




























“书生・浦语”2.0大语言模型开源 200K上下文
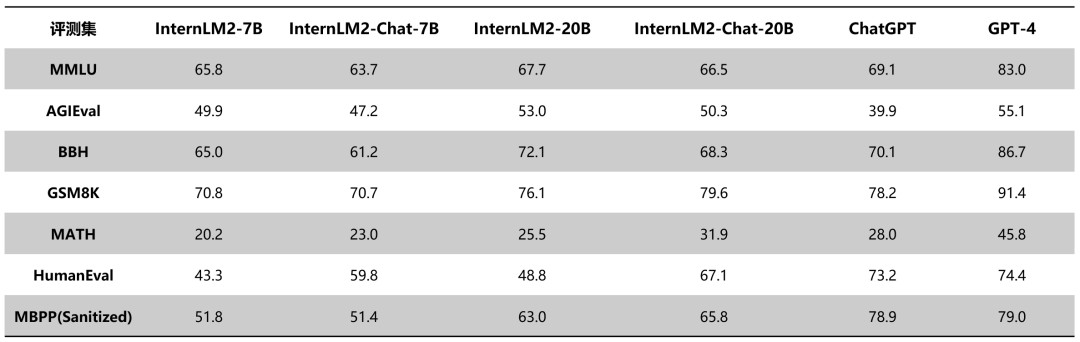
IT之家今日(1月17日)消息,商汤科技与上海 AI 实验室联合香港中文大学和复旦大学今日发布了新一代大语言模型书生・浦语 2.0(InternLM2)。 据介绍,InternLM2 是在 2.6 万亿 token 的语料上训练得到的。沿袭第一代书生・浦语(InternLM)设定,InternLM2 包含 7B 及 20B 两种参数规格及基座、对话等版本,继续开源,提供免费商用授权。 目前,浦语背后的数据清洗过滤技术已经历三轮迭代升级,号称仅使用约 60% 的训练数据即可达到使用第二代数据训练 1T tokens 的性能表现。 与第一代InternLM相比,InternLM2在大规模高质量的验证语料上的Loss分布整体左移,表明其语言建模能力增强。 通过拓展训练窗口大小和位置编码改进,InternLM2支持20万tokens的上下文,能够一次性接受并处理约30万汉字(约五六百页的文档)的输入内容。 下面表格对比了InternLM2各版本与ChatGPT(GPT-3.5)以及GPT-4在典型评测集上的表现。可以看到,InternLM2在20B参数的中等规模上,整体表现接近ChatGPT。

IT之家今日(1月17日)消息,商汤科技与上海 AI 实验室联合香港中文大学和复旦大学今日发布了新一代大语言模型书生・浦语 2.0(InternLM2)。
据介绍,InternLM2 是在 2.6 万亿 token 的语料上训练得到的。沿袭第一代书生・浦语(InternLM)设定,InternLM2 包含 7B 及 20B 两种参数规格及基座、对话等版本,继续开源,提供免费商用授权。
目前,浦语背后的数据清洗过滤技术已经历三轮迭代升级,号称仅使用约 60% 的训练数据即可达到使用第二代数据训练 1T tokens 的性能表现。
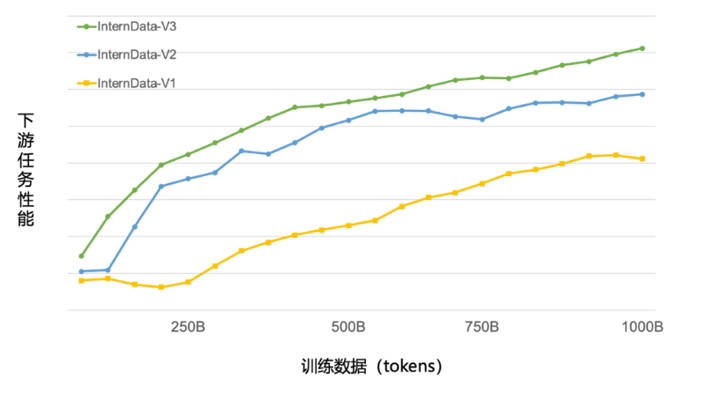
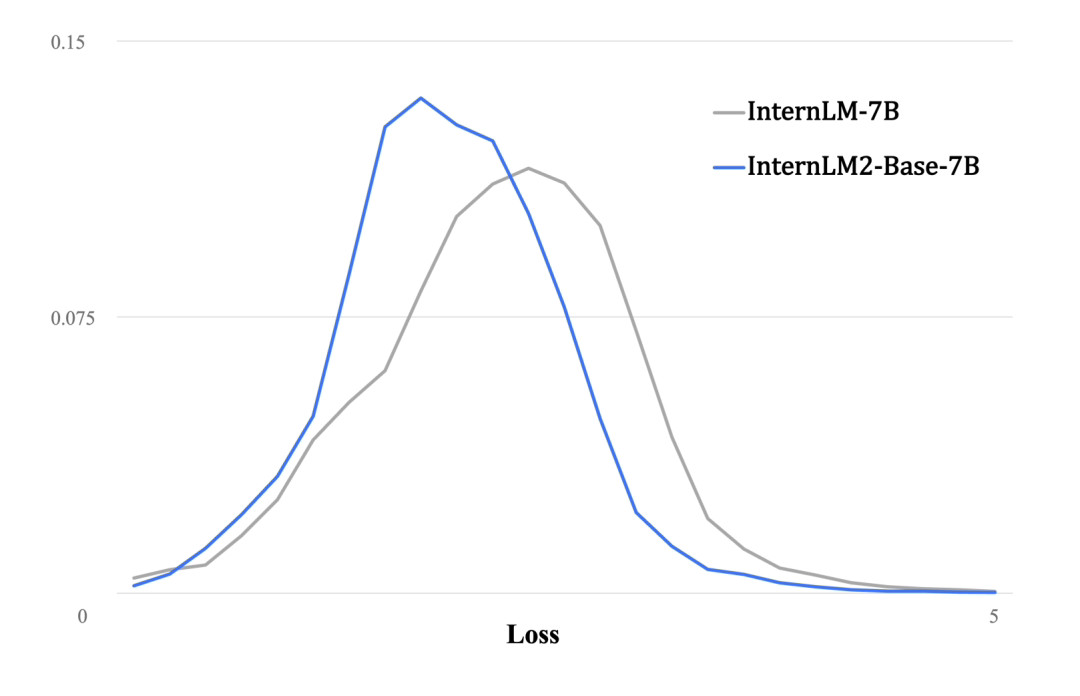
与第一代InternLM相比,InternLM2在大规模高质量的验证语料上的Loss分布整体左移,表明其语言建模能力增强。
通过拓展训练窗口大小和位置编码改进,InternLM2支持20万tokens的上下文,能够一次性接受并处理约30万汉字(约五六百页的文档)的输入内容。
下面表格对比了InternLM2各版本与ChatGPT(GPT-3.5)以及GPT-4在典型评测集上的表现。可以看到,InternLM2在20B参数的中等规模上,整体表现接近ChatGPT。