








![【XGAMER 元代碼 - 主題曲: 寂聲 (日本語)】 日語歌詞: Verse 1 目を閉じたいだけ 気にしていないふうに... 内の信念は 正しくない 風と海[真実を]告げて 失くしない 幻がなくて Chorus: 徹夜で戦った 日差し...](https://scontent.fdsa2-1.fna.fbcdn.net/v/t15.5256-10/336656091_162215126698640_3843734250325810940_n.jpg?stp=dst-jpg_p600x600&_nc_cat=102&ccb=1-7&_nc_sid=08861d&_nc_ohc=kQATFNXRo-kAX9EeaEw&_nc_ht=scontent.fdsa2-1.fna&oh=00_AfCnUOW2Bv6j_cgJTtG7RU2CcjvsthXu1Pj6XjGBE5943w&oe=641C69A7#)




































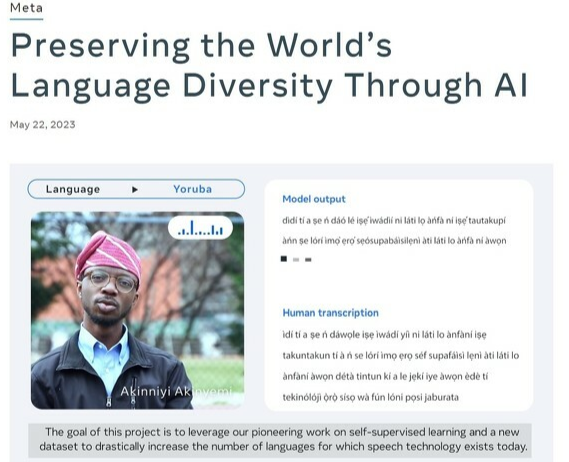
Meta宣布开源大规模语言模型MMS 对应4000+音声语言识别
虽然在元宇宙事业中栽了大跟头,不过Meta公司的大厂风范依然丝毫不落下风,美国当地时间5月22日,Meta宣布开源大规模语言模型“Massively Multilingual Speech(MMS)”,对应多达4000种以上音声语言的识别。 ·据悉,Meta公司的大规模语言模型“Massively Multilingual Speech(MMS)”的数据库使用了可以用于自学的模型wav2vec 2.0数据模块,内涵多达4000种以上的音声语言模本,是现有技术的40倍能力。 ·MMS还可以灵活运用在被翻译成多国语言的世界最流行通用书籍《圣经》上,通过该系统,可以制作出多达1100种语言的各版本《圣经》数字版,而每部圣经的朗读时间平均约为32个小时。

虽然在元宇宙事业中栽了大跟头,不过Meta公司的大厂风范依然丝毫不落下风,美国当地时间5月22日,Meta宣布开源大规模语言模型“Massively Multilingual Speech(MMS)”,对应多达4000种以上音声语言的识别。
·据悉,Meta公司的大规模语言模型“Massively Multilingual Speech(MMS)”的数据库使用了可以用于自学的模型wav2vec 2.0数据模块,内涵多达4000种以上的音声语言模本,是现有技术的40倍能力。
·MMS还可以灵活运用在被翻译成多国语言的世界最流行通用书籍《圣经》上,通过该系统,可以制作出多达1100种语言的各版本《圣经》数字版,而每部圣经的朗读时间平均约为32个小时。







李芷晴
https://tszching.uk