1块钱、一个花了1毛钱,当然你觉得1毛钱有很大的优势,1块钱打不平。但如果未来它能压到非常低,低三四个数量级,1分钱和1厘钱对你收入一块钱来说其实是没有区别的。所以从动态的角度看,最终大模型它无论在通用能力领域能力上都可以碾压小模型。大家可以用现在的各种小模型、RAG这种方案找到用户真正的需求是什么,等大模型来的时候用更好的模型去提升用户体验。
第二个是训练时候的数据,我觉得质量和数量都很重要,我们的经验告诉我们数据越多,模型性能会有显著的提升,之前看到前面应该在2022年之前,175B,540B的大模型最多的数据大概是用300B的token,但现在一般即使6B、7B的模型至少也会吃3个T的token,更大的模型可能更大,就是几十T的token,这个说明数据的作用其实非常大。当然不是说我把数据拿下来自己放进去就可以了,我们自己做的时候原始数据有几十PB,能保留下来的token只有千分之一,我们要做筛选,这个对模型最后效果的提升还是非常重要的,所以我们未来要关心的是数据不够了的问题,就是有多少数据用多少数据,这样才能得到真正意义上的模型。
补充两句,有时候可能大模型它其实就是一个世界模型,你把世界所有的知识都压缩在大模型里面了,它为什么就不是一个世界模型?大家可能看过Voyager的工作,在minecraft里面用大模型做规划和执行,其实大模型就做了一个很好的neural prior,某种程度上就是一个世界模型。
提问:各位老师好,我想问的问题是各位怎么看待LeCun提出的世界模型,以及他对大语言模型的一些评论?就是大语言模型是走向AGI的一条思路?还是说它有很多机会带领大家走向AGI?
张俊林:抱歉刚才有些问题的细节没太听清楚,您的问题是大语言模型是不是通向AGI的必由之路,还是大语言模型不是通向AGI的必由之路?
如果是这样的话,这个问题其实您也看到了,现在有两派,持两种不同的观点,一种观点认为大语言模型是通往AGI的必由之路,有一些人是强烈反对的,以LeCun为代表,反对的理由一般是说大语言模型没有世界模型,就说我们这个现实世界很复杂,大语言模型通过下一个token预测,不可能构建一个复杂的世界模型,论据在这儿。
我们现在谁也没法下定论,说这两条路一定哪条路是对的。很多时候这个问题,也就是AGI问题,其实是个人信仰问题,取决于你个人信不信,我不认为现在能有一个人,他能够拿出特别明确的证据来说服其他人,说一定就是或一定就不是。
就我个人而言,我可能偏向认为大语言模型应该是能走向AGI的。如果更客观地来讲,现有我们能有的AI技术里面,大语言模型可能是往AGI走的最光明的一条道路,至于是否真能通过这条路走向AGI?两年之后我们应该就能看到结论,得出这条路是不是能走得通的一个明确结论。
当然认为大模型可以走向AGI,这也是我的个人信仰,我并没有确切的证据。比如说我就可以说:我认为next token prediction是可以产生世界模型的。当然我确实也是这么认为的,但是有的人就认为不可能,我估计要这么争的话可能谁也说服不了谁,我觉得两年之后结论自然就会出现。
我对未来两年大模型的发展还是比较乐观的,原因很简单,因为scaling law未来两年大概仍旧会成立,意思是说你只要有新的数据,大模型的效果肯定会越来越好,那我们就值得去看一看它是不是真的能走向AGI这个阶段。我们真正需要担心这个问题应该是两年之后,为什么是两年之后?是因为那个时候很可能我们的数据就不够用了,这波大模型爆发,从根本上来看,还是“数据驱动的智能”。数据如果不够用,这条路即使是可以走通的,但是没有后续数据补充也可能半途而废。假设你凭空,或者说通过合成数据的方式在我们人类产生的数据里面将来能够提供新的数据,那这条路很可能是能走通的,但两年之后很可能我们数据就已经不够用了,它可能就卡在那了。除非一点,人工合成数据对于促进大语言模型是非常有帮助的,那这条路还可以继续往后走,否则很可能会卡住,那时候大家会认为大语言模型不是走向AGI的路径,这个结论其实两年之后我们就能看到,这是我的看法,纯个人看法。
提问:老师们好,有一个工程相关的问题想请教一下,就是我们从狭义的推理定义上来讲,比如说 logic 、math、planning 和problem这样的角度上来讲,我们在 alignment这个环节是否还能对推理环节能有提升或者影响?如果不能的话,是不是我们要攻坚推理能力的话,就需要不断地迭代continue train?或者进行成本高昂的 scaling up这样的一个环节?
第二个问题,在2024年或者说未来一年里面, alignment这个环节是不是还会有突破性的工作?还是说它会成为一个常态性的工作?
林俊旸:其实第一个问题我没有太理解,是说reasoning,还是 inference 上那个工程的问题?是说能不能提升推理的能力是吧?这个问题倒是蛮好的,因为这一年来的话,其实大家做了大量的工作,让ST让这个模型推理能力变得更强,刚开始大家就是follow去年COT的做法,既然large language model 潜在的有COT这种能力,为什么我们不能把 chain of thought 放到这个 fine tuning 这个阶段呢,post training这个阶段,让它显示的这个学会。
我可以提一个我们自己的例子,我们自己怎么让自己的模型有tool use 和agent 的基础和能力的,如果你拿一个语言模型没有这个能力的话,你是没有办法去玩各种东西的,我们刚开始发现这种能力它没有办法凭空出来,我们研究看哪种方式会比较好,比如说 React 这种格式还挺好的,我其实可以做一些标注,标注完之后其实不是说让他学会用某一个工具,而是让他学会说根据工具的文档以及视力学会用他没有见过的工具,这样的话他就能够泛化了,随着模型不断地提升,这个方式再加上去等于他tool use的能力变得越来越强,现在可以看到开源模型的tool use和Agent的能力都会变得很强,所以大家真的是做了比较多的东西,我们也不知道OpenAI是怎么做的,但今天我们自己去做,我们就可以用这个笨办法把这种能力给提升出来。
来源:知乎 www.zhihu.com
作者:知乎科技
【知乎日报】千万用户的选择,做朋友圈里的新鲜事分享大牛。
点击下载