








![【XGAMER 元代碼 - 主題曲: 寂聲 (日本語)】 日語歌詞: Verse 1 目を閉じたいだけ 気にしていないふうに... 内の信念は 正しくない 風と海[真実を]告げて 失くしない 幻がなくて Chorus: 徹夜で戦った 日差し...](https://scontent.fdsa2-1.fna.fbcdn.net/v/t15.5256-10/336656091_162215126698640_3843734250325810940_n.jpg?stp=dst-jpg_p600x600&_nc_cat=102&ccb=1-7&_nc_sid=08861d&_nc_ohc=kQATFNXRo-kAX9EeaEw&_nc_ht=scontent.fdsa2-1.fna&oh=00_AfCnUOW2Bv6j_cgJTtG7RU2CcjvsthXu1Pj6XjGBE5943w&oe=641C69A7#)





































大模型高效训练的关键技术|AI 盐沙龙
感谢 @知乎科技 邀请参加 AI 盐沙龙活动,下面是我讲述《大模型高效训练的关键技术》的现场实录。大家下午好,荣幸参加贵乎的活动。我今天讲一下大模型训练的技术,我们做了一套大模型训练的工具,我觉得更偏下层一点,当然没有杨军老师那样更下层,介于编译器和大模型之间的那一层。首先给大家展示一张图片,横坐标是时间,纵坐标是AI模型的参数量。从这张图片中可以看出,过去六年大模型的参数量上升了大概10万倍量级。因为2016年的时候,我们很清楚最好的大模型是ResNet50,只有2000多万的参数,到了2020年6月份GPT3出来了,当时是2000亿的参数,已经大了一万倍了,现在据说GPT4是MOE1.7万亿参数,又进一步增加了10倍。我们知道从ResNet50到GPT4,可能不是深度学习了,是宽度学习更恰当一点。当然这是大模型的现状,它好的一点确实GPT4现在变得非常智能,但是不好的一点,我们也可以看一下互联网上数据,训练一下GPT4这个模型预算是6300万美元,这是OpenAI 的数据,站在学校的角度而言是很难做到的,需要工业界和学术界结合起来是比较现实的方案。这张图中还有一条线就是GPU的内存容量,可以看出每18个月上升1.7倍,上升速度没有英伟达的股价上升速度快,这也是一个现状。这也是为什么需要用成百上千的GPU训练大模型的根本原因。这里列举了一些数字,现在已经更夸张了,之前训练GPT3的时候,我们用了V100,300万美金的价格,现在GPT4居然到了6000万美金的量级,整个成本变成了亟待解决和优化的问题了。我介绍一下我个人做的事情,以及我做创业公司到底在干吗。一句话讲就是希望把大模型训练的成本能进一步降低,今年训练GPT3训练成本是300万美金,希望五年之后到七八万美金左右。我们设计了一个软件叫ColossaI,第一是异构的内存管理系统,大模型最大的挑战是内存开销太大了,假定我们是2000亿参数的话,即便用单精度存,2000亿就是800G内存,梯度也是800G内存,我们训练大模型都是800G内存,首先什么也没干已经需要3T的内存了,单个GPU只有80G或者100G。当然我们知道要存很多中间计算结果,包括输入数据越大的情况下,我们用传统的方式也是随着数据而增大的,内存变成了天文数字,所以优化内存是非常关键的地方。我们独创的高效N维并行工作。李开复老师做了一家公司叫零一万物,因为OpenAI说自己用了10万张卡训练,他们的目标也是希望到那个量级,但是他们现在只用了200张卡。他们考虑的重要事情就是把200卡扩展到2万卡,能不能获得90倍的加速,或者能不能获得80倍的加速?因为现在用传统的方案去做的话,可能我从200卡到2万卡,虽然GPU速度增加了,但是效率只有20%、30%,从决策者的角度来看非常不值,我投资了这么多倍,只有30%的速度提升,我认为未来并行计算,分布式计算的空间优化还是很大的。由于是跨GPU和跨数据的优化,我们也在这层做了一些优化。另外低延迟的推理系统。很荣幸智源悟道是我们公司第一个付费客户,两年前我们就是帮它优化GLM,因为模型越大之后,我们现在用GPT3或者GPT4,问一句话延迟还是很高的,低延迟的推理系统也是很重要的。这是目前ColossaI做的一些事情。这里列举了一些实验的比较,主要跟最基础的基准比较,可以看出ColossaI可以快6到7倍,效率能是8倍大小的参数。这里是ColossaI目前的社区发展情况,它的开源目前增长速度还是非常快的,已经超过了kafka、spark这些传统的软件,横坐标是时间,纵坐标是星数。这是同赛道的软件比较,比如跟英伟达的Megatron-LM 和跟DeepSpeed相比。ColossaI目前做的很多事情也是跟全球AI生态彻底绑定,全球的生态还是一体的,我觉得还是有很多相互交流的。目前这是生态的网页,可以看出现在第一个软件就是ColossaI,LightingAI全部用的ColossaI。我们知道目前第二大AI生态是HuggingFace。开源生态全球做的最好的就脸书,脸书OPT的模型也可以用ColossaI训练,这是跟全球AI生态的关系。我们也跟一些厂商,比如HPE合作,因为它们在全球有很多最终为大模型买服务器的企业,比如车厂、药厂、石油公司,现在也内嵌了ColossaI的方案,这是它的产品官对ColossaI的点评,有很好的API,有显著的性能提升。这是目前ColossaI的贡献者,也是遍布全球的。这是全球的ColossaI的用户,可以看出中国、美国、欧洲、东南亚都有很多的客户。我就简单介绍一下干的事情。这里进入技术环节,主要是我们现在考虑假如训练一个千亿、万亿的大模型到底需要什么技术。这里简单探讨一下,大家有什么想法和看法可以随时交流。、我们知道2020年GPT3刚出来的时候,最开始把训练方案公布出来的是英伟达,在英伟达PTC峰会上,黄总说了如何训练GPT3的,当时用了3072个GPU,用了三种模型,数据并行,流水线并行以及张量并行,出于通讯方面的考虑,张量并行到流水线并行需要做很多的考虑,需要涉及每一个GPU都要参与。英伟达的方案是首先在服务器内用张量并行,每个服务器有8个GPU,再把64个服务器分成一组做流水线并行,组之间用数据并行,这样是3072。现在我们明显看到一个趋势,就是刚才说的趋势,模型从ResNet50到GPT3大了一万倍,但是层数并没有增加,每层计算量变得更大的情况,张量并行可能发挥更大的作用。大家可以看一下脸书团队的一些方案,他们现在的一些方案其实直接把流水线并行删除了,他们发现当这个模型很宽的时候,张量并行的优化点还是很多的。当然我们也顺应潮流,也做了一些更高维度的张量并行,比如二维张量并行,2.5维张量并行。还有数据序列并行,大家看到新闻美国某些创业公司把输入长度扩展到100万个Token,肯定输入长度依旧是越长越好,我们回顾之前背景肯定是信息越多越好,但是序列非常长之后内存开销很大,所有词词两两之间都要算attention,所以我觉得数据序列并行也非常重要。我简单介绍一下这些技术,首先回顾一下数据并行,最基本的训练AI大模型的方式。假如说batch能塞到GPU内存里面最好,这样服务器之间只需要梯度加过去就行了,这是最简单的方式。这种方式主要取决于我们能把通信操作优化得多好,假定能够优化好的话,下面就是如何把batch做大,因为每次循环都得进行一些梯度更新,我们如果能把batch扩大十倍,就线性减少它的更新次数,同时也会让每个GPU占用率、使用效率更高。但是问题是我把batch 扩大无限大,更新次数无限小的时候,我们会是找一些局部自由点,这种情况下发现更难找出更好的局部自由点了,这里做一些数值优化的工作比较重要。最近斯坦福的马腾宇老师也提了一个更高级的想法,这块未来的想法可能还有很多。不知道大家有没有听过美国有一家创业公司是做芯片的,理念是我把内存容量做到2T,A100的只有80G内存,但是它自己的宣传稿中,我没有验证,它说可以把内存做到2T,这种情况下有望把千亿参数直接塞到内存里。数据并行之前已经优化的很好了,进一步如何再把batch size 提升,把更新次数降低。说完数据并行,再说一下Model Parallelism。我做神经网络训练像盖楼一样,我算完第一层才能算第二层,算完第二层才能算第三层。我们现在既然楼很宽,假定这个楼有1万平,我有十个工程队,每个工程队分了1000平,大家干完之后做一次全局的同步,然后全局通信就进入下一层。真的挺简单的。但是它的通信开销还是非常大,英伟达Megatron方案还是做了精心的设计。未来有必要做一些二维张量并行,因为本身都是矩阵,像传统的二维矩阵层的核心思想,就是我把GPU或者服务器按行或者按列分成网格状,每个机器只用跟同列机器打交道,本来有一万个机器,理论上跟9999个机器打交道,但是二维的方式每次只需要跟99个机器打交道就可以了,可以大幅降低通信的代价。这是二维张量并行的核心思想。三维的也是分成10×10×10的网格状,或者分成100×100×100的立体状,每次只需要跟同维度的打交道就可以了。这是二维和三维的核心思想。2.5维是介于二维和三维之间的中间状态。这里快速过一下通信复杂度,大家也没必要记得太认真,这种东西肯定是一些理论上的分析,具体还要实践验证。最后两列可以看出二维和三维的通信复杂度肯定是远低于一维的。我重点介绍一下数据序列并行。这里首先跟大家展示一张图,横坐标是到底有多长,纵坐标是预测下一个词的精度,肯定越长预测的越准确。回顾的越多信息越多,预测的肯定越准确。这是一些实验的结果图。我给大家看一张图,超过4K之后,它的内存开销在指数级的上升。现在有一个创始公司居然把sequence 做到了100万,它的核心思想就是把不同的Token块放到不同的GPU上,我有一百万个Token,可否十个GPU每个放10万个Token,这样每个计算单元的内存压力小很多。但是它的问题是 attention 架构里 token两两之间都需要做信息交换的,比如说今天咱们屋子有100个人,每个人都拿了一包很大的零食,现在要干的事情就是让所有的人尝下手里的零食,所有人之间都需要交互一下。优化点就是能不能基于传统的Allerduce的方法,我们拉一个圈,右手边的同学尝试一下,然后左手边的同学尝一下,传99次就所有人都可以吃到所有人的零食了。我再介绍一下内存优化方面的工作。既然训练大模型这么耗内存,现在很重要的问题是我们能否利用一下CPU内存。假如盖大楼需要很多材料,材料和原料都放到楼下工地,楼下工地放不下能不能放到隔壁工厂?隔壁工厂也放不下能否放到天津?但是如果我每拿一次都去隔壁工厂,肯定消耗更大,我盖一层楼都去天津拿一下,显然盖楼的时间还没有拿材料的时间长。我用CPU内存就是通信开销太大了,计算的速度肯定远快于CPU跟GPU之间的通信。这个其实就是优化的重点。当然其实之前微软也做了一些工作,比如说ZeRO的工作,我用的时候做一次通信把所有的东西都汇总起来了。ZeRO的做法是提前预先静态的把内存申请一下用来放参数,但是这种情况下很容易会造成一些内存的浪费。假定我们还有700G内存,刚好我需要750G,可能整个700G都会被浪费掉。能否利用Chunk分成很多块,只要有实际的空间给出一个实际的块,尽可能把越昂贵的内存每一块都利用起来。通过这样的方式,我们就能把内存的利用率提到最高,从而进一步降低内存的开销。最后,我简单介绍一下Benchmark以及实验结果。左边是跟GPT相比。一个GPU、两个GPU、四个GPU,ColossaI能够训练更大的模型。右侧的是跟DeepSpeed相比,比的是速度,最多大概能获得三倍的加速。这张图是不同解决方案的比较,左边从左到右是PyTorch、DeepSpeed,一个很低端的GPU情况下,最终ColossaI能够训练120亿参数的模型。右侧是一个速度的比较。这是我们帮客户做的一些解决方案,比如在同样的条件情况下,可以进一步把时间从大概每次的每个计算单元时间大幅度降低10倍左右。我就分享结束了,如果大家有问题的话,可以交流一下。 来源:知乎 www.zhihu.com 作者:尤洋 【知乎日报】千万用户的选择,做朋友圈里的新鲜事分享大牛。 点击下载
感谢 @知乎科技 邀请参加 AI 盐沙龙活动,下面是我讲述《大模型高效训练的关键技术》的现场实录。
大家下午好,荣幸参加贵乎的活动。我今天讲一下大模型训练的技术,我们做了一套大模型训练的工具,我觉得更偏下层一点,当然没有杨军老师那样更下层,介于编译器和大模型之间的那一层。
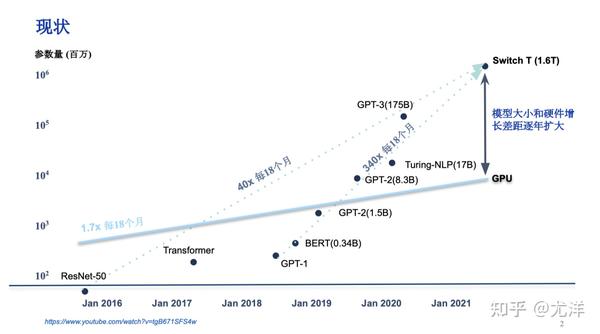
首先给大家展示一张图片,横坐标是时间,纵坐标是AI模型的参数量。从这张图片中可以看出,过去六年大模型的参数量上升了大概10万倍量级。因为2016年的时候,我们很清楚最好的大模型是ResNet50,只有2000多万的参数,到了2020年6月份GPT3出来了,当时是2000亿的参数,已经大了一万倍了,现在据说GPT4是MOE1.7万亿参数,又进一步增加了10倍。
我们知道从ResNet50到GPT4,可能不是深度学习了,是宽度学习更恰当一点。当然这是大模型的现状,它好的一点确实GPT4现在变得非常智能,但是不好的一点,我们也可以看一下互联网上数据,训练一下GPT4这个模型预算是6300万美元,这是OpenAI 的数据,站在学校的角度而言是很难做到的,需要工业界和学术界结合起来是比较现实的方案。这张图中还有一条线就是GPU的内存容量,可以看出每18个月上升1.7倍,上升速度没有英伟达的股价上升速度快,这也是一个现状。这也是为什么需要用成百上千的GPU训练大模型的根本原因。
这里列举了一些数字,现在已经更夸张了,之前训练GPT3的时候,我们用了V100,300万美金的价格,现在GPT4居然到了6000万美金的量级,整个成本变成了亟待解决和优化的问题了。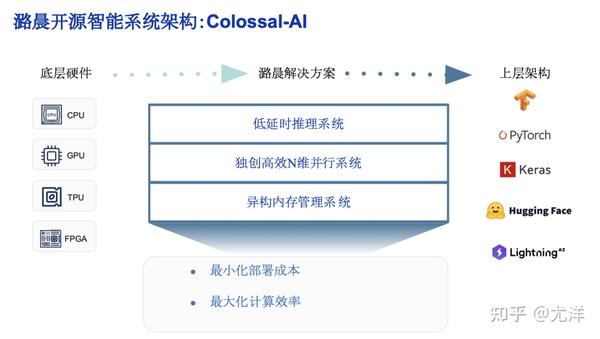
我介绍一下我个人做的事情,以及我做创业公司到底在干吗。一句话讲就是希望把大模型训练的成本能进一步降低,今年训练GPT3训练成本是300万美金,希望五年之后到七八万美金左右。我们设计了一个软件叫ColossaI,第一是异构的内存管理系统,大模型最大的挑战是内存开销太大了,假定我们是2000亿参数的话,即便用单精度存,2000亿就是800G内存,梯度也是800G内存,我们训练大模型都是800G内存,首先什么也没干已经需要3T的内存了,单个GPU只有80G或者100G。当然我们知道要存很多中间计算结果,包括输入数据越大的情况下,我们用传统的方式也是随着数据而增大的,内存变成了天文数字,所以优化内存是非常关键的地方。
我们独创的高效N维并行工作。李开复老师做了一家公司叫零一万物,因为OpenAI说自己用了10万张卡训练,他们的目标也是希望到那个量级,但是他们现在只用了200张卡。他们考虑的重要事情就是把200卡扩展到2万卡,能不能获得90倍的加速,或者能不能获得80倍的加速?因为现在用传统的方案去做的话,可能我从200卡到2万卡,虽然GPU速度增加了,但是效率只有20%、30%,从决策者的角度来看非常不值,我投资了这么多倍,只有30%的速度提升,我认为未来并行计算,分布式计算的空间优化还是很大的。由于是跨GPU和跨数据的优化,我们也在这层做了一些优化。
另外低延迟的推理系统。很荣幸智源悟道是我们公司第一个付费客户,两年前我们就是帮它优化GLM,因为模型越大之后,我们现在用GPT3或者GPT4,问一句话延迟还是很高的,低延迟的推理系统也是很重要的。这是目前ColossaI做的一些事情。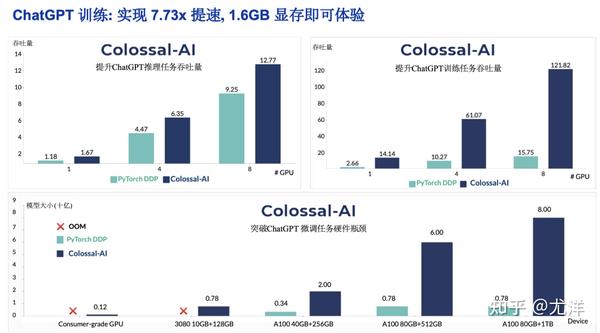
这里列举了一些实验的比较,主要跟最基础的基准比较,可以看出ColossaI可以快6到7倍,效率能是8倍大小的参数。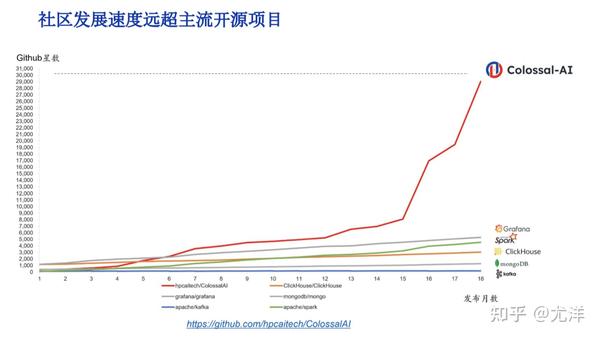
这里是ColossaI目前的社区发展情况,它的开源目前增长速度还是非常快的,已经超过了kafka、spark这些传统的软件,横坐标是时间,纵坐标是星数。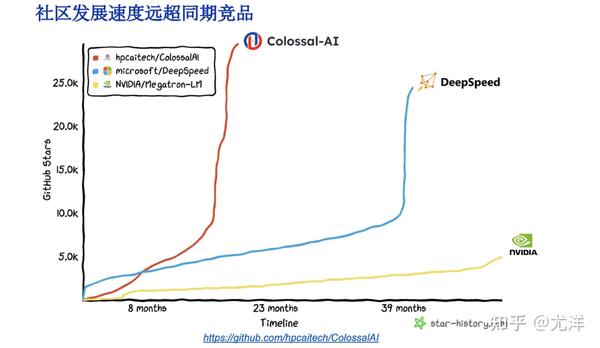
这是同赛道的软件比较,比如跟英伟达的Megatron-LM 和跟DeepSpeed相比。
ColossaI目前做的很多事情也是跟全球AI生态彻底绑定,全球的生态还是一体的,我觉得还是有很多相互交流的。目前这是生态的网页,可以看出现在第一个软件就是ColossaI,LightingAI全部用的ColossaI。我们知道目前第二大AI生态是HuggingFace。开源生态全球做的最好的就脸书,脸书OPT的模型也可以用ColossaI训练,这是跟全球AI生态的关系。
我们也跟一些厂商,比如HPE合作,因为它们在全球有很多最终为大模型买服务器的企业,比如车厂、药厂、石油公司,现在也内嵌了ColossaI的方案,这是它的产品官对ColossaI的点评,有很好的API,有显著的性能提升。
这是目前ColossaI的贡献者,也是遍布全球的。这是全球的ColossaI的用户,可以看出中国、美国、欧洲、东南亚都有很多的客户。
我就简单介绍一下干的事情。这里进入技术环节,主要是我们现在考虑假如训练一个千亿、万亿的大模型到底需要什么技术。这里简单探讨一下,大家有什么想法和看法可以随时交流。、
我们知道2020年GPT3刚出来的时候,最开始把训练方案公布出来的是英伟达,在英伟达PTC峰会上,黄总说了如何训练GPT3的,当时用了3072个GPU,用了三种模型,数据并行,流水线并行以及张量并行,出于通讯方面的考虑,张量并行到流水线并行需要做很多的考虑,需要涉及每一个GPU都要参与。英伟达的方案是首先在服务器内用张量并行,每个服务器有8个GPU,再把64个服务器分成一组做流水线并行,组之间用数据并行,这样是3072。现在我们明显看到一个趋势,就是刚才说的趋势,模型从ResNet50到GPT3大了一万倍,但是层数并没有增加,每层计算量变得更大的情况,张量并行可能发挥更大的作用。大家可以看一下脸书团队的一些方案,他们现在的一些方案其实直接把流水线并行删除了,他们发现当这个模型很宽的时候,张量并行的优化点还是很多的。当然我们也顺应潮流,也做了一些更高维度的张量并行,比如二维张量并行,2.5维张量并行。还有数据序列并行,大家看到新闻美国某些创业公司把输入长度扩展到100万个Token,肯定输入长度依旧是越长越好,我们回顾之前背景肯定是信息越多越好,但是序列非常长之后内存开销很大,所有词词两两之间都要算attention,所以我觉得数据序列并行也非常重要。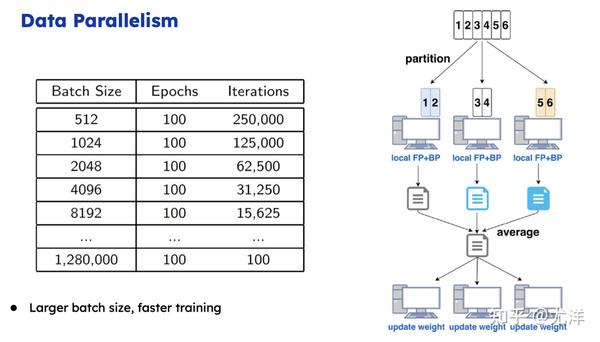
我简单介绍一下这些技术,首先回顾一下数据并行,最基本的训练AI大模型的方式。假如说batch能塞到GPU内存里面最好,这样服务器之间只需要梯度加过去就行了,这是最简单的方式。这种方式主要取决于我们能把通信操作优化得多好,假定能够优化好的话,下面就是如何把batch做大,因为每次循环都得进行一些梯度更新,我们如果能把batch扩大十倍,就线性减少它的更新次数,同时也会让每个GPU占用率、使用效率更高。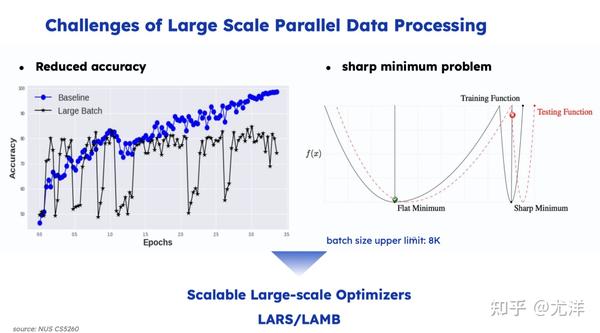
但是问题是我把batch 扩大无限大,更新次数无限小的时候,我们会是找一些局部自由点,这种情况下发现更难找出更好的局部自由点了,这里做一些数值优化的工作比较重要。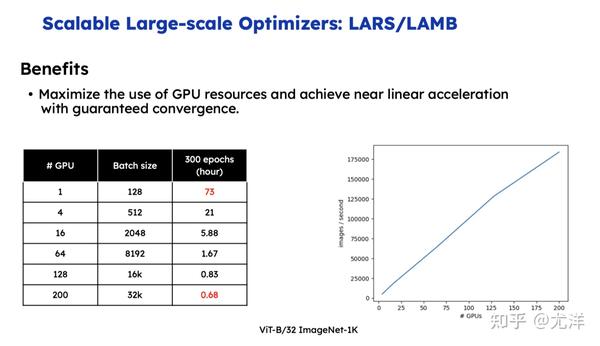
最近斯坦福的马腾宇老师也提了一个更高级的想法,这块未来的想法可能还有很多。不知道大家有没有听过美国有一家创业公司是做芯片的,理念是我把内存容量做到2T,A100的只有80G内存,但是它自己的宣传稿中,我没有验证,它说可以把内存做到2T,这种情况下有望把千亿参数直接塞到内存里。数据并行之前已经优化的很好了,进一步如何再把batch size 提升,把更新次数降低。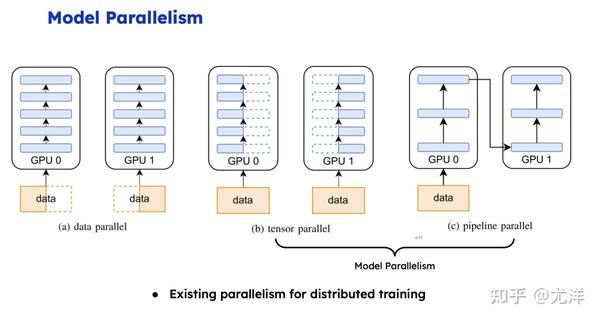
说完数据并行,再说一下Model Parallelism。我做神经网络训练像盖楼一样,我算完第一层才能算第二层,算完第二层才能算第三层。我们现在既然楼很宽,假定这个楼有1万平,我有十个工程队,每个工程队分了1000平,大家干完之后做一次全局的同步,然后全局通信就进入下一层。真的挺简单的。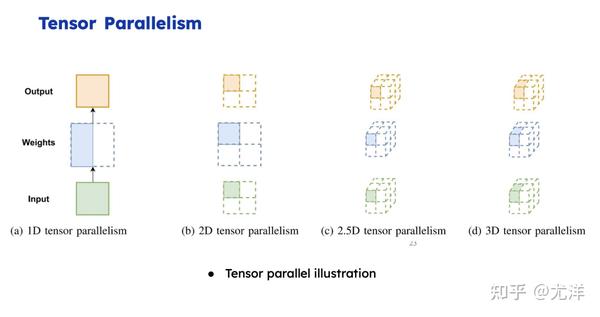
但是它的通信开销还是非常大,英伟达Megatron方案还是做了精心的设计。未来有必要做一些二维张量并行,因为本身都是矩阵,像传统的二维矩阵层的核心思想,就是我把GPU或者服务器按行或者按列分成网格状,每个机器只用跟同列机器打交道,本来有一万个机器,理论上跟9999个机器打交道,但是二维的方式每次只需要跟99个机器打交道就可以了,可以大幅降低通信的代价。这是二维张量并行的核心思想。三维的也是分成10×10×10的网格状,或者分成100×100×100的立体状,每次只需要跟同维度的打交道就可以了。这是二维和三维的核心思想。2.5维是介于二维和三维之间的中间状态。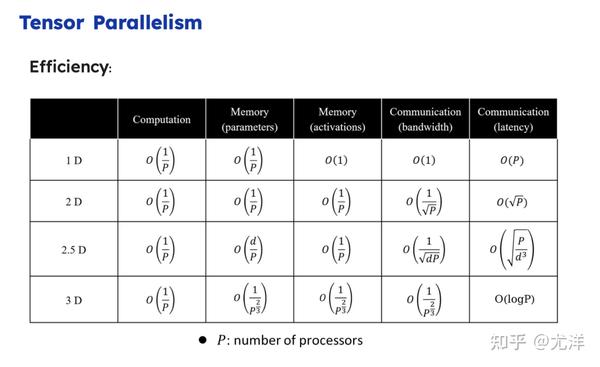
这里快速过一下通信复杂度,大家也没必要记得太认真,这种东西肯定是一些理论上的分析,具体还要实践验证。最后两列可以看出二维和三维的通信复杂度肯定是远低于一维的。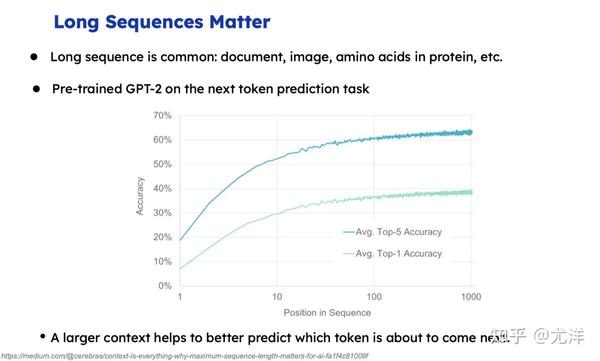
我重点介绍一下数据序列并行。这里首先跟大家展示一张图,横坐标是到底有多长,纵坐标是预测下一个词的精度,肯定越长预测的越准确。回顾的越多信息越多,预测的肯定越准确。这是一些实验的结果图。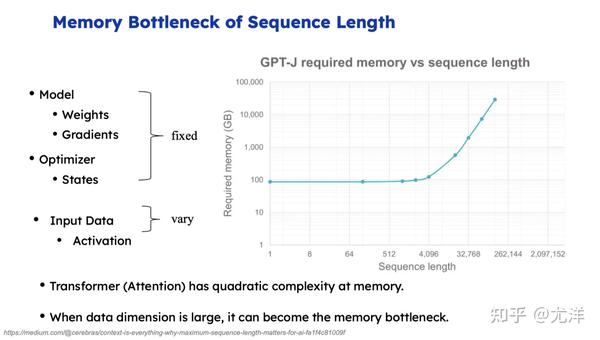
我给大家看一张图,超过4K之后,它的内存开销在指数级的上升。现在有一个创始公司居然把sequence 做到了100万,它的核心思想就是把不同的Token块放到不同的GPU上,我有一百万个Token,可否十个GPU每个放10万个Token,这样每个计算单元的内存压力小很多。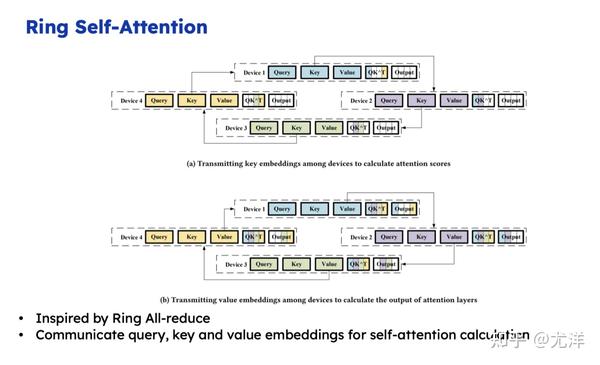
但是它的问题是 attention 架构里 token两两之间都需要做信息交换的,比如说今天咱们屋子有100个人,每个人都拿了一包很大的零食,现在要干的事情就是让所有的人尝下手里的零食,所有人之间都需要交互一下。优化点就是能不能基于传统的Allerduce的方法,我们拉一个圈,右手边的同学尝试一下,然后左手边的同学尝一下,传99次就所有人都可以吃到所有人的零食了。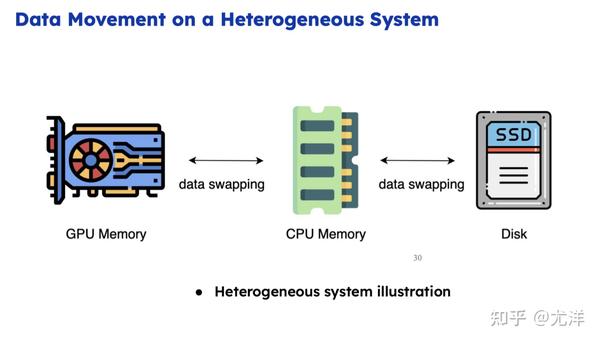
我再介绍一下内存优化方面的工作。既然训练大模型这么耗内存,现在很重要的问题是我们能否利用一下CPU内存。假如盖大楼需要很多材料,材料和原料都放到楼下工地,楼下工地放不下能不能放到隔壁工厂?隔壁工厂也放不下能否放到天津?但是如果我每拿一次都去隔壁工厂,肯定消耗更大,我盖一层楼都去天津拿一下,显然盖楼的时间还没有拿材料的时间长。我用CPU内存就是通信开销太大了,计算的速度肯定远快于CPU跟GPU之间的通信。这个其实就是优化的重点。
当然其实之前微软也做了一些工作,比如说ZeRO的工作,我用的时候做一次通信把所有的东西都汇总起来了。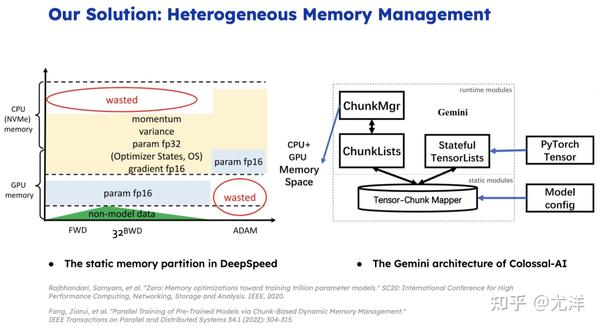
ZeRO的做法是提前预先静态的把内存申请一下用来放参数,但是这种情况下很容易会造成一些内存的浪费。假定我们还有700G内存,刚好我需要750G,可能整个700G都会被浪费掉。能否利用Chunk分成很多块,只要有实际的空间给出一个实际的块,尽可能把越昂贵的内存每一块都利用起来。通过这样的方式,我们就能把内存的利用率提到最高,从而进一步降低内存的开销。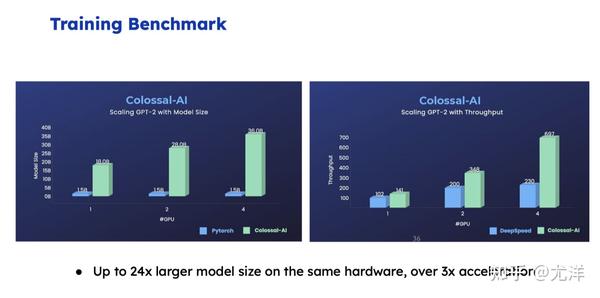
最后,我简单介绍一下Benchmark以及实验结果。左边是跟GPT相比。一个GPU、两个GPU、四个GPU,ColossaI能够训练更大的模型。右侧的是跟DeepSpeed相比,比的是速度,最多大概能获得三倍的加速。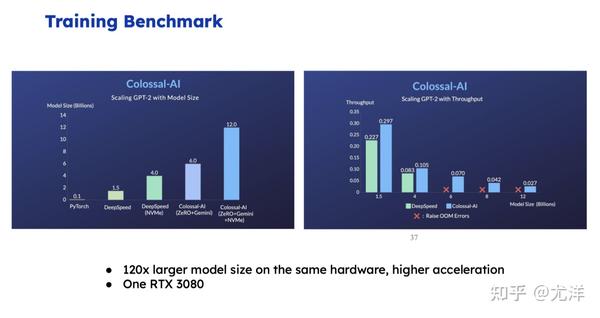
这张图是不同解决方案的比较,左边从左到右是PyTorch、DeepSpeed,一个很低端的GPU情况下,最终ColossaI能够训练120亿参数的模型。右侧是一个速度的比较。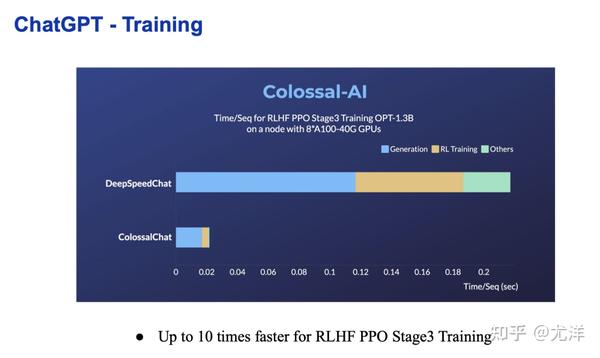
这是我们帮客户做的一些解决方案,比如在同样的条件情况下,可以进一步把时间从大概每次的每个计算单元时间大幅度降低10倍左右。
我就分享结束了,如果大家有问题的话,可以交流一下。
来源:知乎 www.zhihu.com
作者:尤洋
【知乎日报】千万用户的选择,做朋友圈里的新鲜事分享大牛。
点击下载