




























技术神秘化的去魅:Sora关键技术逆向工程图解
Sora生成的视频效果好吗?确实好。Sora算得上AGI发展历程上的里程碑吗?我个人觉得算。我们知道它效果好就行了,有必要知道Sora到底是怎么做的吗?我觉得最好是每个人能有知情的选择权,任何想知道的人都能够知道,这种状态比较好。那我们知道Sora到底是怎么做出来的吗?不知道。马斯克讽刺OpenAI是CloseAI,为示道不同,转头就把Grok开源了。且不论Grok效果是否足够好,马斯克此举是否有表演成分,能开源出来这行为就值得称赞。OpenAI树大招风,目前被树立成技术封闭的头号代表,想想花了上亿美金做出来的大模型,凭啥要开源?不开源确实也正常。所谓“开源固然可赞,闭源亦可理解”。但是,我个人一年多来的感觉,OpenAI技术强归强,然而有逐渐把技术神秘化的倾向,如果不信您可以去读一下Altman的各种访谈。在这个AI技术越来越封闭的智能时代,技术神秘化导向的自然结果就是盲目崇拜,智能时代所谓的“信息平权”或只能成梦想。我不认为这是一个好的趋势,我发自内心地尊敬对技术开放作出任何贡献的人或团体,且认为对技术神秘化的去魅,这应该是AI技术从业者值得追求的目标。本文试图尽我所能地以通俗易懂的方式来分析Sora的可能做法,包括它的整体结构以及关键组件。我希望即使您不太懂技术,也能大致看明白Sora的可能做法,所以画了几十张图来让看似复杂的机制更好理解,如果您看完对某部分仍不理解,那是我的问题。Key Messages这部分把本文关键信息列在这里,特供给没空或没耐心看长文的同学,当然我觉得您光看这些估计也未必能看明白。Key Message 1: Sora的整体结构如下(本文后续有逐步推导过程)Key Message 2: Sora的Visual Encoder-Decoder很可能采用了TECO(Temporally Consistent Transformer )模型的思路,而不是广泛传闻的MAGVIT-v2(本文后续给出了判断理由,及适配Sora而改造的TECO具体做法)。Encoder-Decoder部分的核心可能在于:为了能生成长达60秒的高质量视频,如何维护“长时一致性”最为关键。要在信息压缩与输入部分及早融入视频的“长时一致性”信息,不能只靠Diffusion Model,两者要打配合。Key Message 3: Sora之所以把Patch部分称为“Spacetime Latent Patch”,大概是有一定理由的/Patch部分支持“可变分辨率及可变长宽比”视频,应该是采用了NaVIT的思路,而不是Padding方案(本文后续部分给出了方案选择原因)。Key Message 4: 目前的AI发展状态下,您可能需要了解下Diffusion Model的基本原理(后文会给出较易理解的Diffusion模型基本原理介绍)Key Message 5: Video DiTs很可能长得像下面这个样子(本文后续内容会给出推导过程)Key Message 6: Sora保持生成视频的“长时一致性”也许会采取暴力手段(后文给出了可能采用的其它非暴力方法FDM)Key Message 7: Sora应该包含双向训练过程(后文给出了双向训练的可能实现机制)为何能对Sora进行逆向工程能否对Sora进行逆向工程,要依赖一些基本假设,若基本假设成立,则逆向工程可行,如不成立,则无希望。上面列出了Sora可被逆向工程的两个基本假设。首先,我们假设Sora并未有重大算法创新,是沿着目前主流技术的渐进式改进。这条无论是从OpenAI的算法设计哲学角度(我来替OpenAI归纳下核心思想:简洁通用的模型结构才具备Scale潜力,如果可能的话,尽量都用标准的Transformer来做,因为它的Scale潜力目前被验证是最好的,其它想取代Transformer的改进模型都请靠边站。模型结构改进不是重点,重点在于怼算力怼数据,通过Scale Transformer的模型规模来获取大收益。),还是历史经验角度(比如ChatGPT,关键技术皆参考业界前沿技术,RLHF强化学习是OpenAI独创的,但并非必需品,比如目前有用DPO取代RLHF的趋势)来看,这个条件大体应该是成立的。第二个条件,其实Sora技术报告透漏了不少关于模型选型的信息,但是您得仔细看才行。关于Sora技术报告透漏的信息,这里举个例子。它明确提到了使用图片和视频联合训练模型,而不像大多数视频生成模型那样,在训练的时候只用视频数据。这是关键信息,对保证Sora效果也肯定是个重要因素,原因后文会谈。既然Sora需要图片和视频联合训练,这等于对Sora内部结构怎么设计增加了约束条件,而这有利于我们进行逆向工程。再举个例子,Sora应采取了逐帧生成的技术路线,而不像很多视频生成模型那样,采取“关键帧生成+插帧”的模式。上图中Sora技术报告标红圈的部分是支持这一判断的部分证据,如果您参考的文献足够多,会发现一旦提“generating entire video all at once”,一般和“at once”对应的方法指的就是“关键帧+插帧”的模式。上图下方给出了Google 的视频生成模型Lumiere的论文摘要(可参考:Lumiere: A Space-Time Diffusion Model for Video Generation),也提到了“at once”等字眼,表明自己用的不是“关键帧+插帧”的模式,这是把“at once”作为论文创新点高度来提的。“关键帧生成+插帧”是视频生成模型中普遍采用的模式,但它的问题是会导致生成的视频整体动作幅度很小、而且不好维护全局的时间一致性。我们看到市面上很多视频生成产品都有这个问题,就可以倒推它们大概采用了“关键帧+插帧”的模式。可以看出,这点也是保证Sora视频质量好的重要技术选型决策,但若您看文献不够仔细,就不太容易发现这个点。归纳一下,之所以我们能对Sora进行逆向工程,是因为前述两个基本假设大致成立,而每当Sora技术报告透漏出某个技术选型,就等于我们在算法庞大的设计空间里就去掉了很多种可能,这相当于通过对主流技术进行不断剪枝,就可逐步靠近Sora的技术真相。接下来让我们根据目前的主流技术,结合Sora的技术报告,假设Sora模型已经训练好了,来一步步推导出Sora可能采用的整体技术架构。逐步推导Sora的整体结构Sora给人的第一印象是高质量的生成模型:用户输入Prompt说清楚你想要生成视频的内容是什么,Sora能生成真实度很高的10秒到60秒的视频。至于内部它是怎么做到这一点的,目前我们还一无所知。首先,我们可如上图所示,技术性地稍微展开一下,细化Sora的整体轮廓。用户给出相对较短且描述粗略的Prompt后,Sora先用GPT对用户Prompt进行扩写,扩充出包含细节描述的长Prompt,这个操作是Sora技术报告里明确提到的。这步Prompt扩写很重要,Prompt对细节描述得越明确,则视频生成质量越好,而靠用户写长Prompt不现实,让GPT来加入细节描述,这体现了“在尽可能多的生产环节让大模型辅助或取代人”的思路。那么,Sora内部一定有文本编码器(Text Encoder),把长Prompt对应的文字描述转化成每个Token对应的Embedding,这意味着把文字描述从文本空间转换为隐空间(Latent Space)的参数,而这个Text Encoder大概率是CLIP模型对应的“文本编码器”(CLIP学习到了两个编码器:“文本编码器”及“图片编码器”,两者通过CLIP进行了文本空间和图片空间的语义对齐),DALLE 系列里的文本编码器使用的就是它。上文分析过,Sora应该走的是视频逐帧生成的路子,假设希望生成10秒长度、分辨率为1080*1080的视频,按照电影级标准“24帧/秒”流畅度来算,可知Sora需要生成24*10=240帧1080*1080分辨率的图片。所以,若已知输出视频的长度和分辨率,我们可以在生成视频前,事先产生好240帧1080*1080的噪音图,然后Sora在用户Prompt语义的指导下,按照时间顺序,逐帧生成符合用户Prompt描述的240张视频帧对应图片,这样就形成了视频生成结果。从Sora技术报告已知,它采用的生成模型是Diffusion模型,关于Diffusion模型的基本原理我们放在后文讲解,但现在面临的问题是:Diffusion Model也有不同的做法,到底Sora用的是像素空间(Pixel Space)的Diffusion Model,还是隐空间(Latent Space)的Diffusion Model呢?现在我们需要关于此做出技术决策。在做决策前,先了解下两个空间的Diffusion Model对应的特点。上图展示的是在像素空间内做Diffusion Model的思路,很直观,就是说在像素范围内通过Diffusion Model进行加噪音和去噪音的过程。因为图片包含像素太多,比如1080*1080的一张图片,就包含超过116万个像素点,所以像素空间的Diffusion Model就需要很大的计算资源,而且无论训练还是推理,速度会很慢,但是像素空间保留的细节信息丰富,所以像素空间的Diffusion Model效果是比较好的。这是它的特点。再说隐空间Diffusion Model的特点。最早的Diffusion Model都是在像素空间的,但速度实在太慢,所以后来有研究人员提出可以在对像素压缩后的隐空间内做Diffusion Model。具体而言,就是引入一个图像“编码器”(Encoder)和“解码器”(Decoder),编码器负责把图片表征从高维度的像素空间压缩到低维度的参数隐空间,而在经过Diffusion Model去噪后,生成隐空间内的图片内容,再靠解码器给隐空间图片内容添加细节信息,转换回图片像素空间。可以看出,Latent Diffusion Model(LDM)的特点正好和Pixel Diffusion Model(PDM)相反,节省资源速度快,但是效果比PDM差点。现在来做技术选型,从Sora技术报告明显可看出,它采用的是Latent Diffusion Model,这个也正常,目前无论做图像还是视频生成,很少有用Pixel Diffusion Model,大部分都用LDM。但是,LDM也存在一个压缩率的问题,可以压缩得比较狠,这样速度会更快,也可以压缩的不那么狠。我猜Sora在Encoder这一步不会压缩得太狠,这样就能保留更多原始图片细节信息,效果可能会更好些。Sora大概率会重点保证生成视频的质量,为此可以多消耗些计算资源,“以资源换质量”。Sora生成视频速度很慢,很可能跟Encoder压缩率不高有一定关系。于是,目前我们得到上图所示的Sora整体结构图,主要变化是增加了针对视频的Encoder和Decoder,以试图加快模型训练和推理速度。另外,一般把文本编码结果作为LDM模型的输入条件,用来指导生成图片或视频的内容能遵循用户Prompt描述。现在,我们面临新的技术决策点:对视频帧通过Encoder压缩编码后,是否会有Patchify(中文翻译是“切块”?不确定)操作?Patchify本质上可看成对视频数据的二次压缩,从Sora技术报告可看出,它应有此步骤,这也很正常,目前的视频生成模型一般都包含这个步骤。而且Sora将他们自己的做法称为“Spacetime Latent Patch”,至于为啥这么叫,我在后文关键模块分析会给出一个解释。另外,Sora还主打一个“支持不同分辨率、不同长宽比”的图片与视频生成,为了支持这个功能,那在Patchify这步就需要做些特殊的处理。于是,加入Spacetime Latent Patch后,目前的Sora整体结构就如上图所示。Patchify一般放在视频编码器之后,而且输出时把多维的结果打成一维线性的,作为后续Diffusion Model的输入。我们接着往下推导,来看下实现Diffusion M

Sora生成的视频效果好吗?确实好。Sora算得上AGI发展历程上的里程碑吗?我个人觉得算。我们知道它效果好就行了,有必要知道Sora到底是怎么做的吗?我觉得最好是每个人能有知情的选择权,任何想知道的人都能够知道,这种状态比较好。那我们知道Sora到底是怎么做出来的吗?不知道。
马斯克讽刺OpenAI是CloseAI,为示道不同,转头就把Grok开源了。且不论Grok效果是否足够好,马斯克此举是否有表演成分,能开源出来这行为就值得称赞。OpenAI树大招风,目前被树立成技术封闭的头号代表,想想花了上亿美金做出来的大模型,凭啥要开源?不开源确实也正常。所谓“开源固然可赞,闭源亦可理解”。
但是,我个人一年多来的感觉,OpenAI技术强归强,然而有逐渐把技术神秘化的倾向,如果不信您可以去读一下Altman的各种访谈。在这个AI技术越来越封闭的智能时代,技术神秘化导向的自然结果就是盲目崇拜,智能时代所谓的“信息平权”或只能成梦想。我不认为这是一个好的趋势,我发自内心地尊敬对技术开放作出任何贡献的人或团体,且认为对技术神秘化的去魅,这应该是AI技术从业者值得追求的目标。
本文试图尽我所能地以通俗易懂的方式来分析Sora的可能做法,包括它的整体结构以及关键组件。我希望即使您不太懂技术,也能大致看明白Sora的可能做法,所以画了几十张图来让看似复杂的机制更好理解,如果您看完对某部分仍不理解,那是我的问题。
Key Messages
这部分把本文关键信息列在这里,特供给没空或没耐心看长文的同学,当然我觉得您光看这些估计也未必能看明白。
Key Message 1: Sora的整体结构如下(本文后续有逐步推导过程)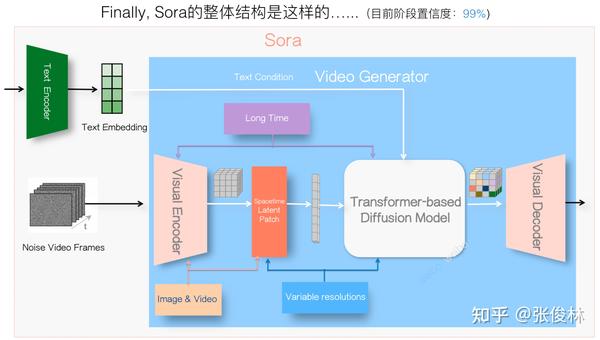
Key Message 2: Sora的Visual Encoder-Decoder很可能采用了TECO(Temporally Consistent Transformer )模型的思路,而不是广泛传闻的MAGVIT-v2(本文后续给出了判断理由,及适配Sora而改造的TECO具体做法)。Encoder-Decoder部分的核心可能在于:为了能生成长达60秒的高质量视频,如何维护“长时一致性”最为关键。要在信息压缩与输入部分及早融入视频的“长时一致性”信息,不能只靠Diffusion Model,两者要打配合。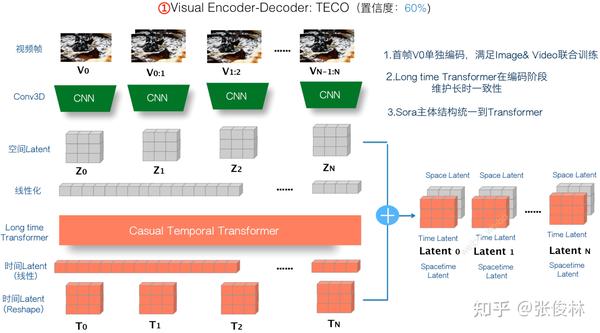
Key Message 3: Sora之所以把Patch部分称为“Spacetime Latent Patch”,大概是有一定理由的/Patch部分支持“可变分辨率及可变长宽比”视频,应该是采用了NaVIT的思路,而不是Padding方案(本文后续部分给出了方案选择原因)。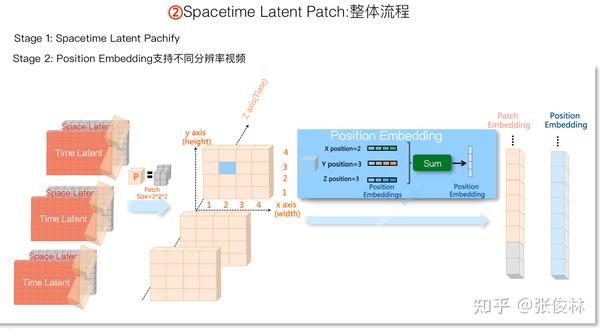
Key Message 4: 目前的AI发展状态下,您可能需要了解下Diffusion Model的基本原理(后文会给出较易理解的Diffusion模型基本原理介绍)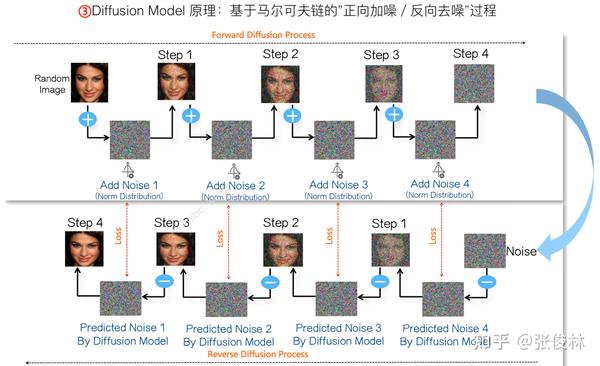
Key Message 5: Video DiTs很可能长得像下面这个样子(本文后续内容会给出推导过程)
Key Message 6: Sora保持生成视频的“长时一致性”也许会采取暴力手段(后文给出了可能采用的其它非暴力方法FDM)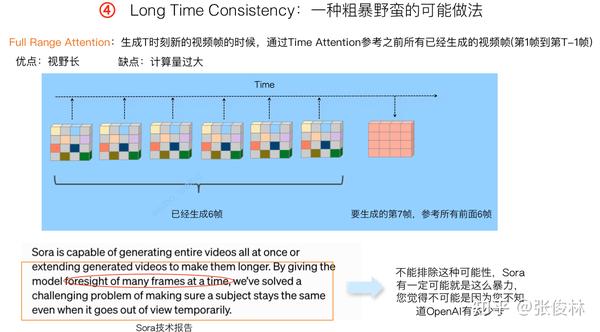
Key Message 7: Sora应该包含双向训练过程(后文给出了双向训练的可能实现机制)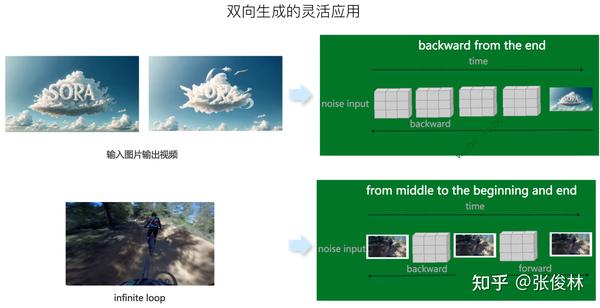
为何能对Sora进行逆向工程

能否对Sora进行逆向工程,要依赖一些基本假设,若基本假设成立,则逆向工程可行,如不成立,则无希望。上面列出了Sora可被逆向工程的两个基本假设。
首先,我们假设Sora并未有重大算法创新,是沿着目前主流技术的渐进式改进。这条无论是从OpenAI的算法设计哲学角度(我来替OpenAI归纳下核心思想:简洁通用的模型结构才具备Scale潜力,如果可能的话,尽量都用标准的Transformer来做,因为它的Scale潜力目前被验证是最好的,其它想取代Transformer的改进模型都请靠边站。模型结构改进不是重点,重点在于怼算力怼数据,通过Scale Transformer的模型规模来获取大收益。),还是历史经验角度(比如ChatGPT,关键技术皆参考业界前沿技术,RLHF强化学习是OpenAI独创的,但并非必需品,比如目前有用DPO取代RLHF的趋势)来看,这个条件大体应该是成立的。
第二个条件,其实Sora技术报告透漏了不少关于模型选型的信息,但是您得仔细看才行。
关于Sora技术报告透漏的信息,这里举个例子。它明确提到了使用图片和视频联合训练模型,而不像大多数视频生成模型那样,在训练的时候只用视频数据。这是关键信息,对保证Sora效果也肯定是个重要因素,原因后文会谈。既然Sora需要图片和视频联合训练,这等于对Sora内部结构怎么设计增加了约束条件,而这有利于我们进行逆向工程。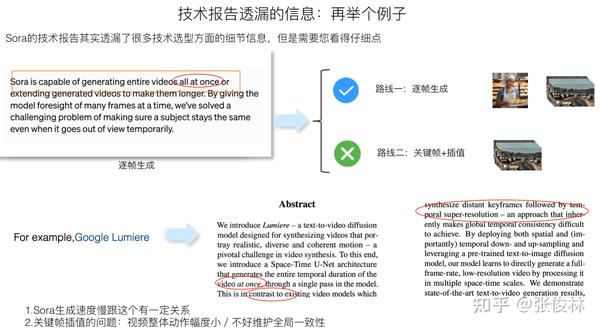
再举个例子,Sora应采取了逐帧生成的技术路线,而不像很多视频生成模型那样,采取“关键帧生成+插帧”的模式。上图中Sora技术报告标红圈的部分是支持这一判断的部分证据,如果您参考的文献足够多,会发现一旦提“generating entire video all at once”,一般和“at once”对应的方法指的就是“关键帧+插帧”的模式。上图下方给出了Google 的视频生成模型Lumiere的论文摘要(可参考:Lumiere: A Space-Time Diffusion Model for Video Generation),也提到了“at once”等字眼,表明自己用的不是“关键帧+插帧”的模式,这是把“at once”作为论文创新点高度来提的。
“关键帧生成+插帧”是视频生成模型中普遍采用的模式,但它的问题是会导致生成的视频整体动作幅度很小、而且不好维护全局的时间一致性。我们看到市面上很多视频生成产品都有这个问题,就可以倒推它们大概采用了“关键帧+插帧”的模式。可以看出,这点也是保证Sora视频质量好的重要技术选型决策,但若您看文献不够仔细,就不太容易发现这个点。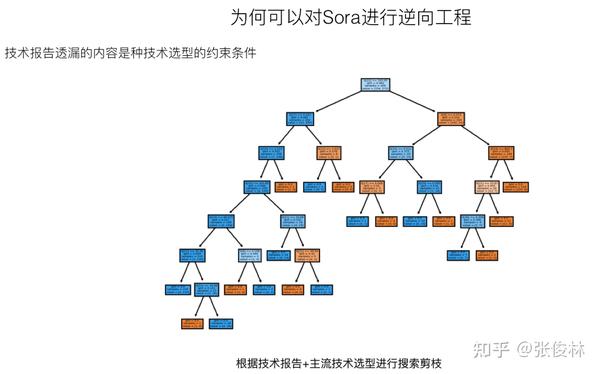
归纳一下,之所以我们能对Sora进行逆向工程,是因为前述两个基本假设大致成立,而每当Sora技术报告透漏出某个技术选型,就等于我们在算法庞大的设计空间里就去掉了很多种可能,这相当于通过对主流技术进行不断剪枝,就可逐步靠近Sora的技术真相。
接下来让我们根据目前的主流技术,结合Sora的技术报告,假设Sora模型已经训练好了,来一步步推导出Sora可能采用的整体技术架构。
逐步推导Sora的整体结构

Sora给人的第一印象是高质量的<文本-视频>生成模型:用户输入Prompt说清楚你想要生成视频的内容是什么,Sora能生成真实度很高的10秒到60秒的视频。至于内部它是怎么做到这一点的,目前我们还一无所知。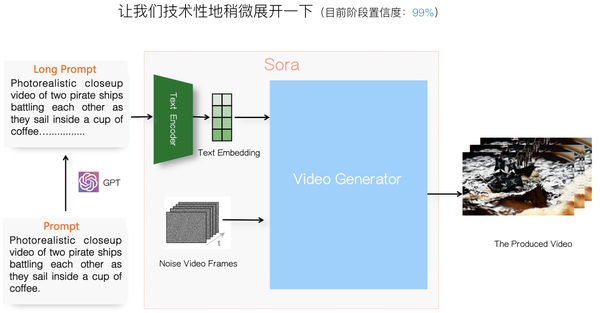
首先,我们可如上图所示,技术性地稍微展开一下,细化Sora的整体轮廓。
用户给出相对较短且描述粗略的Prompt后,Sora先用GPT对用户Prompt进行扩写,扩充出包含细节描述的长Prompt,这个操作是Sora技术报告里明确提到的。这步Prompt扩写很重要,Prompt对细节描述得越明确,则视频生成质量越好,而靠用户写长Prompt不现实,让GPT来加入细节描述,这体现了“在尽可能多的生产环节让大模型辅助或取代人”的思路。
那么,Sora内部一定有文本编码器(Text Encoder),把长Prompt对应的文字描述转化成每个Token对应的Embedding,这意味着把文字描述从文本空间转换为隐空间(Latent Space)的参数,而这个Text Encoder大概率是CLIP模型对应的“文本编码器”(CLIP学习到了两个编码器:“文本编码器”及“图片编码器”,两者通过CLIP进行了文本空间和图片空间的语义对齐),DALLE 系列里的文本编码器使用的就是它。
上文分析过,Sora应该走的是视频逐帧生成的路子,假设希望生成10秒长度、分辨率为1080*1080的视频,按照电影级标准“24帧/秒”流畅度来算,可知Sora需要生成24*10=240帧1080*1080分辨率的图片。所以,若已知输出视频的长度和分辨率,我们可以在生成视频前,事先产生好240帧1080*1080的噪音图,然后Sora在用户Prompt语义的指导下,按照时间顺序,逐帧生成符合用户Prompt描述的240张视频帧对应图片,这样就形成了视频生成结果。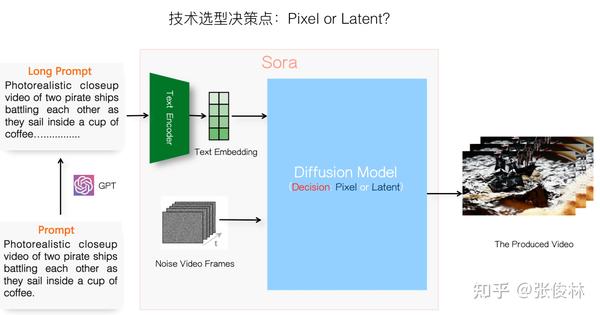
从Sora技术报告已知,它采用的生成模型是Diffusion模型,关于Diffusion模型的基本原理我们放在后文讲解,但现在面临的问题是:Diffusion Model也有不同的做法,到底Sora用的是像素空间(Pixel Space)的Diffusion Model,还是隐空间(Latent Space)的Diffusion Model呢?现在我们需要关于此做出技术决策。
在做决策前,先了解下两个空间的Diffusion Model对应的特点。上图展示的是在像素空间内做Diffusion Model的思路,很直观,就是说在像素范围内通过Diffusion Model进行加噪音和去噪音的过程。因为图片包含像素太多,比如1080*1080的一张图片,就包含超过116万个像素点,所以像素空间的Diffusion Model就需要很大的计算资源,而且无论训练还是推理,速度会很慢,但是像素空间保留的细节信息丰富,所以像素空间的Diffusion Model效果是比较好的。这是它的特点。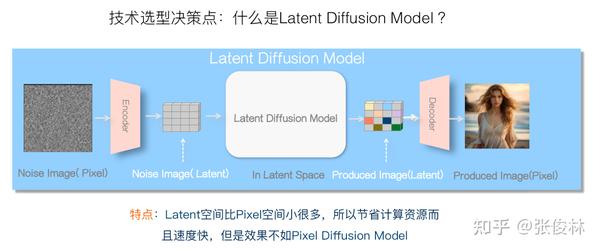
再说隐空间Diffusion Model的特点。最早的Diffusion Model都是在像素空间的,但速度实在太慢,所以后来有研究人员提出可以在对像素压缩后的隐空间内做Diffusion Model。具体而言,就是引入一个图像“编码器”(Encoder)和“解码器”(Decoder),编码器负责把图片表征从高维度的像素空间压缩到低维度的参数隐空间,而在经过Diffusion Model去噪后,生成隐空间内的图片内容,再靠解码器给隐空间图片内容添加细节信息,转换回图片像素空间。可以看出,Latent Diffusion Model(LDM)的特点正好和Pixel Diffusion Model(PDM)相反,节省资源速度快,但是效果比PDM差点。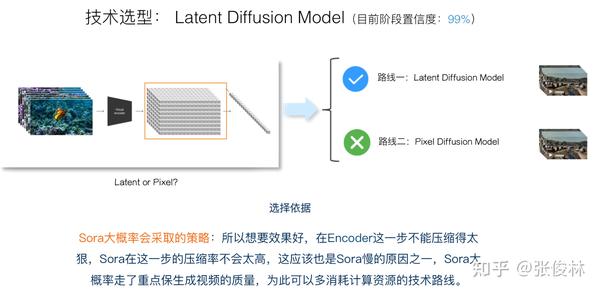
现在来做技术选型,从Sora技术报告明显可看出,它采用的是Latent Diffusion Model,这个也正常,目前无论做图像还是视频生成,很少有用Pixel Diffusion Model,大部分都用LDM。但是,LDM也存在一个压缩率的问题,可以压缩得比较狠,这样速度会更快,也可以压缩的不那么狠。我猜Sora在Encoder这一步不会压缩得太狠,这样就能保留更多原始图片细节信息,效果可能会更好些。Sora大概率会重点保证生成视频的质量,为此可以多消耗些计算资源,“以资源换质量”。Sora生成视频速度很慢,很可能跟Encoder压缩率不高有一定关系。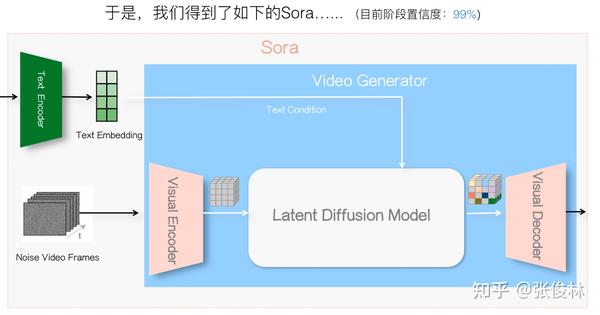
于是,目前我们得到上图所示的Sora整体结构图,主要变化是增加了针对视频的Encoder和Decoder,以试图加快模型训练和推理速度。另外,一般把文本编码结果作为LDM模型的输入条件,用来指导生成图片或视频的内容能遵循用户Prompt描述。
现在,我们面临新的技术决策点:对视频帧通过Encoder压缩编码后,是否会有Patchify(中文翻译是“切块”?不确定)操作?Patchify本质上可看成对视频数据的二次压缩,从Sora技术报告可看出,它应有此步骤,这也很正常,目前的视频生成模型一般都包含这个步骤。而且Sora将他们自己的做法称为“Spacetime Latent Patch”,至于为啥这么叫,我在后文关键模块分析会给出一个解释。另外,Sora还主打一个“支持不同分辨率、不同长宽比”的图片与视频生成,为了支持这个功能,那在Patchify这步就需要做些特殊的处理。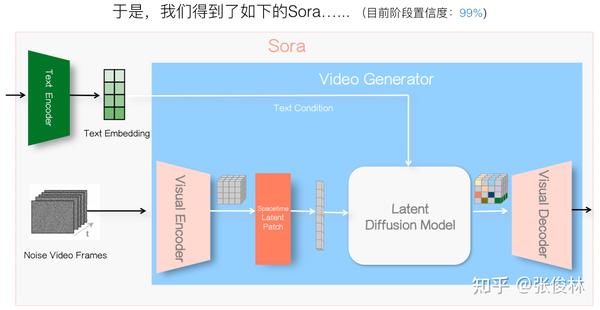
于是,加入Spacetime Latent Patch后,目前的Sora整体结构就如上图所示。Patchify一般放在视频编码器之后,而且输出时把多维的结果打成一维线性的,作为后续Diffusion Model的输入。
我们接着往下推导,来看下实现Diffusion Model时具体采用的神经网络结构,此处需注意,Diffusion Model是种偏向数学化的算法思想,具体实现时可以采用不同的神经网络结构。其实目前Diffusion Model视频生成的主流网络结构一般会用U-Net,Transformer做Diffusion 视频生成目前并非主流。当然,Sora出现之后,选择Transformer来做Diffusion Model肯定很快会成为主流结构。从Sora技术报告可知,它采用的骨干网络是Transformer,应该主要看中了它良好的可扩展性,方便把模型规模推上去。当然用Transformer+Diffusion做视频生成,Sora并不是第一个这么做的,这再次印证了OpenAI经常干的那种操作,就是利用“吸星大法”从开源届汲取各种前沿思路,但是自己反而越来越封闭的CloseAI作风。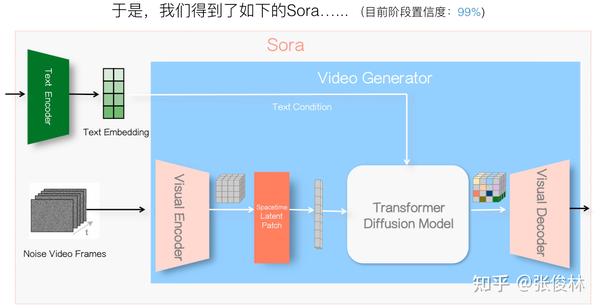
于是,我们把基于Transformer网络结构的信息融进去,目前Sora整体结构如上图所示。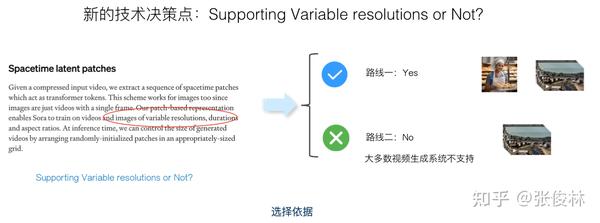
让我们继续。Sora在宣传时特别强调一个特性:可以支持不同分辨率(Variable Resolution)、不同长宽比(Various Aspect Ratio)、不同时长(Various Duration)的视频训练与生成。目前主流技术里这么做的不能说没有,但是确实极少,三者同时做到的在公开文献里我没有看到过,要做到这一点,对具体技术选型时也有不少要求,所以作为宣传点无可厚非。后文为了表达简洁些,统一以“不同分辨率”来同时代表“不同分辨率和不同长宽比”,这点在阅读后文的时候还请注意。关于生成视频时长问题我们后文会单独分析。
这里先解释下什么是“不同分辨率和长宽比”。如上图所示,其实好理解,分辨率的话一般跟图片大小有关系,图片小分辨率就低一些,图片大清晰度或分辨率就高一些,而长宽比就比如我们经常看到的短视频的“竖屏模式”和长视频的“横屏模式”等。Sora都支持。
那为啥要支持“不同的分辨率和长宽比”呢?上图给了个例子,目前做视频或者图片生成的主流技术,为了方面内部处理(训练时Batch内数据的规则性),会把输入的图片或视频大小统一起来,比如对于不同大小的图片,通过Crop操作,就是在图片中心截取一个正方形的图片片段,通过这种方式把输入大小统一。而这么做的问题上图展示出来了,因为你截图,所以很容易把一个完整的实体切割开,使用这种经过Crop数据训练的视频生成模型,生成的人体就很容易看着不完整,而使用“不同的分辨率和长宽比”,会保持原始数据所有信息,就没有这个问题,实体表达的完整性就会好很多。从这也可看出,Sora为了保视频质量,真的是在视频生成的全环节都拼了全力。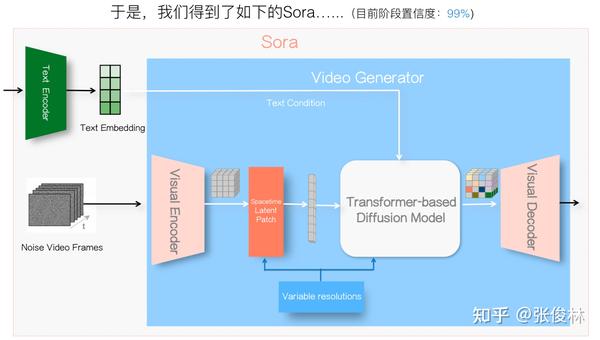
我们把Sora这一关键特性表达到整体结构图上,就如上图所示。如果要支持这一特点,那么在Spacetime Latent Patch以及LDM这两个阶段,需要作出一些特殊的设计决策,这也是我们用来在后面推断Sora关键技术的重要参考和约束信息。
下一个决策点之前我们提到过,Sora使用了图片和视频联合训练,这对于保证视频生成质量很重要。
为啥说这点重要呢?上图给了个例子(可参考Phenaki: Variable Length Video Generation From Open Domain Textual Description),用户Prompt要求输出的视频是“Water Color Style”风格的,如果只用视频训练(右侧视频截图),就做不到这一点,而如果混合了80%的视频数据和20%的图片数据训练的视频生成模型(左侧视频截图),做得就不错。这是因为带标注的<文本-图片>数据量多,所以各种风格的图片数据都包含,而带标视频数据数量少,所以很多情景要求下的数据都没有,就导致了这种生成结果的差异。从此例子可以看出视频和图片联合训练对于视频生成质量的影响。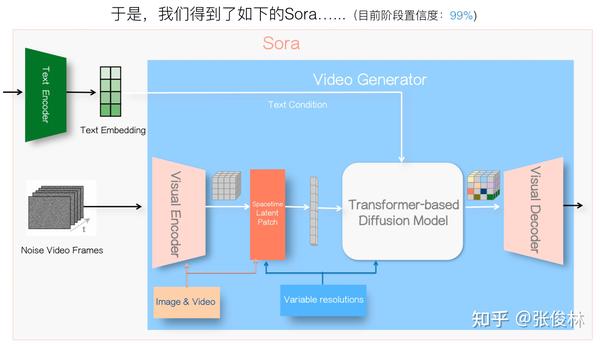
如果Sora要支持图片和视频联合训练,则需要在视频编码-解码器,以及Spacetime Latent Patch阶段做技术选型要作出独特的设计,这进一步形成了关键模块的设计约束。加上越多约束,其实你能做的技术选择就越少,就越容易推断出具体的做法。目前的Sora整体结构如上图所示。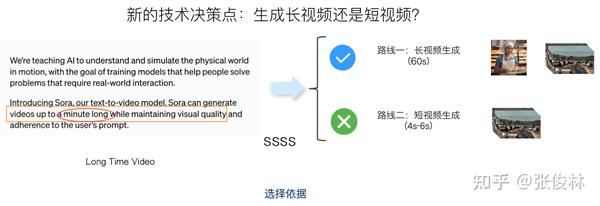
Sora的另外一大特性是能生成长达60秒的较长时长的视频,这点众所周知。
如果把时长要求加进去,Sora应该会在“视觉编码器-解码器”阶段,以及LDM阶段作出一些独特的设计,才有可能维护这么长时间的视觉连贯性和内容一致性。把所有这些约束都加入后,我们就经过一步步推导,最终得出了Sora完整的整体结构,如上图所示。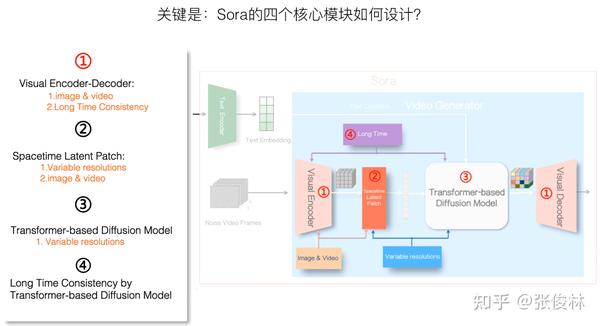
如果对文生视频领域比较熟悉,我觉得从技术报告推导出Sora的整体结构,这事难度不算大,真正难的地方在于Sora关键模块具体采用的什么技术。可列出的关键技术主要有四块:
- 视频编码器-解码器
在支持“图片&&视频联合训练”、“视频长时一致性”这两个约束条件下,具体模型应该如何设计? - Spacetime Latent Patch
在支持“图片&&视频联合训练”、“可变分辨率”这两个约束条件下,具体模型应该如何设计? - 基于Transformer的视频Diffusion Model
在支持“可变分辨率”约束条件下,具体模型应该如何设计?(这块的长时一致性策略放在第四部分了) - Diffusion Model阶段的长时一致性如何维护?
接下来,我们对Sora四个关键技术进行更深入的分析。
视频编码器-解码器:从VAE到TECO(Temporally Consistent Transformer )

Sora的视频Encoder-Decoder采用VAE模型概率极大,原因很简单,因为绝大多数图片或视频模型基本都用VAE,定位到VAE不难,难在继续探索Sora可能使用的到底是哪个具体模型。
VAE模型出来后有不少改进模型,总体而言可分为两大类:“连续Latent” 模型和“离散Latent”模型。VAE本身是连续Latent的,而离散Latent模型变体众多,最常用的包括VQ-VAE和VQ-GAN,这两位在多模态模型和图片、视频各种模型中经常现身。“离散Latent”之所以比较火,这与GPT模型采用自回归生成离散Token模式有一定关联,使用离散Latent模型,比较容易套到类似LLM的Next Token的生成框架里,有望实现语言模型和图片、视频生成模型的一体化,典型的例子就是谷歌的VideoPoet。
考虑到Sora主干模型采用Diffusion Model而非Next Token这种类LLM模式,而Diffusion Model加噪去噪的过程,本就比较适合在连续Latent空间进行,可以推断Sora采用“连续Latent”的模式概率较大,倒不是说离散Latent模型不能做Diffusion Model,也是可以的,但如果这么做,一方面把本来是连续Latent的VAE多做一道转成离散Latent,感觉没有太大必要性,有点多此一举的味道。另一方面,如果对接Diffusion Model,离散Latent效果肯定是不如连续Latent的,原因后面会谈。
之前不少探索Sora实现原理的技术文献把Sora可能使用的Encoder-Decoder定位到MAGVIT-v2模型(可参考:Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation),它是VQ-VAE的一个变种。不清楚得出这个判断的原因是什么,但我个人感觉采用MAGVIT-v2的概率应该不大,反而是VQ-GAN的变体模型TECO(Temporally Consistent Transformer)可能性更高些,理由后面会谈到。当然如果适配Sora的一些要求,TECO也需要做出些改动,具体怎么改后文也会谈。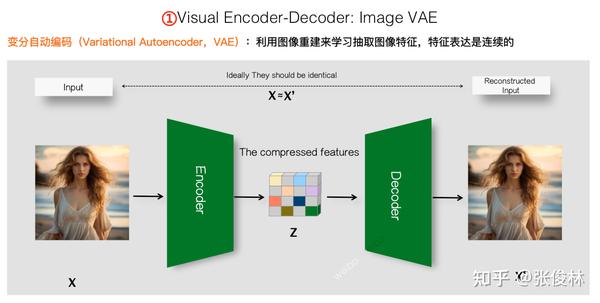
为了便于理解后续内容,先介绍下图片VAE模型的基本思路。如上图所示,VAE是种类似GPT的自监督学习,不需要标注数据,只要有足够图片数据就能训练模型。VAE的基本思想是通过重建图片,来获得一个Encoder和对应的Decoder。
输入随机某张图片 后,Encoder对像素进行压缩,形成一个低维的图片特征压缩表示
,而Decoder与Encoder相反,从压缩后的图片Latent表征
,试图还原原始图像
,产生重建的图像
,重建过程中
和
的差异就可以作为训练模型的损失函数,以此引导VAE模型的encoder产生高质量的压缩表示
,decoder则从压缩表示中尽可能准确地还原
。一般会采用CNN卷积网络来做Encoder和Decoder,所以VAE本身产生的图片Latent表征,本来就是连续的。
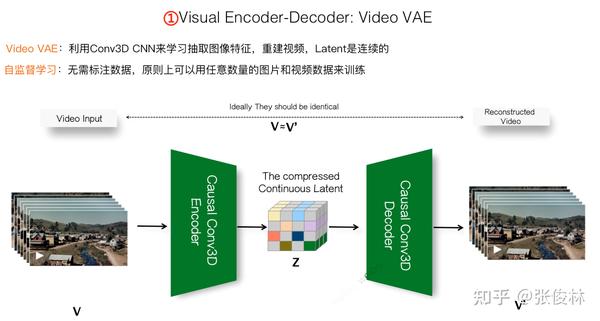
说完图片VAE的思路,再来谈视频VAE的基本思想。如果把一张图片看作是世界某个时刻三维空间的二维压缩表示,那视频就在此之上,加入时间维度,可看做沿着时间轴由若干连续的二维Space图片组成的某段物理世界场景的三维Space-time表征。
于是,视频可以被看成是由多张图片沿着时间轴组成的有序图片序列,视频VAE的任务和图片VAE是类似的,就是尽可能准确地重建组成视频的每一帧,在重建视频的过程中学习视频压缩Encoder和视频解压缩Decoder。
一般Encoder可以使用Causal CNN 3D卷积来做,和图片的2D卷积意思类似,最大的不同在于,CNN的卷积核从2D升级成3D卷积。就是说在压缩第 帧图片的时候,不仅仅像图片2D卷积一样只参考第
帧图片内容,也可以参考第
等之前的
帧图片,所以是一种casual 3D卷积(Causal的意思是只能参考前面的,不能参考后面的,因为对于视频生成来说,后面的帧还没生成,所以是不可能参考到的,但是第
帧之前的
帧已经生成了,所以在生成第
帧的时候是可以参考的。一般这种就叫causal(因果),类似GPT生成Next Token的时候只能参考之前已经生成的Token,这是为啥GPT的attention被称作Causal Attention。)
3D卷积因为在重建第 帧的时候参考了之前的
帧,这其实融入时间信息了,如果
可以拉到比较长的时间,那么对于维护生成图像的时间一致性是有帮助的。但是,仅靠CNN 卷积一般融入的历史比较短,很难融入较长时间的信息,所以需要有新思路,至于新思路是什么,这个晚些会谈。

简单介绍下“连续Latent”和“离散Latent”的概念。如上图所示,如果使用CNN卷积操作对图片进行扫描,因为卷积结果数值是在连续实数范围内,所以得到的卷积结果自然就是连续的Latent。所谓“离散Latent”,就是把“连续Latent”进行ID化,从实数向量通过一定方法转换成一个专属ID编号,这跟LLM里的字符串Tokenizer离散化过程是比较像的。
具体而言,一般对“连续Latent”离散化过程的基本思想可参考上图中的右侧子图:模型维护一个“密码本”(Codebook),密码本由很多Codeword构成,每项Codeword维护两个信息,一个是这个Codeword对应的Latent特征Embedding,这是连续的,另外就是这个Codeword对应的专属ID编号。Codebook类似词典信息。在离散化过程中,对于某个待离散化的”连续Latent”,会和密码本里每个Codeword对应的Embedding比对下,找到最接近的,然后把Codeword对应的ID赋予待离散化Latent。你看,其实很简单。
这里解释下前面提到的一点:为何说对于Diffusion Model来说,“离散Latent”的效果应该比不上“连续Latent”。其实从上面离散化过程可以看出来,本质上”连续Latent”离散化过程,可以看成对图片片段聚类的过程,赋予的那个ID编号其实等价于聚类的类编号。目前的图像处理而言,Codeword通常在8000左右,如果再大效果反而不好,这里就看出一个问题了,这种聚类操作导致很多“大体相似,但细节不同”的图片被赋予相同的ID,这意味着细节信息的丢失,所以离散化操作是有信息损失的。这是为何说如果对接Diffusion Model最好还是用“连续Latent”的原因,因为保留的图片细节的信息含量更多,有利于后续生成更高质量的视频内容。
再说“离散Latent”的一个典型模型VQ-VAE(可参考:Neural Discrete Representation Learning),思路如上图所示,其实就是刚提到的如何对VAE获得的“连续Latent”进行离散化的过程,思路已说过,此处不赘述。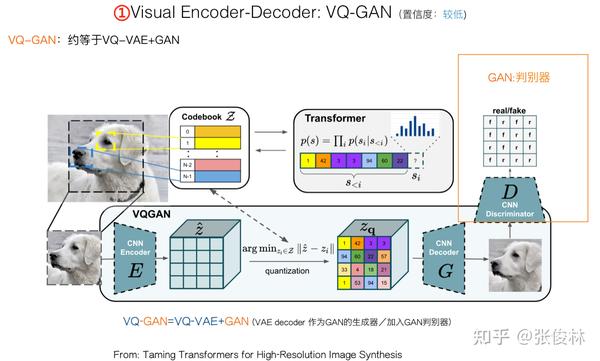
另外一个“离散化Latent”的典型是VQ-GAN(可参考:Taming Transformers for High-Resolution Image Synthesis),其思路可参考上图。可以把它简单理解成加入了GAN的改进版本VQ-VAE。在VQ-VAE离散化基础上,集成进GAN的思路,以获得更好的编码效果。我们知道,对于GAN而言,主要是由一个“生成器”和一个“判别器”相互欺骗对抗来优化模型效果,VAE Decoder 会生成图像,自然这可作为GAN天然的生成器,再引入一个独立的GAN判别器即可。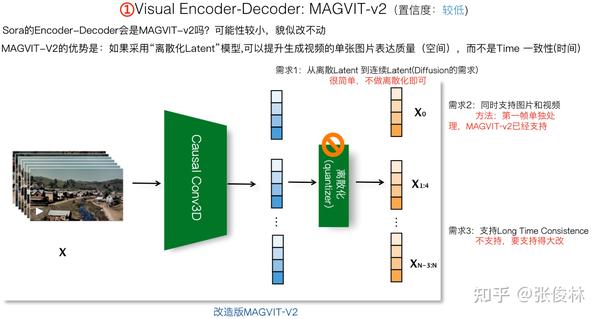
那Sora到底用的哪个VAE模型呢?上图展示了传说中被提及率最高的MAGVIT-2。过程较为简单,它把输入视频帧分组,首帧单独作为一组(这导致它可以支持“图片&&视频的联合训练”,因为图片可看成单帧的视频,首帧单独表示就可以对单张图片进行编码了),其它帧比如可以4帧分为一组。对于每一组4帧图片,通过Causal 3D 卷积把4帧图片先压缩成一个“连续Latent”。然后再进行上面讲的“连续Latent”离散化操作,就得到了MAGVIT的编码结果。
我们先不考虑离散化操作,对于Sora来说,很明显这是不需要的,原因上文有述。单说Causal 3D卷积操作,MAGVIT的这个操作意味着两个事情:
首先,MAGVIG-v2因为会把4帧最后压缩成一帧的Latent表示,所以它不仅在空间维度,同时也在时间维度上对输入进行了压缩,而这可能在输入层面带来进一步的信息损失,这种信息损失对于视频分类来说不是问题,但是对视频生成来说可能无法接受。
其次,4帧压成1帧,这说明起码MAGVIG-v2的Latent编码是包含了“局部Time”信息的,这对于维护生成视频的时间一致性肯定有帮助,但因为仅靠CNN很难融入太长的历史信息,貌似只能融合短期的时间信息,对于维护“长时一致性”帮助很有限,。
综合考虑,我个人觉得Sora采用MAGVIT的概率不大。为了能够生成长达60秒的视频,我们希望在VAE编码阶段,就能把长周期的历史信息融入到VAE编码里来,这肯定是有很大好处的。
问题是:现在公开的研究里,存在这种模型吗?
您别说,还真让我找到一个,就是上图所展示的TECO模型(可参考:Temporally Consistent Transformers for Video Generation)。上图展示了TECO和Sora两位Co-Lead之间的渊源,这是UC Berkeley发的文章,主要研究如何生成“长时间一致性”的视频,而两位Co-Lead都博士毕业于UC Berkeley,也都研究视频生成相关内容,所以他们起码肯定知道这个工作,TECO的主题又比较符合他们把Sora打到60秒长度的技术需求,所以参考TECO的概率还是较大的。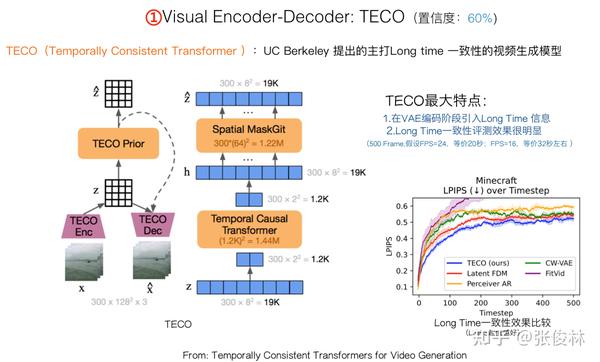
TECO结构如上图所示,核心由两个任务组成:一个是视频重建任务,用来训练视频Encoder-Decoder;一个是使用MaskGit生成离散化的图像Token,主要用于生成视频。TECO有两个主要特点:
首先,它在VAE编码阶段对Space和Time信息分别编码,而且Time编码引入了极长的Long Time信息。确切点说,是所有历史信息,比如要生成第 帧视频,则Time编码会把第
到第
帧的之前所有历史信息都融合到第
帧的时间编码里。很明显这样做对于维护长时一致性是很有帮助的。
其次,TECO在生成视频的长时一致性方面表现确实很不错。上图右下角的效果对比图测试了长达500帧的生成视频,TECO效果比基准模型要好(也请关注下里面的红色曲线模型FDM,后面我们会提到它)。我们可以推断一下,假设视频是电影级流畅度达24帧/秒,那么500帧图像对应正好20秒时长的生成视频。(Sora生成的大部分视频都是长度20秒左右,推断应该也是总长度500帧左右。这是否说明了些什么?)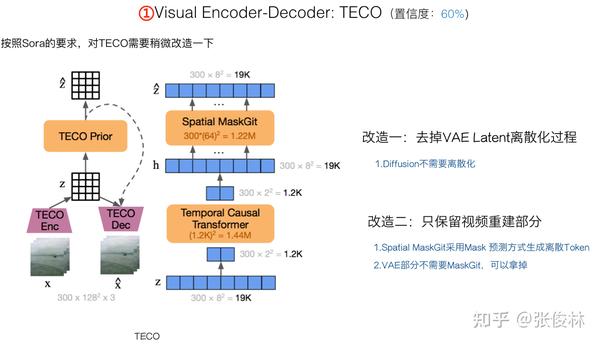
对Sora来说,如果对TECO适应性地改造一下,基本就可以把它能在VAE阶段就融合超长历史的能力吸收进来。具体而言,需要做两项改动:首先,VAE离散化是不必要的,所以可以拿掉;其次,MaskGit部分用于训练模型能够Token by Token地生成视频,我们也不需要,只需要保留视频重建部分即可。
经过上述改造,TECO在VAE Encoder阶段的基本思想就展示在上图中了。首先,是对图片内容的空间Latent编码。首帧单独处理,自己成为一组,这就可以支持“图片和视频联合训练”了;其它帧两帧一组,比如对于第 帧,则把前一帧第
帧也和第
帧放在一组。这里要注意,尽管也是2帧一组,但是这和MAGVIT 思路是不一样的,TECO这个2帧一组类似一个滑动窗口,窗口间是有重叠的,所以不存在多帧压缩成一帧带来的信息损失问题。TECO思路正好和MAGVIT相反,在Space Latent编码阶段不仅考虑第i帧,还把第
帧的信息也带进来,所以它是通过VAE增加更多信息的思路。
视频帧分组后,使用CNN 3D卷积可以产生每帧图片对应的“连续Latent”,这部分是“Space Latent”,主要编码图像的空间信息;之后,使用Causal Temporal Transformer对时间信息进行编码,前面提过,对于同一视频,TECO会把所有历史内容Time信息都融合进来。Transformer输出的时间编码是线性的,经过Reshape后可以形成和“Space Latent”相同大小的高维表示,这部分就是VAE的“Time Latent”。这样,每帧视频经过TECO编码后,有一个“Space Latent”一个“Time Latent”,两者并在一起就是这帧视频的VAE编码结果。这里可以再次看出,TECO的思路是增加信息,而不是以压缩减少信息为唯一目的的。
使用TECO除了能在VAE编码阶段就引入尽可能长的时间信息,更好维护生成视频的一致性外,还有另外一个好处,OpenAI明显是认准了Transformer的Scale潜力比较大,所以Sora在做Diffusion Model的时候把U-Net换成Transformer。如果采用TECO,则Sora的主体结构基本都基于Transformer了,这明显是符合OpenAI的模型口味的。
Spacetime Latent Patch:Spacetime Latent Patch的含义及NaVIT
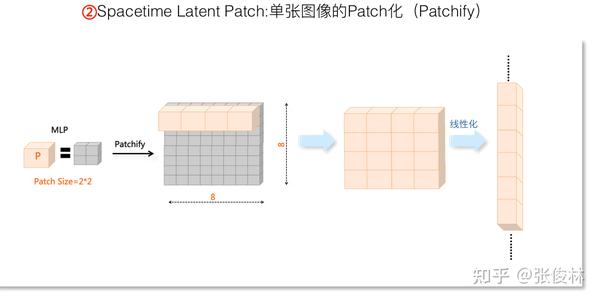
我们先介绍单张图片Patchify的具体含义。本质上,Patchify是对VAE压缩编码的二次压缩,在视频生成模型里很常见。具体做法很简单,如上图所示,对于VAE压缩后的“连续Latent”平面,可以设定一个 大小的Patch,不重叠地扫描“连续Latent”平面,通常是接上一个MLP对
的小正方形网格输入做个变换。这样的话,假设“连续Latent”本来大小是
,经过Patchify操作后,就形成了一个二次压缩的
的Patch矩阵,然后可以通过线性化操作把Patch拉成一条直线,这是因为后面接的是Transformer,它需要线性的输入Patch形式。
目前很多视频生成研究证明了:Patch Size越小,生成的视频质量越高。所以这里Sora采取 大小的Patch Size基本没疑问。Patch Size越小说明压缩率越低,也说明保留的原始图片信息越多。可以进一步推断,这说明了VAE阶段也好、Patchify阶段也好,这种原始信息压缩阶段,应该尽量多保留原始信息,不要压缩太狠,否则对视频生成质量会是负面效果。当然付出的代价是比较消耗计算资源,计算速度会慢很多。目前看很难兼顾,你必须要作出取舍。
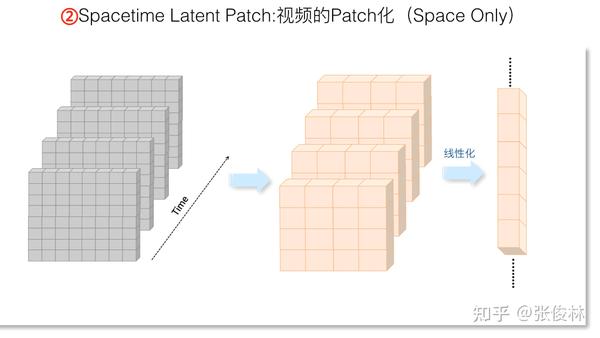
了解单张图片的Patchify操作后,我们来看一个简单的视频Patch方法。因为视频是由多个视频帧按照时间顺序构成的有序序列,一个最简单的方法是不考虑不同帧之间的关系,每一帧独立通过上述的Patchify操作进行二次压缩,如上图所示。
之前很多解读Sora技术的文章倾向于认为Sora在这个阶段采用了类似VIVIT的Tubelet Embedding的思路。含义如上图所示:就是除了第一帧,其它视频帧比如可以2帧为一组,不仅在空间维度进行压缩,在时间维度也要进一步压缩,从时间维度的2帧输入压缩为1帧Patch,具体技术采取CNN 3D 卷积就可以实现。
我觉得在这里采用类VIVIT的时间压缩可能性较小,主要这么操作,在时间维度进一步压缩,输入侧信息损失太高。VIVIT搞的是图像分类任务,属于比较粗粒度的任务,所以压缩狠一点问题不大,但是对于视频生成任务来说,就像上文提到的,看似在输入侧要尽可能保留多一些信息,这么狠的压缩大概会严重影响视频生成质量。目前也有研究(可参考:Latte: Latent Diffusion Transformer for Video Generation)证明,这么做确实有损害作用,所以在这里,类VIVIT方案我觉得可以Pass掉。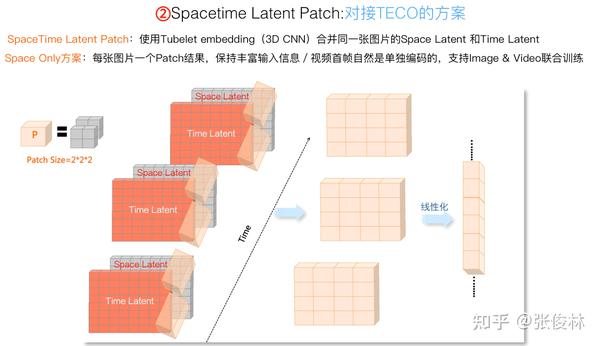
如果假设Sora在VAE阶段采用的是TECO的话,则可以如上图这么做。因为每张图片有两个Patch矩阵,一个是Space Latent,保留的主要是空间信息;一是Time Latent,保留主要是长时历史信息。所以,我们可以用一个 的Patch,把同一个图片的Space Latent和Time Latent合并,压缩为一个Patch矩阵。在这里若把这张图片对应的Patch矩阵叫做“Spacetime Latent Patch”,看着貌似问题不大吧?我猜Sora这么做的概率还是比较大的,也很可能是OpenAI强调的“Spacetime Latent Patch”的来源之处。当然这纯属个人猜测,主观性较强,谨慎参考。
这么做有若干好处。首先,每张图片对应一个Patch矩阵,融合过程中既包含了空间信息,也包含了Long Time时间信息,信息保留非常充分。其次,如果要支持“图片&&视频联合训练”,那么首帧需要独立编码不能分组,这种方案因为没有视频帧分组过程,所以自然就支持“图片&&视频联合训练”。
前文讲过,如果要支持不同分辨率视频,则需要在Patch阶段做些独特的工作。之前大家提及率较高的现有技术是NaVIT,目前看下来,貌似确实也没有比NaVIT(可参考:Patch n’ Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution)更合适的方案了。
上图展示了NaVIT的基本思路:其实很简单,只要我们固定住Patch Size的大小,通过扫描不同分辨率的视频,自然就产生了不同分辨率或长宽比的Patch矩阵,然后把它们线性化即可。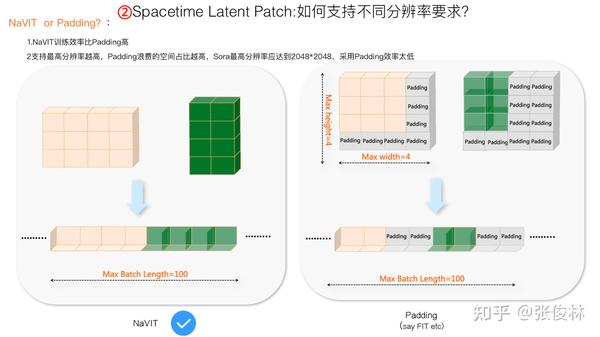
与NaVIT对应的可以支持可变分辨率的方法是Padding方案。如上图右方子图所示,只要设定好一个最大图片大小,其实不管图片长宽比如何,只要让它占据从左上角开始的一个局部位置即可,其它相对最大图片大小空出的位置,用无意义的Padding占位符号占住就行。很明显这个方法也可以支持不同分辨率视频。
那么我们应该选择NaVIT还是Padding呢?很明显应该选择NaVIT方案。NaVIT在提出之初,就是为了改进Padding方法的。Padding方法有什么问题?就是在训练模型的时候,一个Batch里被Padding这种无意义的占位符号浪费的空间太多了,而NaVIT不需要对每张图片进行Padding,该是多少Patch就是多少Patch,顶多在Batch末尾加少量Padding来填充到Batch 最大长度即可。很明显NaViT方案在一个Batch里可以放更多视频帧,而这能极大增加模型的训练效率。
而且,如果模型能支持的最大分辨率越高,Padding方法每张图片Padding浪费的比例就越高,采用NaVIT也就越合算。我们知道,Sora最大可以支持2048*2048的图片,在这种情况下,基本不可能采用Padding方法,貌似也只能用NaVIT了,起码我目前还没有看到更好的方案。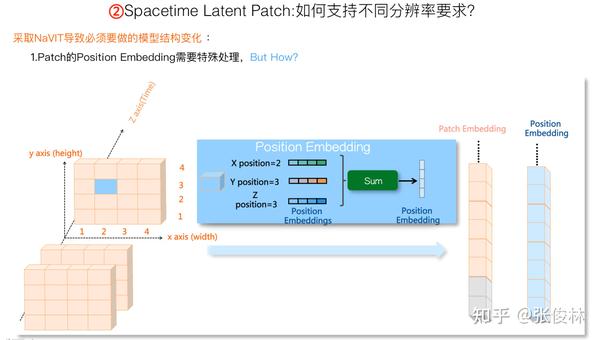
在将Patch拉成线性结构后,会丢失Patch对应的位置信息,所以为了能够支持可变分辨率视频,对于每个Patch,需要特殊设计的位置表征。
很明显使用Patch的绝对位置(就是按照Patch顺序编号)是不行的,只要我们使用三维空间里的相对坐标,并学习对应的Position Embedding,就可以解决这个问题。上图展示了同一个视频的连续三帧,对于蓝色Patch来说,可以看出它对应的相对坐标位置为: ,
以及
(视频时间维度的第三帧)。假设我们在模型训练过程中学习每个坐标位置对应的embedding,然后把三者的embedding叠加,就形成了这个Patch对应的Position Embedding,这里包含了这个Patch对应的三维相对坐标。对于每个Patch来说,除了Patch表达图片内容外,对应的,每个Patch再增加一个位置表征即可。
本部分最后,在Spacetime Latent Patch阶段,让我们归纳下Sora可能采取的技术方案:首先,很可能会对接TECO的VAE编码,使用 大小的Patch来合并每张图片的Space Latent以及Time Latent,每张图片被压成一个Spacetime Latent Patch矩阵。然后使用NaVIT方法来支持可变分辨率视频,最主要的改动是需要根据空间维度的两个坐标和时间轴坐标,来学习每个Patch在空间位置中对应三维空间相对位置坐标的Position Embedding。
Transformer Diffusion Model:从Diffusion Model原理到Video DiTs模型
本部分我们会先介绍下Diffusion Model基本原理,然后逐步推导Video DiTs模型可能的内部结构。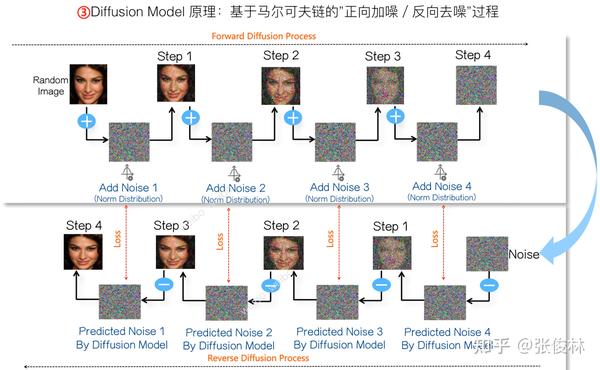
上图展示了Diffusion Model的基本原理,Diffusion Model由正向加噪和反向去噪过程构成。假设我们有一个很大的图片库,可以从中随机选择一张 ,正向过程分多次,每次加入不同程度的符合正态分布的噪音到原始图片里,直到清晰图完全转化为纯噪音图
为止。而反向去噪过程则从转化来的纯噪音图
开始,训练神经网络预测对应步骤加入的噪音是什么,然后从纯噪音图
里减掉预测的噪音,图像清晰程度就增加一些,依次反向逐步一点一点去除噪音,就能恢复出最初的
图片内容。
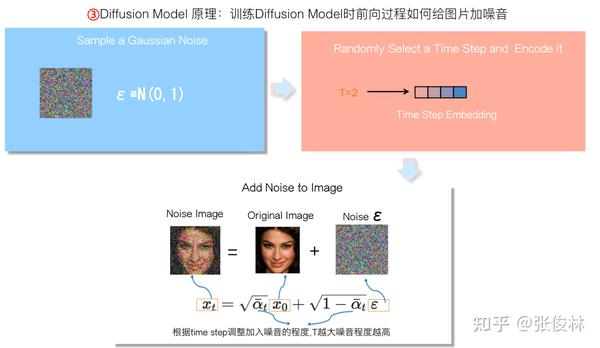
Diffusion Model的前向过程是人为可控地对已知图片逐步加入不同程度噪音的过程,即噪音的逐步“扩散”过程。经数学推导,对于第 个Time Step的加噪音过程可以一步完成,不需要上述的逐渐扩散的过程,如上图所列出公式所示。
给图片加噪音的具体过程如下:首先,我们从图片库中随机选择一张清晰图 ,再随机选择一个满足正态分布的完全噪音图
;然后,随机选择一个Time Step,并对它进行编码;接下来按照上述公式直接在原始图片
基础上融合噪音
来产生混合噪音图
,加入噪音程度系数
与Time Step有关,原则上,Time Step越大,则
越小,原始图片信息融入得越少,噪音程度系数值
则越大,混合后的噪音图
噪音程度越高,也就是说混入更高比例的噪音到原始清晰图
中。这样就一步形成了某个time step下的噪音图。
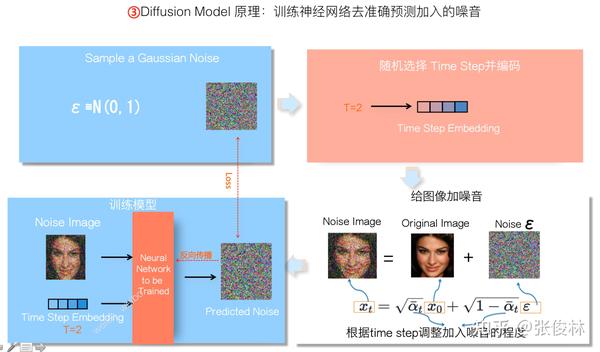
当人为加入可控噪音后,等于制作出了训练数据:<构造出的混合噪音图 ,构造这张混合噪音图时对应的Time Step,被加入的噪音图
>。用这个训练数据,我们可以来训练一个神经网络模型
,输入混合噪音图
以及噪音图对应的Time Step信息,让
根据这两个信息,反向预测到底加入了怎样的噪音
,而前向过程被加入的噪音图
就是标准答案。神经网络
当前预测的噪音图
和标准答案
对比,两者的差异
形成损失(MSE Loss),把预测差异通过反向传播去调整神经网络的参数,使得神经网络能够预测得越来越准。这就是训练Diffusion Model的过程。当然,这里为了方便讲清楚,我做了一定程度的简化。
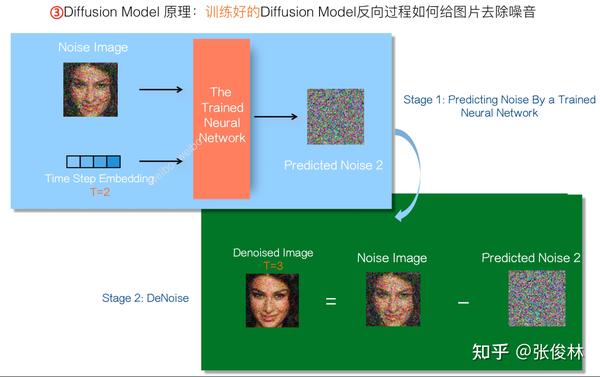
如果经过上述过程训练好Diffusion Model之后,在使用阶段,Diffusion Model的反向过程如上图所示,分为两个阶段。第一个阶段,我们把需要进一步去除噪音的某个混合噪音图 ,以及混合噪音图当前对应的去噪步数(Time Step)信息,输入训好的神经网络
,此时神经网络
会预测出一个噪音图
。第二个阶段,拿到了神经网络预测的噪音图
后,混合噪音图片
减掉预测的噪音图
,就完成了一步去噪音的过程,图像包含的噪音就减少一些,变得更清晰一些。去噪过程仍然需要一步一步逐渐完成,不能像加噪过程那样一步完成。
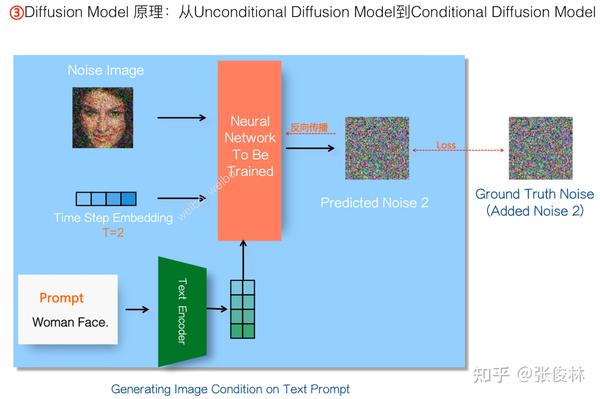
上面介绍的是无条件约束下的图像Diffusion Model运行过程,而像文生图模型比如Stable Diffusion这种模型,是在有文本Prompt约束下进行的,希望模型能生成符合文本描述的图像。如何将无条件的Diffusion Model改造成有条件约束的模型呢?很简单,我们可以使用比如CLIP的文本编码器,把Prompt从文本空间映射到与图像对齐的参数空间内,然后以此作为Diffusion Model模型生成图片的指导条件。类似地,Diffusion Model预测的噪音 会和人为加入的噪音标准
进行对比,以减小两者的差异作为学习目标,来更新Diffusion Model的参数,这样能让神经网络预测噪音越来越准,那么去噪效果也就会越来越好。
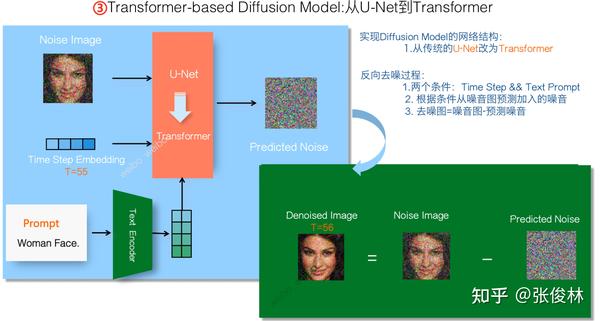
上面是Diffusion Model的基本原理,接下来我们介绍如何推导出Video DiTs视频生成模型的结构。首先要明确的是,基于Transformer的Diffusion Model整个工作流程,就是上面介绍的加噪和去噪过程,无非预测噪音的神经网络结构,从传统做Diffusion Model常用的U-Net网络,换成了Transformer网络结构而已。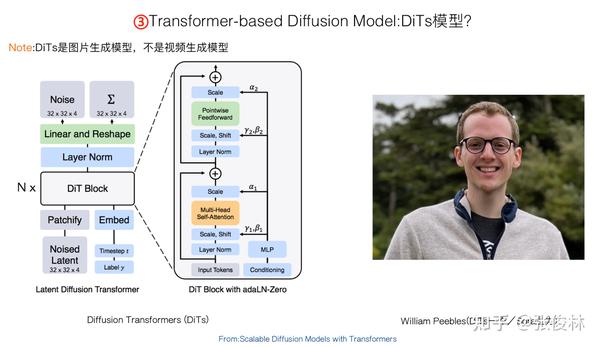
大家都猜测Sora是基于DiTs模型(可参考:Scalable Diffusion Models with Transformers),原因在于William Peebles作为Sora项目的Co-Lead,也是DiTS模型的一做,所以大家推测Sora的Diffusion Model是基于DiTs改的,这个猜测听着还是蛮合理的。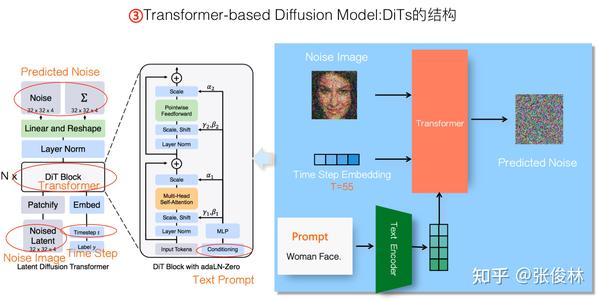
DiTs是基于Transformer的Diffusion Model图像生成模型,看着结构比较复杂,其实整体结构和上文介绍的标准的有条件Transformer Diffusion Model生成模型基本一致,上图在DiTs结构图的对应位置标注出了相应的组件名称,左右两图可以对照着看下。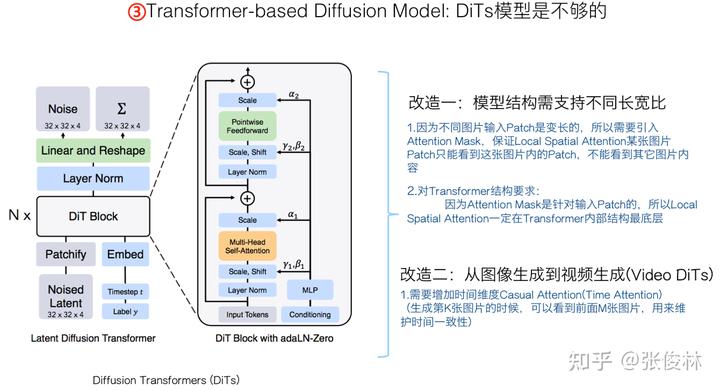
需要注意的是,DiTs是生成图片的模型,直接拿来做视频模型肯定是不行的。我们至少需要在DiTs上做两项改造:首先,需要设计一定的模型结构,用来支持不同长宽比和分辨率的视频;第二,需要把图片生成模型改成视频生成模型。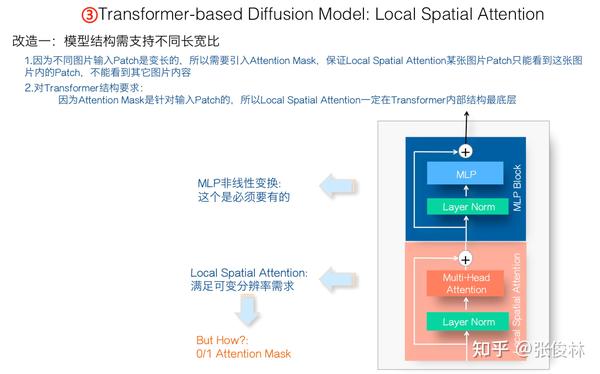
先来看下第一个改造,用来从Transformer模型结构层面支持不同长宽比和分辨率的视频。在Spacetime Latent Patch阶段我们谈到过,经过NaVIT改造,不同图片或视频帧的输入Patch是变长的,所以在Transformer阶段,我们需要引入Attention Mask机制,保证Transformer在做Local Spatial Attention的时候,属于某张图片的Patch只能相互之间看到自己这张图片内的其它Patch,但不能看到其它图片的内容。另外,因为这个引入的Attention Mask是针对输入Patch的,所以Transformer内的这个Local Spatial Attention模块一定在Transformer内部结构的最底层。
经过上述推导,我们可得出如上图所示的Transformer内部结构,它目前由两个子模块构成:最底层是Local Spatial Attention模块,主要计算图片或视频帧的空间信息,也就是对同一个视频帧内的各个Patch关系进行建模。在它之上,有一个标准的MLP 模块,这个是Transformer模块做非线性映射所必需的。
现在的问题是:如果每个视频帧的Patch数是固定的,那么这个Local Spatial Attention模块就很容易设计,但是我们面对的是变长Patch,具体采取什么技术手段才能实现针对变长Patch的Local Spatial Attention呢?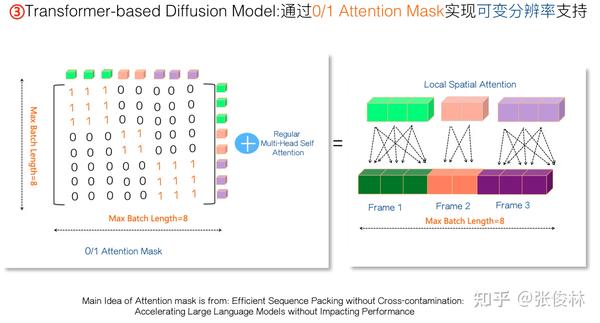
这里给出一个可能的解决方法,主要思路来自于文献“Efficient Sequence Packing without Cross-contamination: Accelerating Large Language Models without Impacting Performance”。我们可采用“0/1 Attention Mask矩阵”来达成目标,从上图可看出思路也很简洁:如果我们假设Batch内序列最大长度是8,就可以设置一个 的0/1 Attention Mask,只有对角线正方形子Block位置全是1,其它地方都设置成0。左图中标为绿色的某帧三个Patch,如果看矩阵前三行,易看出,针对其它帧的Attention Mask由于都是0,所以加上Mask后就看不到其它图片,而对于它对应的
都是1的Attention Mask,又可以保证三个Patch相互都能看到。其它图片也是类似的道理。通过设置Attention Mask,就可以很方便地支持NaVIT导致的每帧不同分辨率和长宽比的问题。
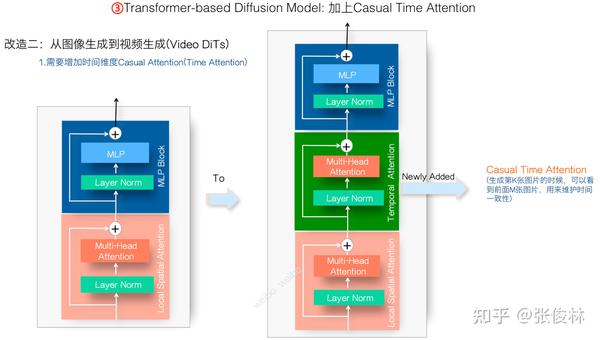
接下来进行第二项改造,从DiTs到Video DiTs,也就是让DiTs能够支持视频生成。这步改进比较简单,因为大多数视频生成模型都有这个模块,就是在我们上一步改造的Transformer结构里,加入一个Casual Time Attention子模块。Causal Time Attention模块的作用是在生成第i帧的时候,收集历史Time信息,也就是通过Attention让第i帧看到之前的比如k帧内容,这是用来维护生成视频的时间一致性的,做视频生成肯定需要它。至于它的位置,因为Local Spatial Attention必然在Transformer内部最下方,所以Causal Time Attention放在之前引入的两个子模块中间,这是个合理选择。
Local Spatial Attention和Causal Time Attention的具体含义,如果按照时间序列展开,则如上图所示,比较简单不解释了。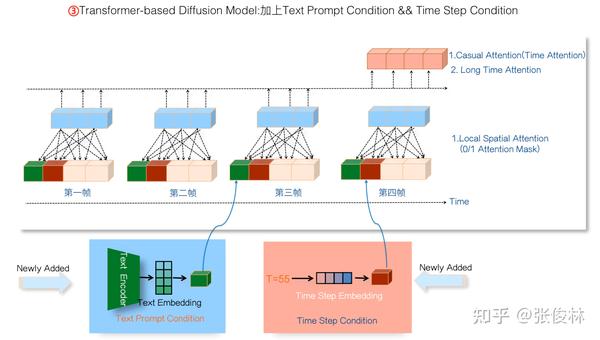
前面在讲Diffusion Model原理的时候提过,利用Diffusion Model来做文本生成视频,还需要两个条件变量:Prompt文本信息,以及Time Step信息。如果把这两个条件引入,一种设计方案是把两个条件信息压缩后,并排放入每一帧的输入信息里;另外一种思路是可以在Transformer目前的3个子模块里再引入一个Condition Attention Block,把输入条件接入这个模块,通过Attention模式工作。目前已有研究(可参考:VDT: General-purpose Video Diffusion Transformers via Mask Modeling)证明,尽管第一种把条件变量塞到输入部分的做法很简单,但是效果是很好的,训练起来模型收敛速度也较快。基于此,我这里就选择了这种简洁的方案,思路如上图所示。
如果归纳下Video DiTs的整个逻辑,就如上图所示。把噪音Patch线性化后,并入Prompt和Time Step条件,一起作为Transformer的输入。Transformer内部由三个子模块构成:Local Spatial Attention模块负责收集视频帧空间信息;Causal Time Attention模块负责收集历史时间信息;MLP模块负责对时间和空间信息通过非线性进行融合。叠加比如 个这种Transformer模块,就可以预测当前Time Step加入的噪音,实现一步去噪音操作。对于Diffusion Model的逆向去噪过程,Time Step可能需要如此反复迭代20到50次去噪过程,才能形成清晰的视频帧。这也是为何Sora比较慢的原因之一。
Sora的Long Time Consistency可能策略:暴力美学还是FDM?
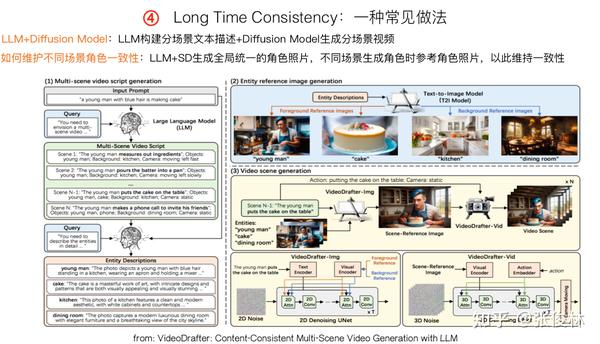
如何维护生成长视频的内容一致性也是一个研究方向,目前一种比较常见的策略是“LLM+Diffusion Model”集成策略,如上图所示的流程。其基本思想是:可以把长视频分成多个分镜场景,对于用户输入的Prompt,可以用比如GPT-4这种LLM模型自动生成多场景各自的拓展Prompt描述,然后用视频生成模型生成对应的分场景视频,就是“分场景拼接”的模式。
但这里有个问题,比如主角可能在各个分场景都会出现,如果不做一些特殊的维护角色一致性处理的话,可能会出现主角形象老在不断变化的问题,也就是角色不一致的问题。上面这个工作VideoDrafter(可参考:VideoDrafter: Content-Consistent Multi-Scene Video Generation with LLM)是这么处理的:它让LLM产生一个角色的形象描述文字,然后使用比如Stable Diffusion文生图模型,根据形象描述文字,生成全局固定的角色外观图片。在每个分场景内,都依托这个唯一的角色外观图片来生成视频,这样可以解决不同分场景的角色一致性问题。
Sora会采取这种策略吗?我猜可能性不太大,对于很通用的Prompt描述,明确确定主角或特定角色其实是不太容易的,这种明确角色、产生全局固定形象的思路,感觉比较适合特定领域的视频生成。
这里提一种粗暴野蛮但简单的可能做法,如上图所示。就是说,在生成第i帧视频的时候,把Time Attention拉长,让第i帧看到前面从第1帧到第 帧所有的历史内容,这类似TECO在做VAE时集成Time信息的做法。这种做法看到的历史比较长,所以可能在维护一致性方面有好处,但明显对算力要求很高。
Sora有可能这么做吗?并不能排除这种可能性,证据来自于上图中Sora技术报告的截图,红圈标出的文字意思是Sora为了维持长时一致性,会一次看之前的很多帧。
在Transformer Diffusion Model阶段维护“长时一致性”策略方面,感觉FDM(Flexible Diffusion Modeling)方法是种简洁有效的思路。FDM(可参考:Flexible Diffusion Modeling of Long Videos)提出了两种Time Attention改进模型,在维护长时一致性方面效果不错。之前我们提到TECO的评测,右下角的评测图里,除了TECO那条蓝色线,紧接着的红色线就是FDM在500帧视频生成的效果。而且很明显,FDM这种Time Attention和TECO这种VAE编码,两者都出于维护生成视频一致性的目的,而在模型中所处的位置不同,所以两者是有互补性的。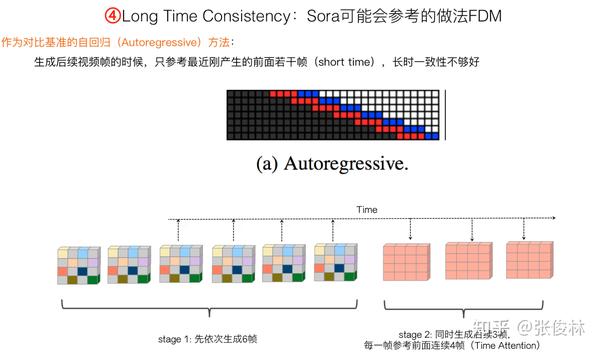
下面介绍下FDM的两种Time Attention的思路,在介绍之前,先说明下基准方法,也就是“自回归方法“(Autoregressive)。如图所示,“自回归”思路很直接,先依次生成若干比如6帧视频帧,然后一次生成后续3帧,在生成这3帧的时候,Time Attention会看到之前的最近若干帧,比如4帧。也就是说,“自回归”在生成后续视频帧的时候,会参考之前最近的若干帧。容易看出,这是一种“短时”Attention,而非“长时”Attention。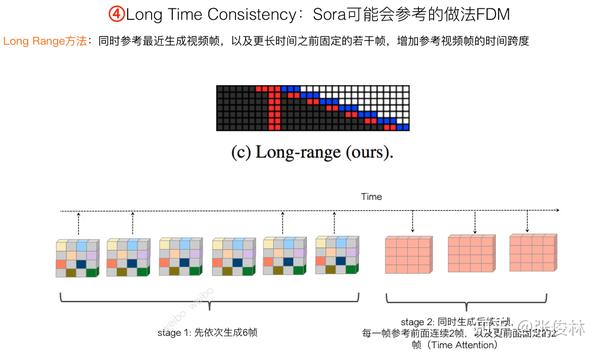
“Long Range”是FDM提出的第一种“长时一致性”模型,思路如图所示。想法很直观:在生成第i帧视频的时候,不仅仅参考最近的几帧,也会在较远历史里固定住若干帧作为参考。可以看出,“Long Range”既参考短时历史,也参考长时历史,不过长时历史位置是随机选的,也是固定的。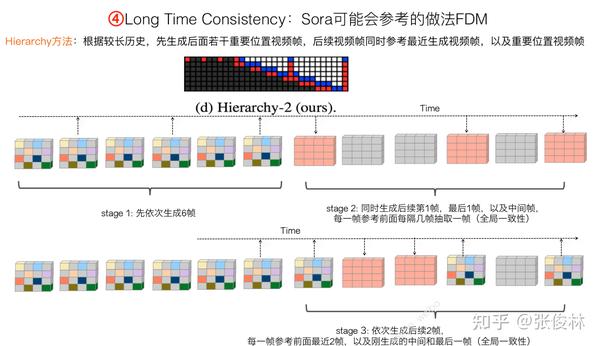
“Hierarchy方法”是FDM提出的第二种长时Attention策略。它首先从较长历史里间隔采样,获得之前历史的大致轮廓,在全局历史视频帧引导下,先产生后面若干关键位置的视频帧,比如第一帧、最后一帧以及中间帧。这意思是根据全局的历史,来生成全局的未来。之后按顺序生成后续帧,在生成后续帧的时候,不仅参考最近的历史,同时也参考第一步生成的未来关键位置视频帧。所以这是一种先谋划全局,再斟酌现在的“长远与近期相结合”的层级化的Time Attention。
我无法确定Sora是否会用类似FDM的思路,但是觉得这是维护长时一致性较为可取的一种方法。
Sora的训练过程与技巧:合成数据、两阶段训练及双向生成
需要再次强调下:所有文生视频模型,本质上都是有监督学习,是需要大量高质量标注好的<文本,视频>成对数据来训练的,它们不是类似LLM的那种自监督学习那样,无需标注数据。
尽管有些开源的带标注视频数据,但是无论数据量还是质量,想要作出类似Sora这么高质量的视频生成模型,基本上是没可能的。所以,如果想要复现Sora,如何自动化地做出大量高质量标注视频数据可能才是最关键,也是最难的一步。(当然,我们可以借鉴LLM蒸馏GPT4的历史经验,估计这些GPT-4V视频标注蒸馏方案,很快就会出现)
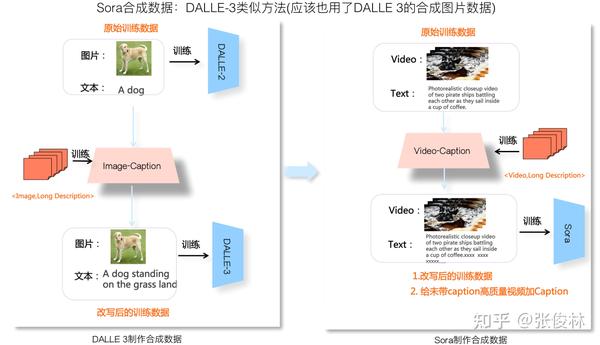
我觉得,Sora之所以效果这么好,在制作带标注视频合成数据方面的贡献很可能是最大的。Sora采用了类似DALLE 3的方法来制作视频合成数据。上图左侧展示了DALLE 3制作<文本,图片>合成数据的流程。图片标注数据网上资源有很多,比如5B的LAION数据,但是标注质量有些问题,一方面是太粗略太短没有细节描述,一方面里面有些是错误的。
鉴于此,DALLE 3通过人工标注(或者人加GPT相结合?)一些<详细文本描述,图片>数据,用这个数据来训练一个Image-Caption Model(ICM),就是说ICM接受图片输入,学习根据图片内容,自动产生图片的详细描述。有了ICM模型,DALLE 3用它生成的长文本描述,替换掉原先图文标注数据里的短文本描述,就制作出了大批量的高质量合成数据,这对DALLE 3质量提升帮助很大。
Sora的视频合成数据制作过程应该是类似的(参考上图右侧)。通过人工标注(或人+GPT)一批高质量的<视频,长文本描述>数据,可以训练一个Video-Caption Model。 VCM模型训练好后,可以接受视频,输出详细的文本描述。之后,可以用VCM产生的视频长描述替换掉标注视频数据里的简短文本描述,就产生了高质量的视频合成数据。
其实思路可以再打开,既然我们有了VCM,也可以给没有标注的视频自动打上长文本描述,没问题吧?这样的话,可以挑那些高质量视频,用VCM打上详细文本描述,这就制作出了大量的、非常高质量的视频标注数据。
另外,既然Sora是图片和视频联合训练,那么很显然,训练DALLE 3的那批图文合成数据,那肯定在训练Sora的时候也用了。
Sora在训练的时候应该采取了两阶段训练过程,下面简述其做法。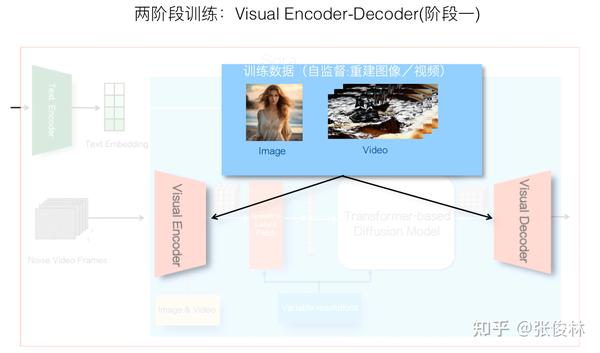
一般VAE是独立训练的,收集大量的图片或视频数据后,通过图片或视频重建的训练目标,可以得到对应的“视觉编码器-解码器”。此部分训练是自监督学习,不需要标注数据。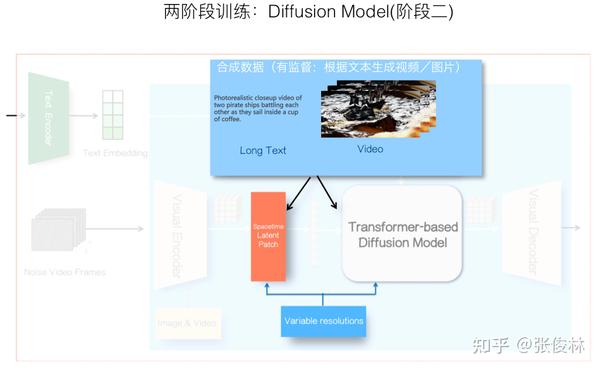
第二阶段是包括Diffusion Model在内整个模型的训练,这一阶段训练过程中,一般前一阶段训练好的Encoder-Decoder会冻结模型参数,不随着这步骤的训练数据发生变动,包括Text Encoder也是利用现成的比如CLIP,也会类似地冻结住模型参数。所以这部分训练主要涉及Spacetime Latent Patch对应的Position Embedding,以及预测噪音的基于Transformer的Diffusion Model的训练。
另外,Sora还支持多种方式的视频生成,比如输入一张静态图生成完整视频、生成无限循环视频、输入结尾几帧图片倒着生成完整视频、给定两段视频内容生成新内容将两者平滑地连接起来等。
可以推断,在Sora的训练过程中,采用了在输入侧中间位置加入已知图片,然后同时按照时间维度的正向生成视频和反向生成视频的双向生成策略。一方面,引入这种双向生成策略,可以方便地支持上面讲的各种灵活的视频生成类型;另外一方面,其实如果采取从中间向时间维度两边拓展的生成模式,更有利于维护生成内容的连贯性和一致性。因为中间位置向两边拓展,只需要维护一半时间窗口的内容一致性即可,两边向中间内容靠拢,这看上去是双向生成策略带来的额外好处。
比如,之前提到的输入一张图片生成完整视频,从视频内容可知,这个例子是把输入图片放在了输入噪音图片序列的最后一帧,然后按照时间顺序倒着生成的。再比如,生成无限循环视频,可以把某一帧视频图片,分别插入在中间位置和头尾位置,然后从中间位置分别向两边生成,这样就会产生一个看上去总在无限循环的视频内容。
可见,若能方便地在指定输入位置插入图片,即可方便地支持双向训练或灵活的视频生成方式。那么,如何达成这一点呢?可以采用掩码策略(思路可参考:VDT: General-purpose Video Diffusion Transformers via Mask Modeling),如上图所示。图右侧 是
掩码矩阵,对应矩阵取值要么都是1要么都是0,而
是引入的掩码帧序列,可以把已知图片插入到指定位置,并把它对应的掩码矩阵设置为1,其它掩码帧可以是随机噪音,对应掩码矩阵设置为0。
和
经过Bit级矩阵乘法,获得掩码运算结果,对应0掩码矩阵内容都被清零,而对应1的掩码矩阵的内容仍然保留,这样形成掩码帧。
相应地,对Diffusion Model的输入噪音序列 来说,设置一个反向掩码矩阵序列
,其
矩阵取值和对应的掩码帧
矩阵M正好相反,同样地,(
和
进行掩码运算后,要插入图片位置的输入帧数据被清零,其它噪音帧内容保持不变。
接下来只要将噪音输入帧和对应的掩码帧进行矩阵加法运算,这样就把已指图片插入到Diffusion Model的指定位置了。
Sora能作为物理世界模拟器吗
OpenAI宣称Sora是物理世界模拟器,这个问题的答案非常主观,每个人都有不同的看法。我觉得以目前的技术条件来说,单靠Sora本身很难构造世界模拟器,更愿意把OpenAI这么讲看成是他们对Sora寄托的愿景,而非已经成立的事实。对此更详尽的个人思考可见:https://zhuanlan.zhihu.com/p/684089478
来源:知乎 www.zhihu.com
作者:张俊林
【知乎日报】千万用户的选择,做朋友圈里的新鲜事分享大牛。
点击下载